由斯坦福大學人工智能百年研究(AI100)推出的「人工智能指數」(AI Index)是一個追踪人工智能行業動態與發展的非營利性項目,其研究覆蓋了百年以來人工智能的總體情況, 目標是 基於數據來推動人工智能的廣泛交流和有效對話。 2017 年,AI Index 推出了首份年度報告,從多個角度觀察和解讀了人工智能領域的動態和進展。

1.論文發表數量
下圖統計了 Scopus 學術論文庫中標註關鍵詞「人工智能」的計算科學論文數量。
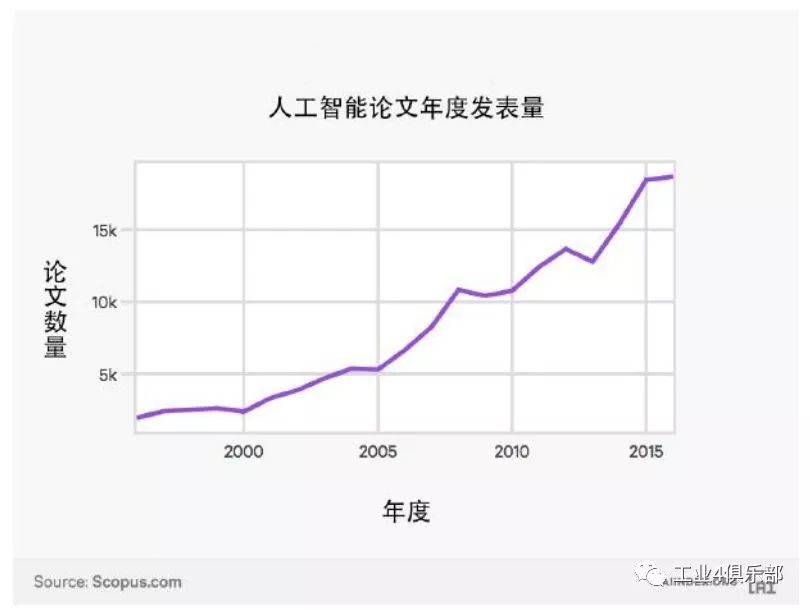
自 1996 年至今,每年發布的 人工智能論文數量增加了 9 倍多。
這裡是各類學術論文年發表率與其 1996 年發表率的比較。 圖表顯示了各領域論文、 計算機科學領域論文以及計算機領域內人工智能論文年發表率的增速。
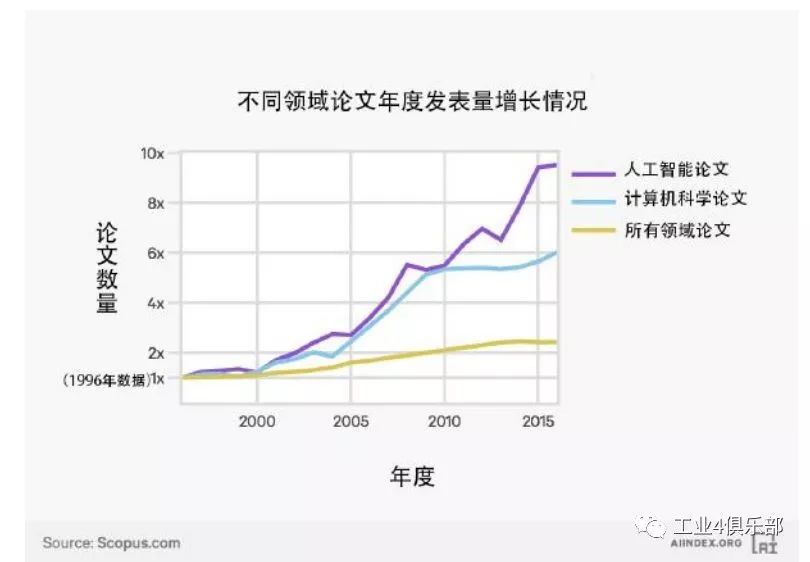
數據揭示了人工智能論文發表率的增長不僅僅是出於對更廣泛計算機科學領域興趣的 增長。 具體來說,儘管自 1996 年以來整體計算機科學領域內的論文數量已經增長了 6 倍,同時期人工智能領域每年發表的論文數量已經增長了 9 倍多。
2.課程選修人數
除了論文發表數以外,課程的參與人數也能體現這個領域的活力。 以下展示的是斯坦 福大學每年選修人工智能與機器學習導論課程的學生數量。 機器學習是人工智能的子領域。 我們著重關注機器學習導論課程的參與度是因為目前人工 智能領域很多成果都基於機器學習的算法與理論。
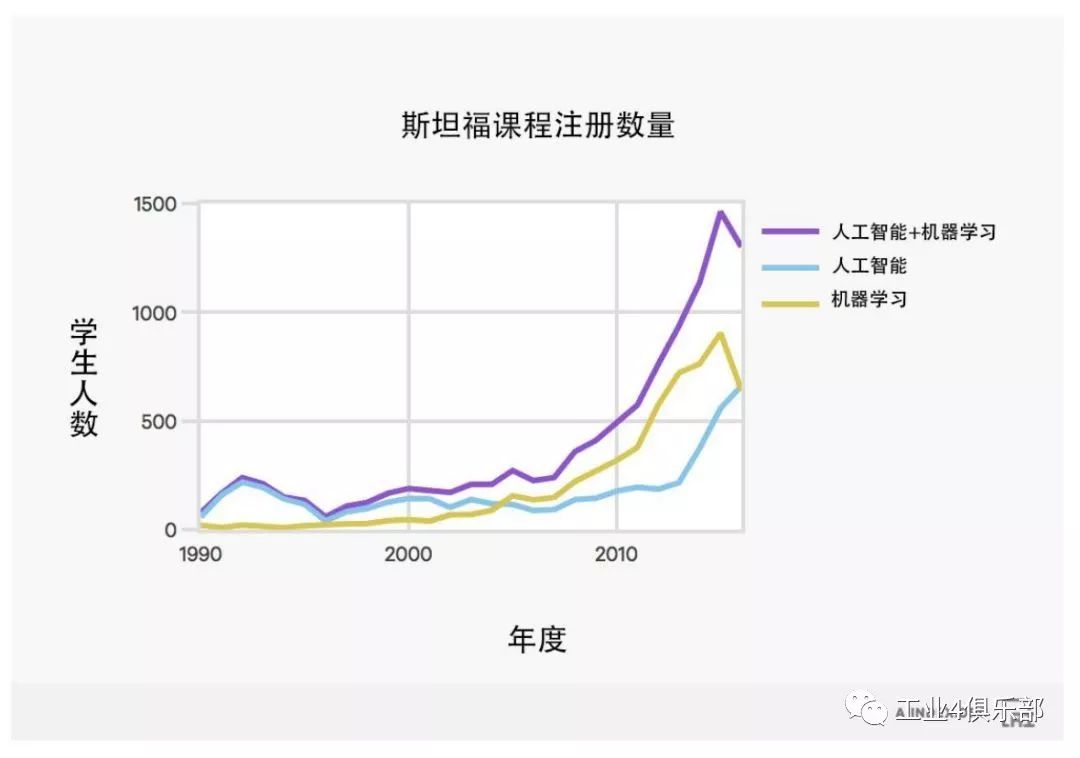
自 1996 年以來,選修斯坦福大學人工智能導論課程的人數已經增長了 11 倍。
注:斯坦福大學 2016 學年機器學習入學人數的下降是基於當年的行政問題而非學生興趣。
本報告之所以著重突出斯坦福大學導論課程的選修人數是因為其數據最全面。 不過如下所示,其它高校導論課程的選修趨勢也與斯坦福相似。
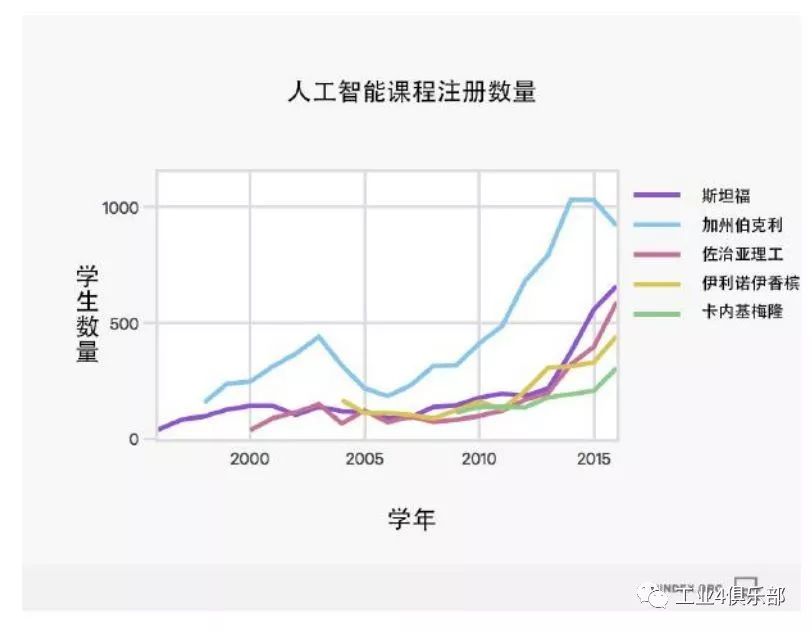
注:許多大學從上世紀 90 年代起開設人工智能課程。 上圖展示的是可獲取數據的年份的情況。
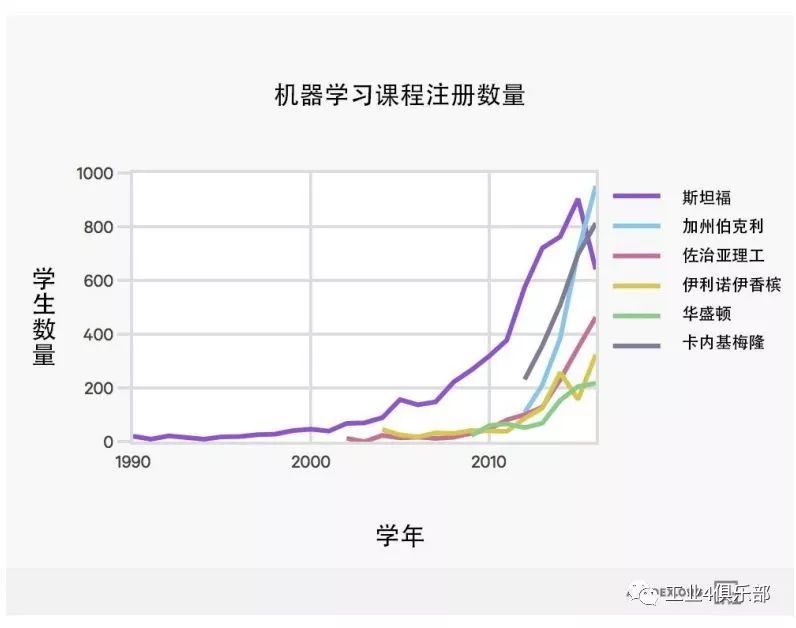
注:許多大學從上世紀 90 年代起開設機器學習課程。 上圖展示的是可獲取數據的年份的情況。
需要注意的是,這些圖表展示了高等教育領域中的一個側面,這些數據並不一定代表 學術機構總體的發展趨勢。
3.學術會議出席情況
以下展示了人工智能領域有代表性的學術會議的參會情況,其中既有如AAAI、IJCAI 和ICML 這樣的大型綜合性會議(按2016 年參會人數超過1000 人為標準),也有像CVPR、ACL、 ICRA 那樣專注於計算機視覺、自然語言處理和機器人的小型會議(2016 年參會人數不足1000 人)。
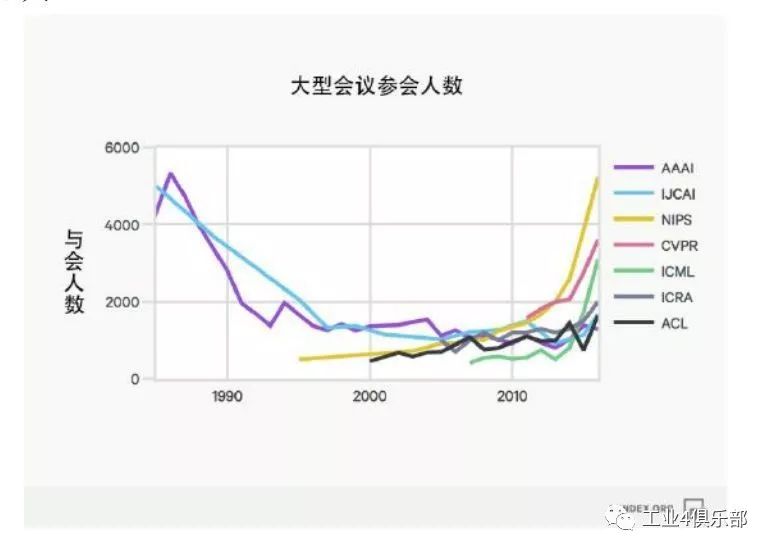
注:大多數學術會議自 1980 年代起即開始舉辦,上圖展示的是參會人數有記錄的年份的情況。
研究重心轉移:上圖的參會人數同樣表明了研究重點已經從符號推理轉向了機器學習與深 度學習。
下圖展示了參會人數少於1000 人的小型學術會議的參會情況,其中需要注意的是ICLR,該會議專注於深度學習領域,第一次會議於2013 年由深度學習先驅Yann LeCun 及Yoshua Bengio 主辦。
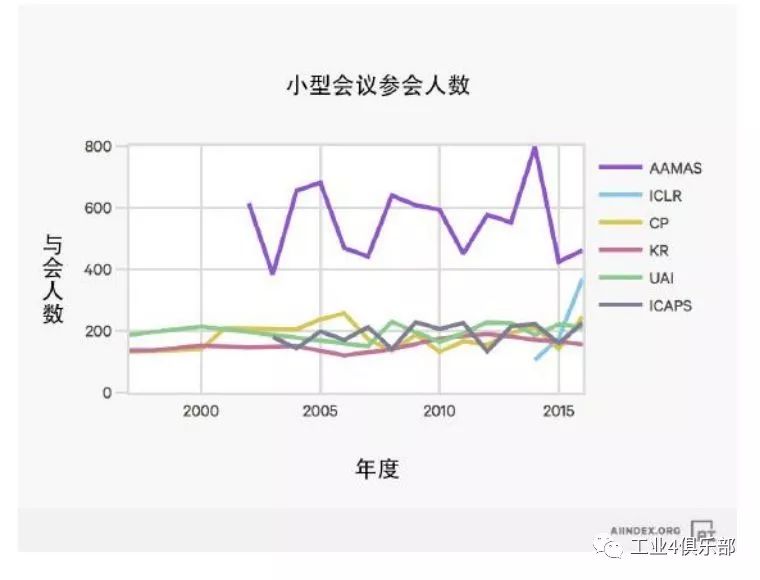
穩步前進:儘管學術界研究重點近年來已轉移至機器學習及深度學習,仍有一小部分 研究者繼續在符號推理方法上進行探索並取得進展。
產業領域
1.AI 領域創業公司
下圖展示了得到風投資本支持並開發了人工智能係統的美國活躍創業公司的數量。
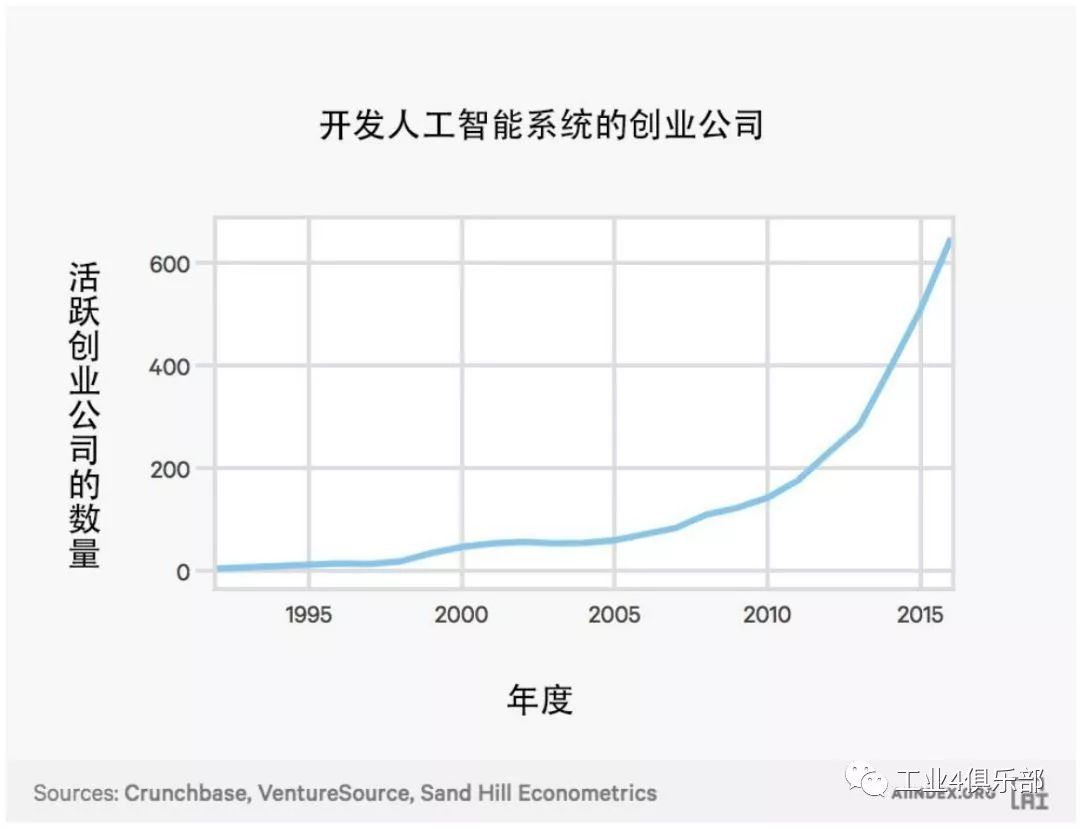
這一數量自 2000 年以來已增加了 14 倍。
2.AI 領域風險投資
下圖為風投資本對美國人工智能創業公司所有融資階段的年投資總額。
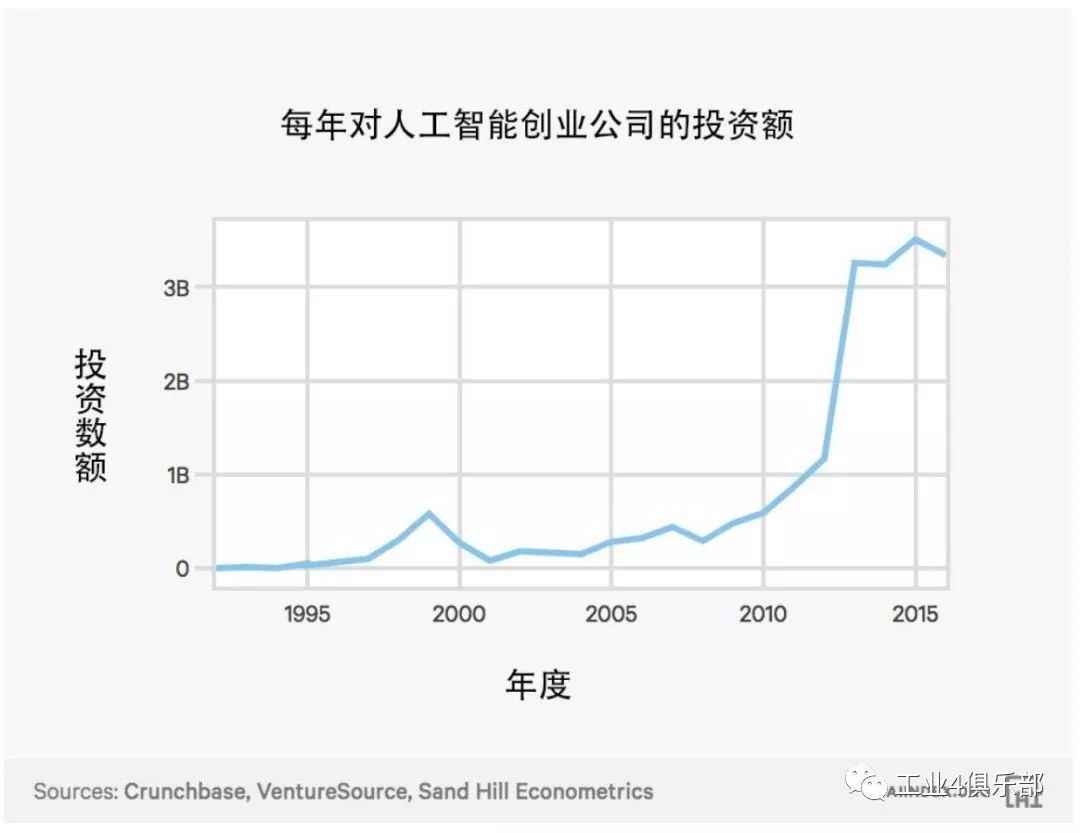
這一金額自 2000 年以來增加了 6 倍。
3.工作機會
下圖分別展示了需要人工智能技能的工作數量的增 長。 我們通過標題和工作描述的關鍵詞區分出需要人工智能技能的工作。
下圖是美國需要人工智能技能的工作數量的增長數據。 漲幅是基於 美國要求人工智能技能的就業崗位所佔份額的增長倍數。
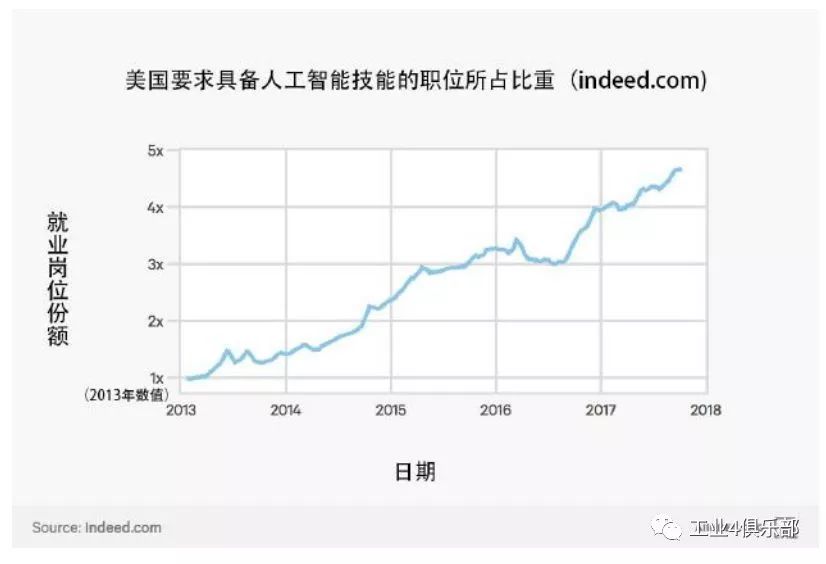
自 2013 年以來,在美國需要人工智能技能的工作比重增長了 4.5 倍。
下圖為多個國家需要人工智能技能的工作比重的增長趨勢。
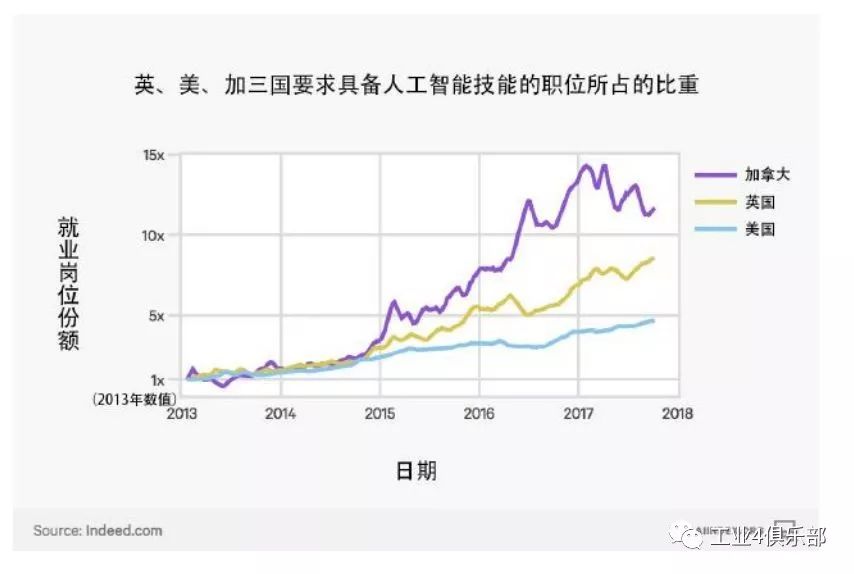
注:雖然在加拿大和英國 人工智能就業市場增長很快,但相對來說它們在 絕對規模上仍然只有美國 AI 就業市場的 5% 和 27%。
下圖為按照所需的特定技能劃分的一年內人工智能工作機會總量。
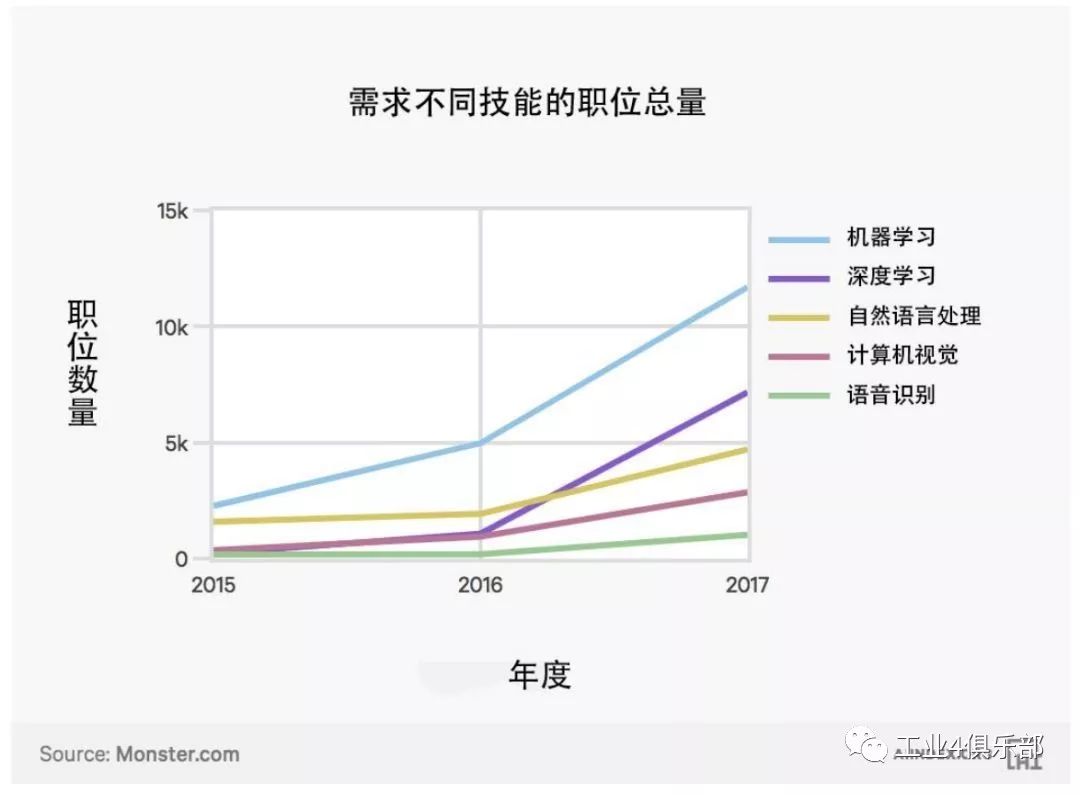
注:一份與人工智能相關的工作可能出現被計算兩次的情況 (屬於不同的類別)。 比如,一份工作可能尤其需要自然語言處理和計算機視覺兩種技能。
4.自動化及機器人應用
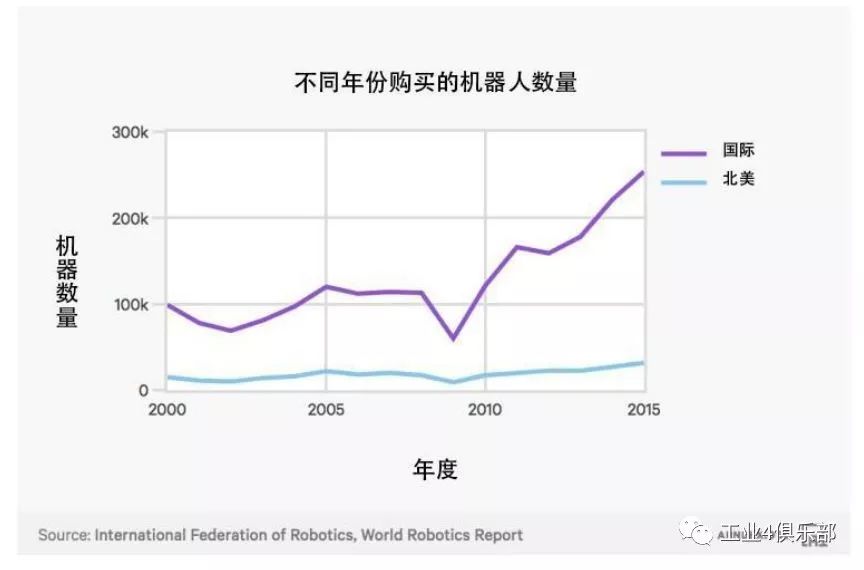
工業機器人進口到北美和全球的數量。
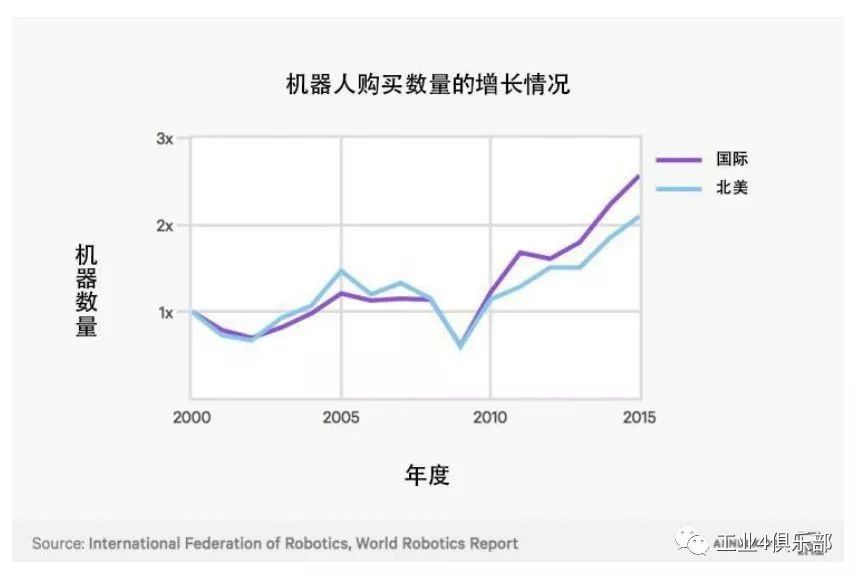
工業機器人進口到北美和全球的數量增長趨勢。
開源生態
1.GitHub 項目統計
下圖展示了 GitHub 上 TensorFlow 和 Scikit-Learn 軟件包被收藏 (star) 的次數。 二者都是深度學習和機器學習的常用軟件包。
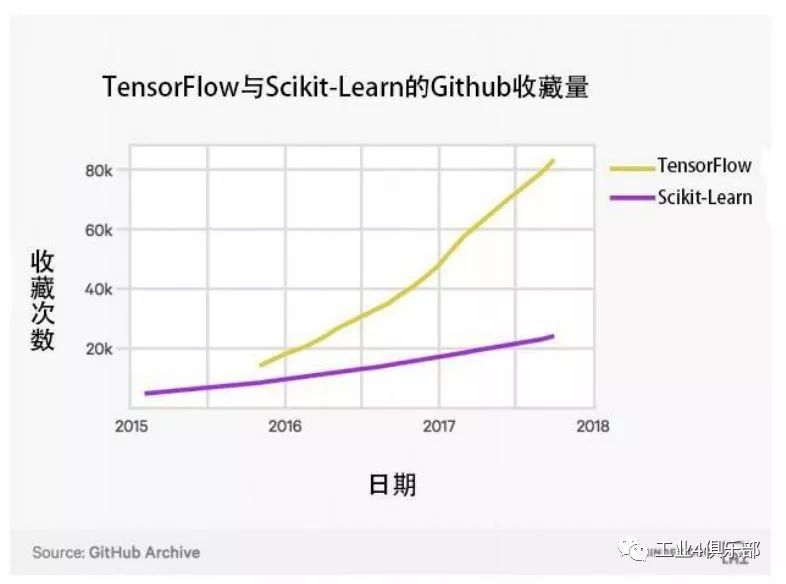
軟件開發者在 GitHub 上收藏 (Star) 軟件項目以表示感興趣並希望快速導航至該項目。 收藏 可以代表開發者對軟件和軟件使用的興趣。
下圖展示了 GitHub 上不同人工智能和機器學習軟件包被收藏的次數。
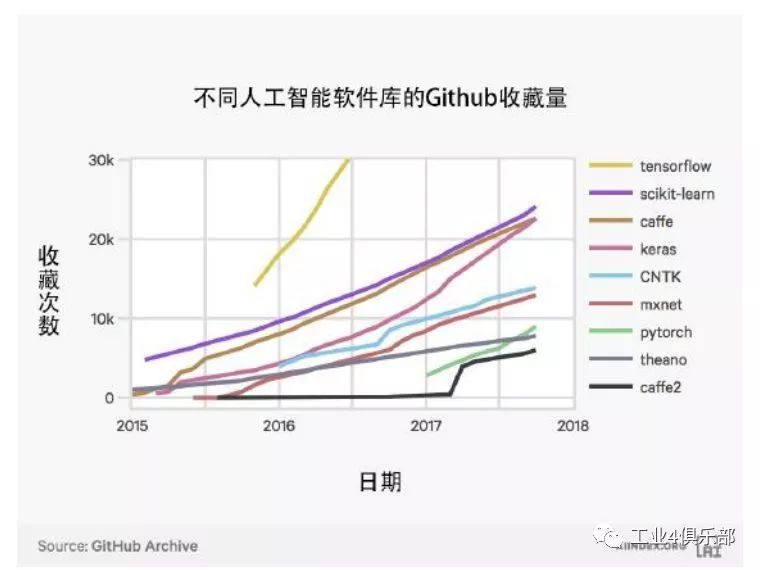
注:GitHub 庫的 fork 數量遵循幾乎同樣的趨勢 (儘管每個庫的 fork 量和 star 量不同)。
公眾認知及媒體報導
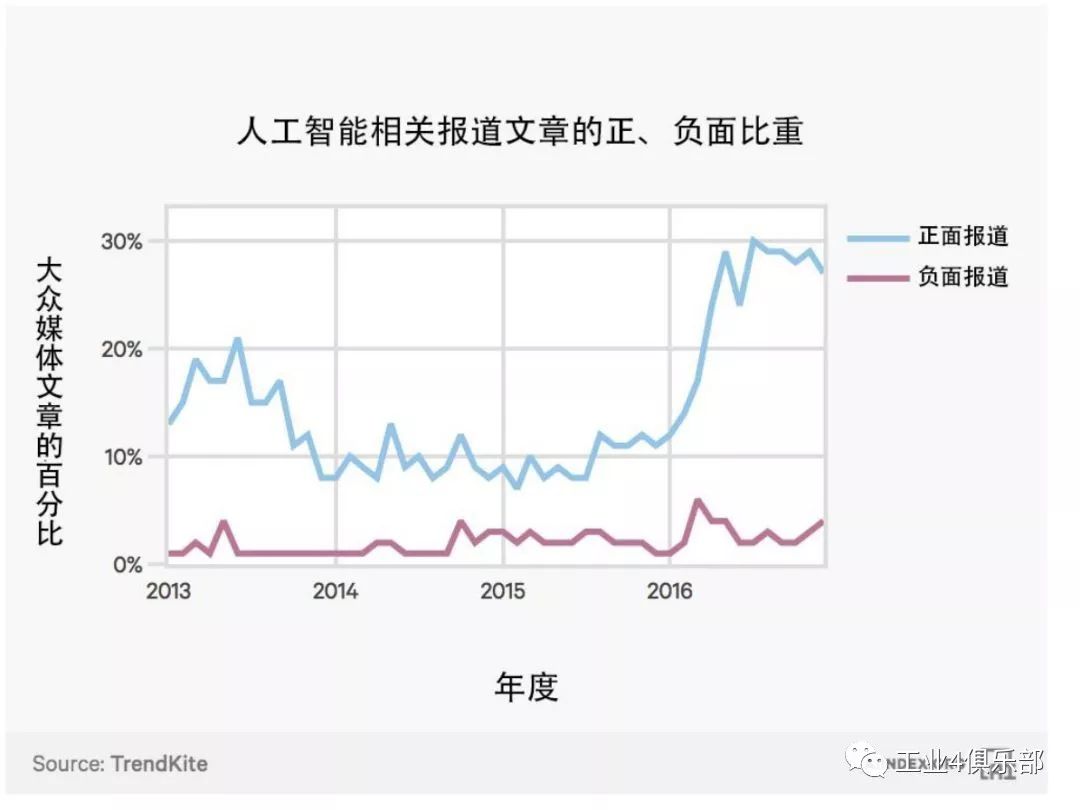
1.輿論傾向
下圖展示了包含關鍵詞「人工智能」的大眾媒體文章的百分比,文章根據其意見傾向性 被分為正面報導或負面報導。
技術性能
計算機視覺
1.物體檢測
下圖展示了 LSVRC 競賽 (Large Scale Visual Recognition Challenge) 中人工智能係統在物體檢 測任務上的性能表現。
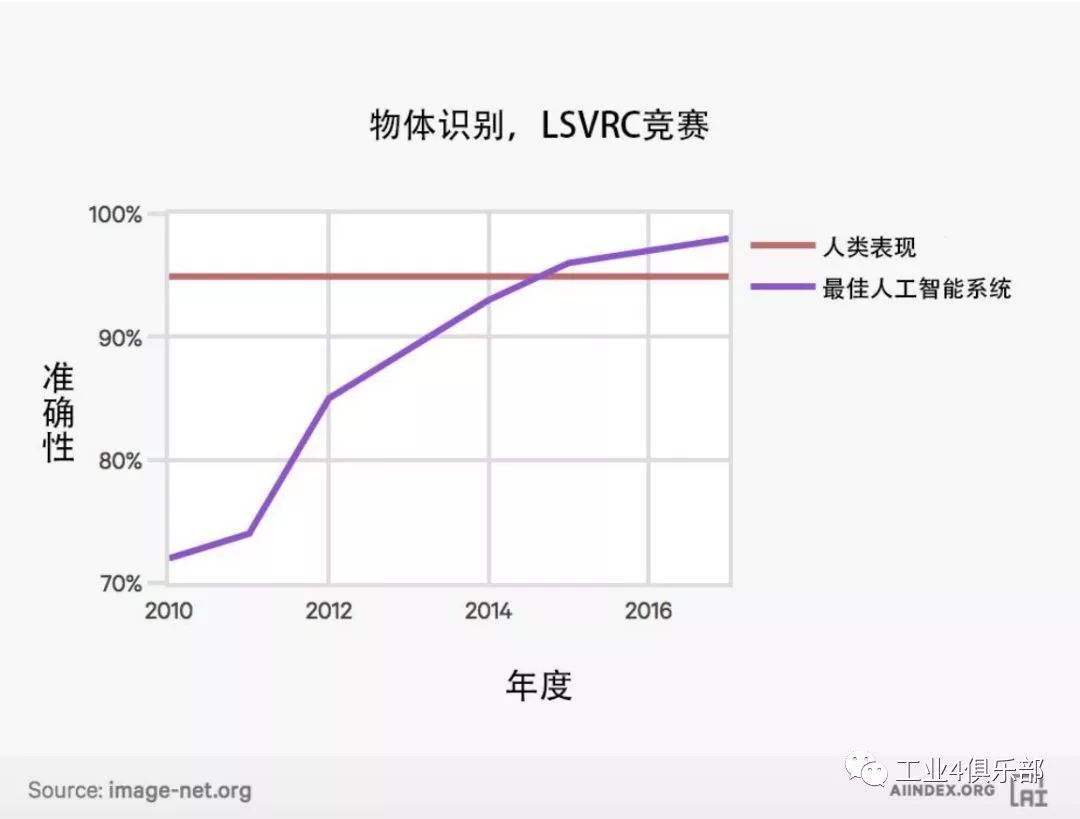
圖像標註的誤差率從 2010 年的 28.5% 降至低於 2.5%。
2.視覺問答
下圖展示了人工智能係統在針對圖像問題提供開放式回答任務上的表現。
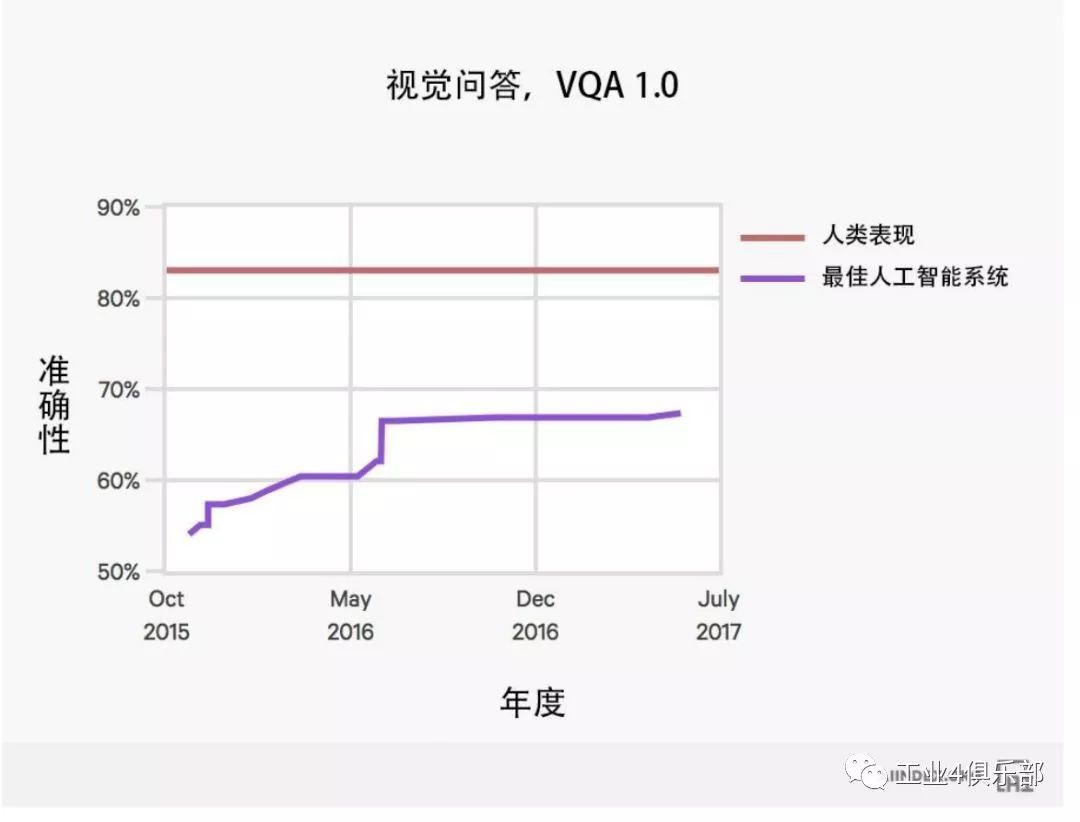
注:VQA 1.0 數據集已經被 VQA 2.0 數據集超越,目前尚不明確 VQA 1.0 數據集在未來會 獲得多少關注。
自然語言處理
1.解析
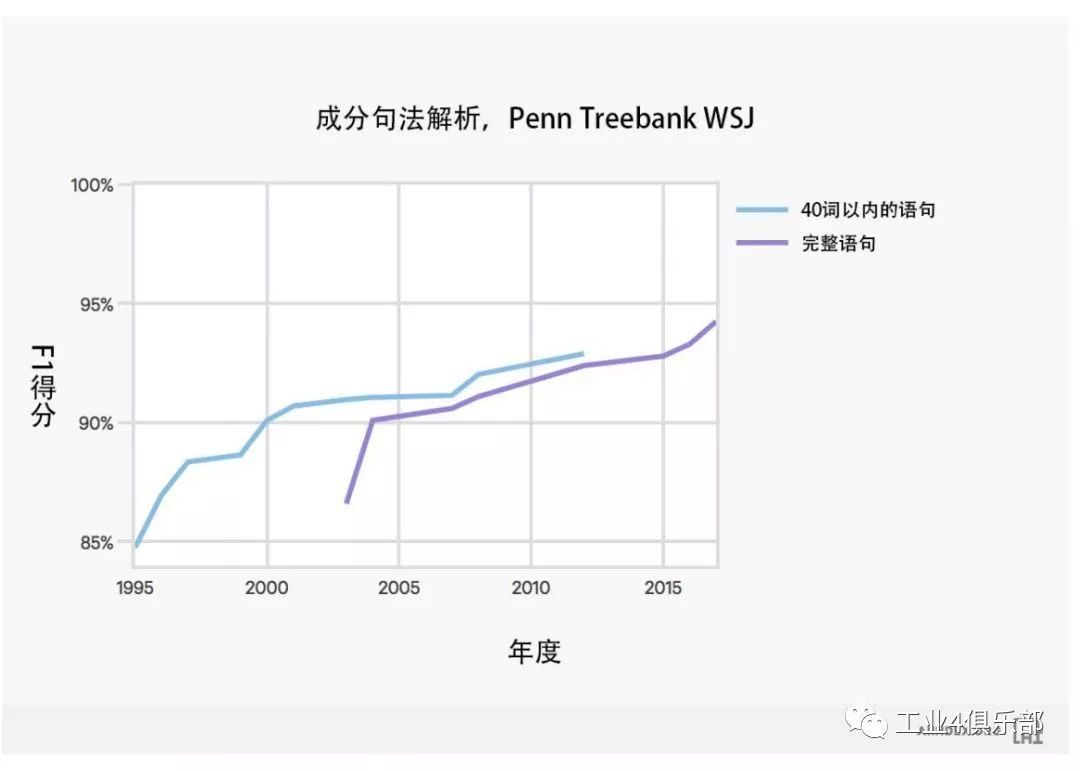
下圖展示了人工智能係統在確定句子句法結構任務上的表現。
2.機器翻譯
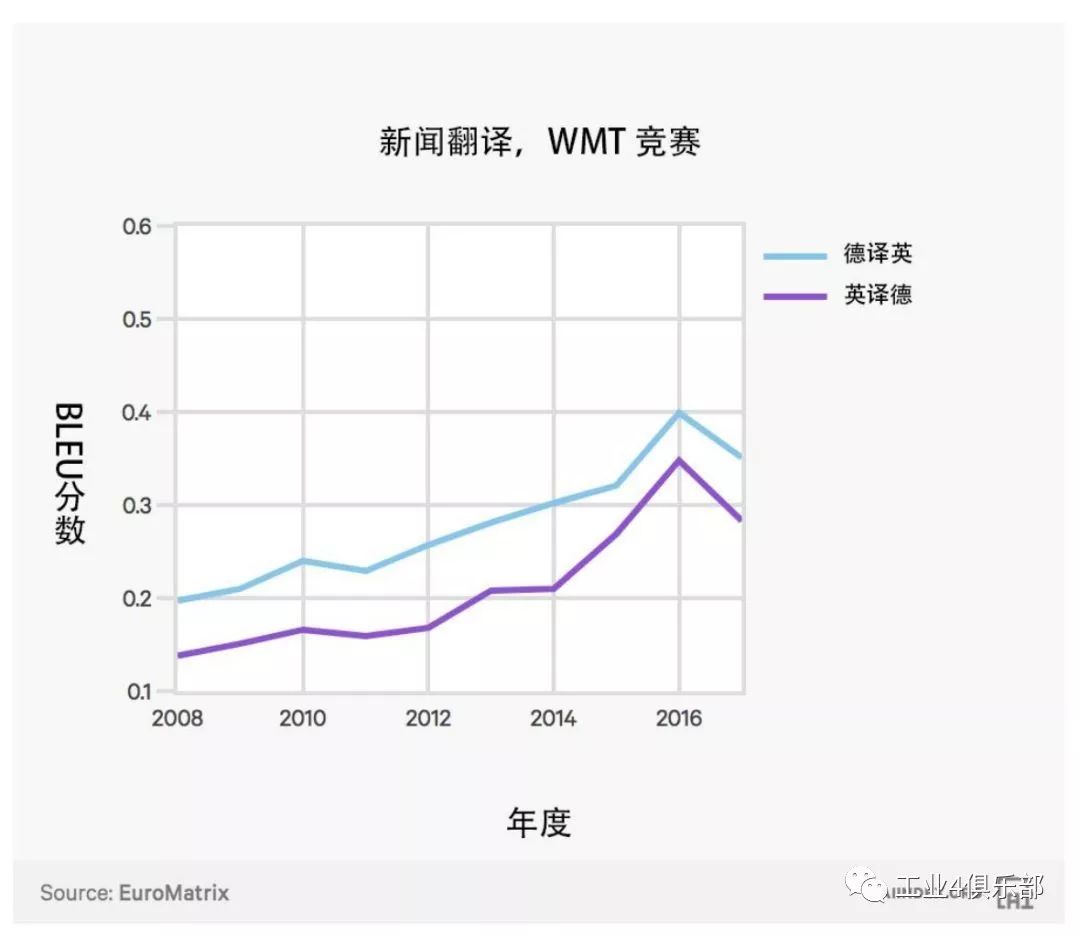
下圖展示了人工智能係統在英德新聞互譯任務中的表現。
3.問答
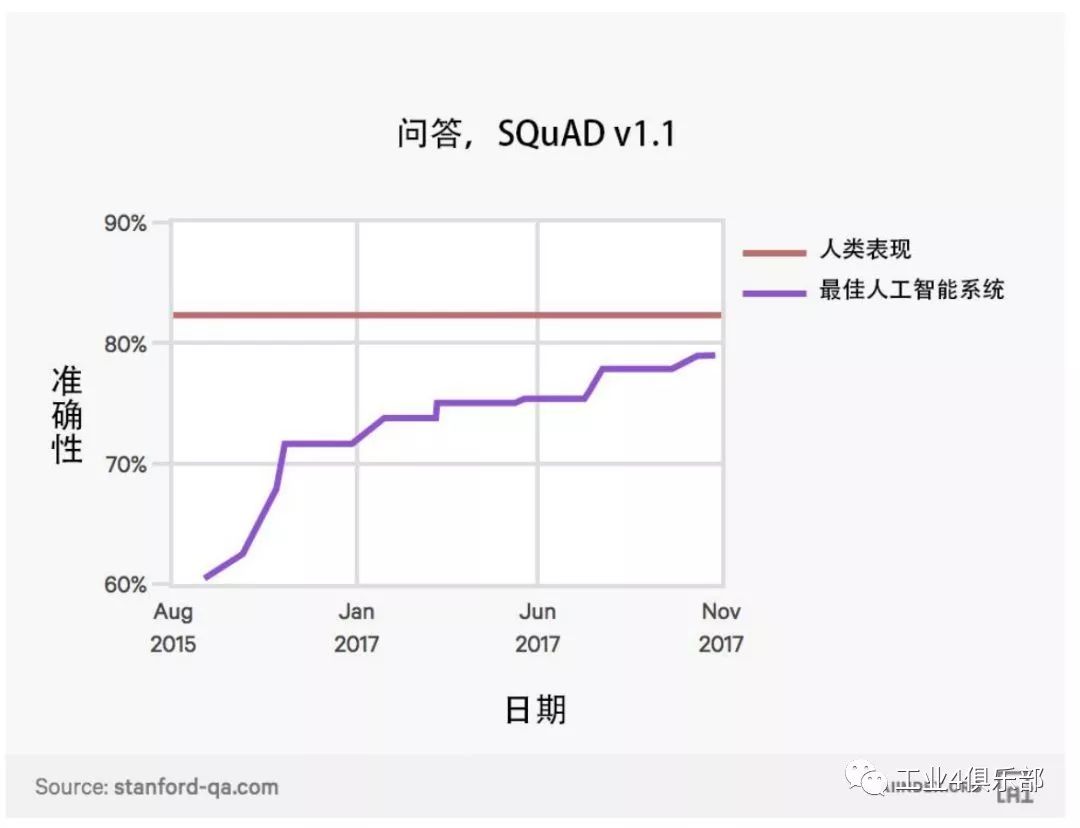
下圖展示了人工智能係統在從文檔中找到問題答案任務上的表現。
4.語音識別
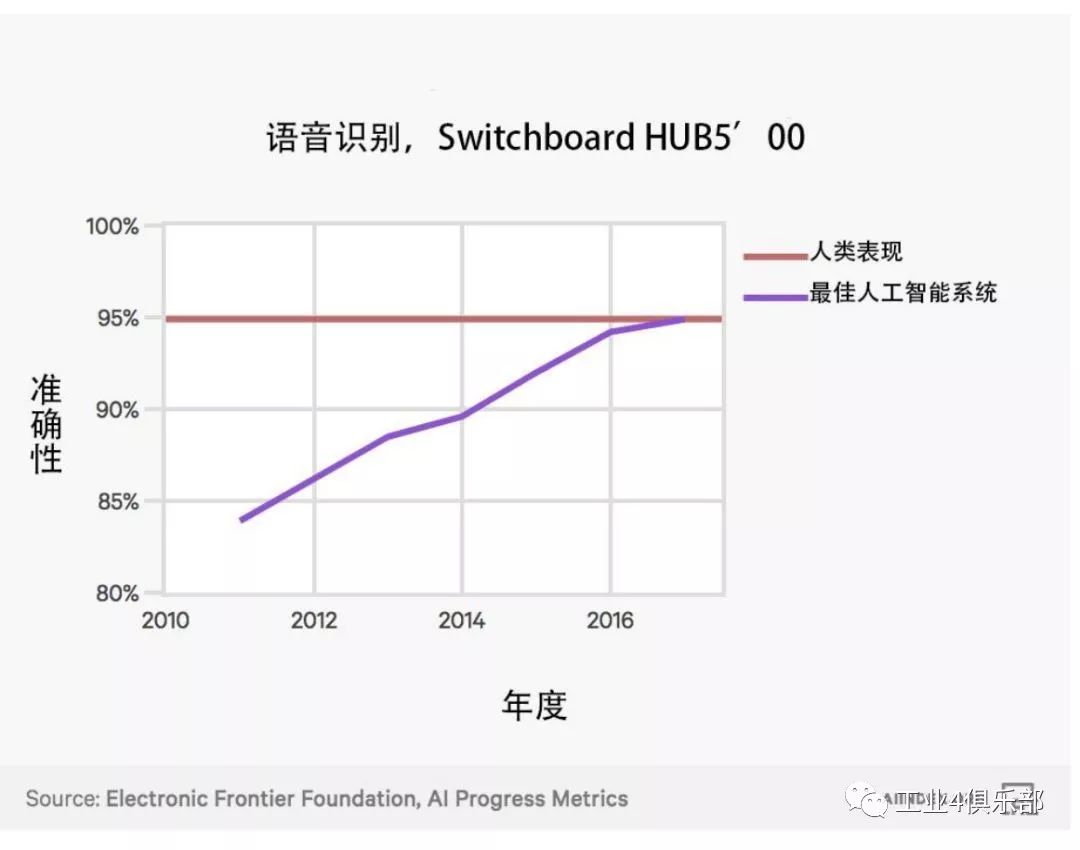
下圖展示了人工智能係統在語音識別上的表現。
定理證明
可處理度 (tractability) 是指自動定理證明器在大量定理的數據集上的平均可處理程度。 它可 以被用來衡量部分最先進的自動定理證明器。
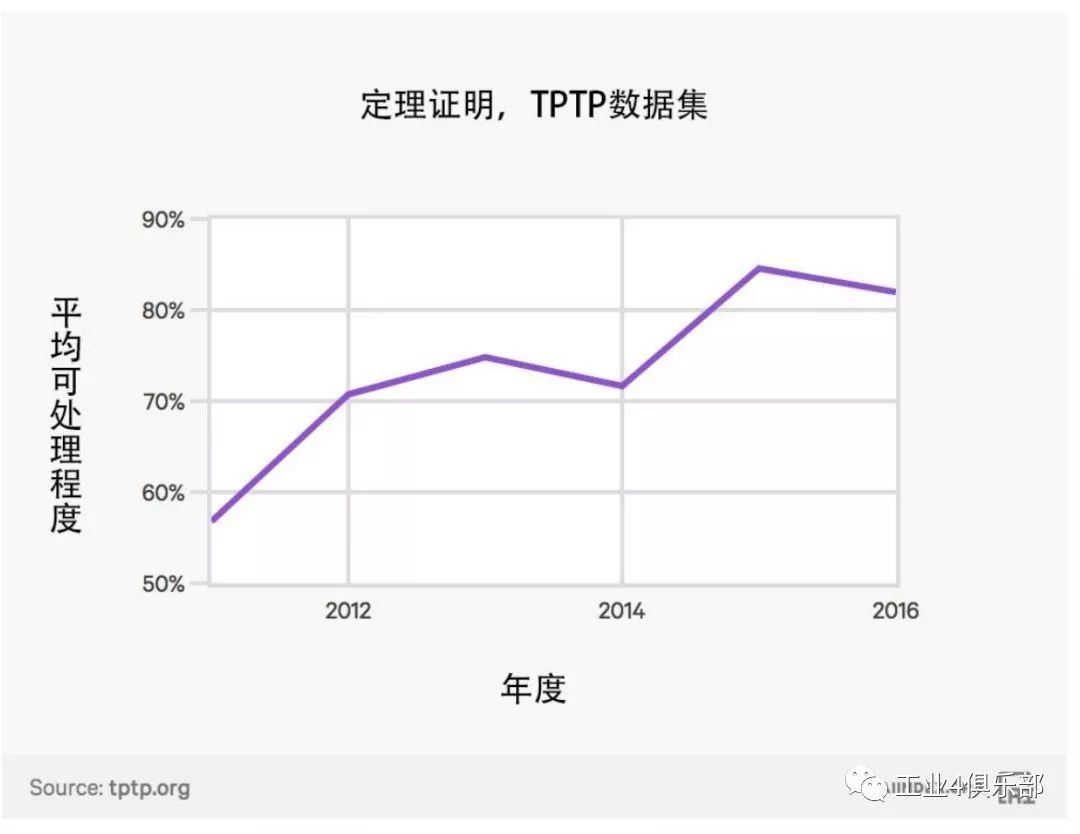
注:引進最先進的證明器雖然可以解決新問題,但由於其在處理其他證明器擅長解決的問題上表現糟糕,平均可處理度可能會下降。
SAT 求解
這裡指的是 SAT 求解系統解決問題 (那些可應用到產業實踐中的問題) 的百分比。
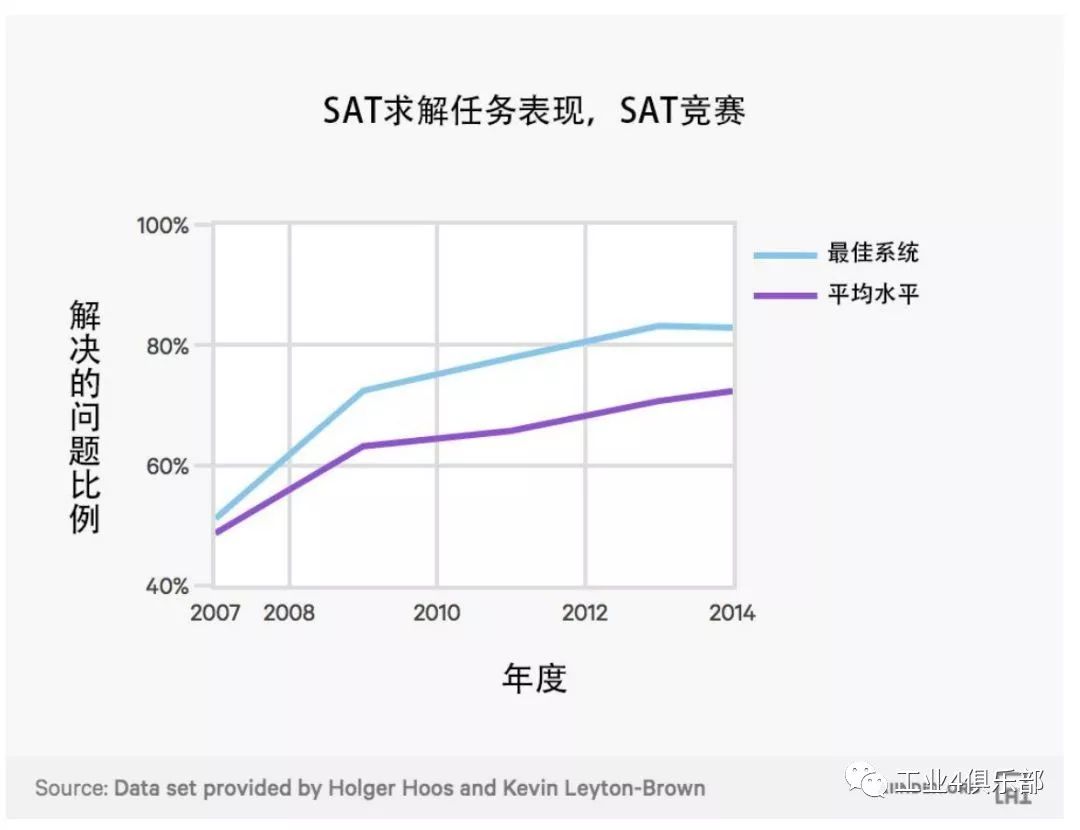
流行趨勢關係研究
通過研究不同流行趨勢之間的關係,我們可以從前述章節中的評估中獲得進一步的領 悟。 本章展示了人工智能指數收集的數據可以如何被應用到進一步的分析中,以及這些數 據如何推動了一個全新、精確的衡量指標的發展。
由於這是一個案例研究板塊,我們會著眼於橫跨學術圈與產業界的流行趨勢去探究其 之間的動態關係。 進一步,我們會將這些標準整合成一個聯合的人工智能活力指數。
學術界-產業界的動態關係
為了研究學術界與產業界人工智能相關活動的關係,我們首先從之前章節中選擇了部 分具有代表性的評估結果。 特別地,我們考察了人工智能論文的發布情況與斯坦福大學人 工智能與機器學習導論課程的修讀情況,此外還考察了風投資本對人工智能創業公司的投 資情況。
論文發表數、註冊學生數和投資金額這些數量指標並不能直接比較。 為了分析這些趨 勢之間的關係,我們首先以 2000 年為起始為每個測量指標設定了時間標準。 這使得我們 可以來比較這些指標隨時間的增長情況變化,而不是僅僅從最後的絕對值入手分析。
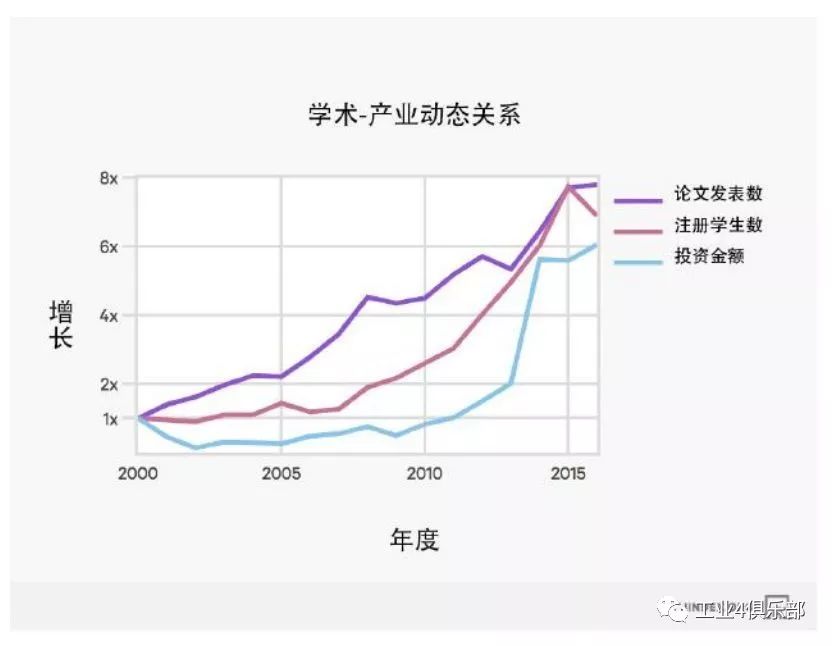
注:註冊學生數在 2016 年有所下降,這反映了學校行政上的某些問題,並非沒有足夠的學生對課程感興趣。
數據顯示,首先,學術活動數量 (論文發表與註冊學生數) 在穩步上升。 在 2010 年 左右,投資者便開始注意到了這個領域,到 2013 年,投資者已經成為了推進該領域發展 的核心驅動力。 此後,學術界逐漸趕上了產業界的步伐。
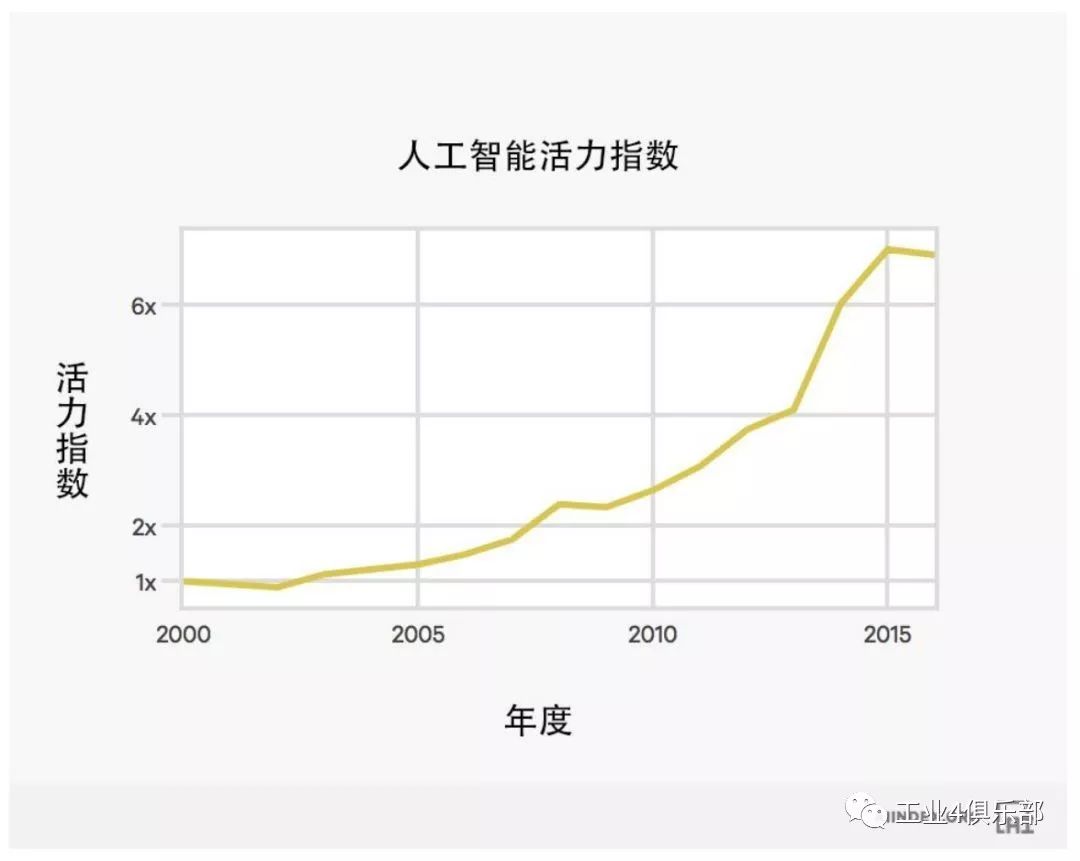
人工智能活力指數
人工智能活力指數整合了來自學術界和產業界的各類數據 (論文發表量、課程註冊學 生數、風險資本投資) 來量化整個人工智能領域的活力。 為了計算人工智能活力指數,我 們按照時間對來自論文發表、學生課程註冊和投資領域的數據進行了歸一化平均處理。