譯者註:本文以歐洲近期備受關注和爭議的“鏈接稅”立法動態為切入點,分析了為何傳統思維指導下的互聯網規制措施往往是無效的,甚至適得其反。 作者認為,嚴厲的規制措施會給互聯網行業造成高額成本,只有大型企業能夠負擔,因此反而會強化後者的壟斷地位。 接著,作者分析了新聞出版在互聯網時代的新特徵:信息富餘導致的買方市場,指出有效規制也應當順應互聯網發展趨勢,從利用需求側入手。 作者認為,通過要求互聯網公司提高透明度,能夠提高用戶的權利意識、促進其積極行動,由此造成的公關壓力將有效迫使互聯網公司做出改變。
今年夏天早些時候,整個互聯網行業都舒了一口氣:歐洲議會投票否決了一則新的《版權指令》(Copyright Directive)。 該指令要求互聯網網站主動過濾用戶上傳內容中侵犯版權的內容(所謂的“表情包禁令(meme ban)”);且在鏈接到其他網站、並引用其任何文本前,必須先獲得許可(“鏈接 稅(link tax)”)。
可惜,這是一次短命的勝利。 根據 EUbusiness 的報導:
根據歐洲議會周三批准的《版權指令》草案修正案,包括 Google 和 Facebook 在內的互聯網科技巨頭可能被要求監視、過濾和封鎖互聯網上傳內容。 議員在全體會議上通過了之前被他們否決、後經修正的歐委會《歐盟版權指令》。 這增加了對小企業和言論自由的保障……歐委會此前已籌備讓網絡平台和新聞聚合服務承擔侵犯版權的責任;歐洲議會的立場強化了該計劃。 《指令》將同樣適用於新聞片段(snippets),即只顯示來自新聞機構全文的一小部分。 實踐中,“侵權責任”要求責任人向權利人支付其傳播的版權內容費用。 同時,為鼓勵創業和創新,《指令》文本免除了小微企業的責任。
我選擇引用這個名不見經傳的新聞源是有原因的:萬一本站有超過50 名員工,或者收入超過1000 萬歐元,根據本次立法,我就可能要為了這次摘錄向EUbusiness 支付補償金 。 幸運的是(好吧,應該說不幸的是),我離這個“萬一”還差得遠;感謝歐洲議會,給了我一次創業和創新的機會。
有了這則例外條款,再加上刪去了對內容過濾的明文要求(雖然在實踐中仍會是必須的),已經足夠讓《版權指令》獲得通過了。 這並不意味著它成為了法律:《指令》的最終文本還有待歐洲議會、歐委會和歐盟理事會(代表各國政府)協商,然後通過歐洲各國的國內法得到實施(這就是為什麼它叫做 指令)。
儘管如此,要證明歐洲的政策制定者還沒搞清互聯網的本質,此事絕非孤例:上一個例子是今年早些時候生效的《通用數據保護法規》(GDPR)。 正如《版權指令》一樣,GDPR 瞄準的也是 Google 和 Facebook。 但正如那些徹底搞錯了對手的鬥爭一樣,GDPR 的淨效應實際上是 加固了這些公司的護城河 。 畢竟,誰能比那些最大的公司更會駕馭複雜的法規,又有誰比那些收集數據最多的公司更不需要從別處找數據呢?
事實上,通過探究歐洲的《版權指令》新規錯在何處——不僅僅從政策的角度,同時也從它試圖保護行業的角度——將能為我們提示一種新的規制方式,那 就是利用互聯網釋放的關鍵力量,而不是和它作對。
《指令》第 13 條與版權
原諒我引用這些法律黑話(真的是黑話),但請讀一下《版權指令》中與互聯網平台版權責任有關的部分(指令原文 見此 ,上週通過的修正版 見此 ):
在線內容分享服務提供者扮演著與公眾交流的角色,因此對其內容負有責任,且應當與權利人達成公平與合適的許可協議。 達成的許可協議同時應在相同的程度和範圍上覆蓋行為出於非商業目的的用戶的責任……成員國應當規定,如果權利人不願達成許可協議,在線內容分享服務提供者應善意地與 權利人合作,以保證未經許可的版權作品或其他有關內容不被發佈在其服務上。 在線內容服務提供者與權利人之間的合作,不應阻礙未侵權作品或其他有關版權內容的發布,包括版權保護被除外或受限制的內容……
這就是立法者最典型的幻想:互聯網平台應該從所有版權持有者那裡得到許可;但是如果他們不想得到(或者換種更實際的說法,得不到)許可,就得把所有版權內容擋在 門外,儘管可以放行所有沒有版權爭議、或者版權例外的內容。 這最後一截規定是在直接回應那些將《指令》稱為“表情包禁令”的指責:發表情包沒問題,但這個例外“應該只適用於某些不與正常行使對作品或其他有關內容 的權利相衝突,並且不對權利人的合法利益造成不合理損害的特殊情形”。 這幾乎不是人類能看懂的話;想找出一個能大規模應用的解決方案——是的,這不可避免地意味著內容過濾——更是荒唐的。 能事前阻止侵犯版權而不造成大量誤判的方案,特別是能大規模應用的方案,根本就不存在。
這樣一來,問題就變成了“誤判”應該偏向於多判還是少判。 回顧歷史,由於 一些幸運的巧合 ,互聯網企業幾乎免於承擔侵犯版權的責任,而只需要在一段合理時間內對刪除內容的通知作出答复。 換句話說,這個機制是偏向於假陰性的:如果誤判,結果是本不應被上傳的內容被上傳了。 然而,《版權指令》是偏向於假陽性的:如果誤判,結果是允許傳播的內容被封鎖,因為害怕承擔責任。
這是錯誤的。 一個理由在於,版權的核心理念,就是政府對語言的特定排列方式授予一種壟斷權力。 我當然不是反對這個原則——我顯然是這一理念的受益者——但在一個自由社會中,“無罪推定”應當能對抗那些有權限制自由的人的權利。 相反,《版權指令》卻要求把互聯網平台變成這種政府授予的壟斷權力事實上的執行手段;而這種規定唯一合理的應對方式,就是走向不合理。
此外,侵犯權利人版權的成本已經大大降低了。 我這裡說的就是字面意思上的成本:實物時代,要“偷”來一個版權作品,就必須製造實物產品,並承擔其帶來的邊際成本。 任何為這一成本買單的人(即盜版產品消費者——譯者註)花的都是真金白銀,並且這錢沒有進到權利人的口袋裡。 相反,數字產品的複制沒有成本;不管是盜版音樂、電影,還是本站的 每日資訊 ,都幾乎不能表明權利人損失的收入。 換句話說,損害是真實存在的,但損害程度卻無從知曉,高可以高到版權持有人索賠的天文數字,低也可以低到復製作品本身的邊際成本——零。
更大的挑戰在於,整個版權體係都是基於實體介質建立起來的:實體商品易於追踪、易於禁售,最關鍵的是易於定價。 推而廣之,任何規制措施或有關商業模式,只要與前互聯時代的版權體系基於同樣的假定(即商品都是實體的——譯者註),都將完全沒有意義。 有意義得多的做法,是基於互聯網的特徵建立新的商業模式。
音樂行業就是一個再合適不過的例子: 美國唱片業協會(RIAA)還在抱怨盜版造成了數十億美元的損失 ,但很多人不知道音樂行業 重新開始增長了 ,其中去年收入就上漲了 16.5%。 這背後的驅動力是音樂流播,而光看名字就知道,流播的基礎是互聯網:服務訂戶可以聽到幾乎所有想听的音樂,而唱片行業每年可以從每個用戶身上掙到大約65 美元, 並且不用花任何邊際成本。 這對顧客是絕好的優惠,對唱片行業也同樣是絕好的盈利模式;這種互惠來源於順應互聯網的潮流,而不是逆流而上。
你會注意到,舉這個例子並不是表明版權本質上是不好的,而是主張版權規制和以稀缺性為前提的商業模式是不可行的,並且最終是不能盈利的。 採用以富餘為前提的路徑,將給從顧客到內容創作者的所有人帶來更多好處。 制定規制措施也應當採取類似的視角:敦促版權所有者不要光去限制自己作品的傳播,更要去創造新的商業模式,適應世界的現狀,而不是過去。
《指令》第 11 條與聚合服務
從稀缺到富餘的變化對於新聞出版業同樣有著深遠的影響,這是我在 《聚合理論》 (Aggregation Theory)一文中已經闡述過的:“價值已經從控制著稀缺資源傳播的公司,轉移到了控制著對富餘資源需求的公司。”
不幸的是,《版權指令》的製定者毫不掩飾他們對這種變化的無知。 《指令》的第 11 條規定:
強勢的的平台和弱勢的出版者(可能兼為新聞機構)之間的不平衡越發明顯,這已經導致媒體市場在區域層面上的顯著衰落。 在從印刷到數字的轉換中,印刷品的出版商和新聞機構面對著諸多問題,包括如何控制其出版物的在線使用和如何收回投資。 由於未承認出版物出版商的權利人身份,數字環境下的版權許可和執行經常是複雜和低效的。
根據這種解讀,出版商面臨的問題是一個官僚式的問題:獲取他們的合法利益是“複雜和低效的”,因此《指令》才要賦予他們對其出版物“直接或間接,以任何 方式及任何形式,整體或部分地進行臨時或永久的複製作出授權或禁止的排他性權利”,“使其能從信息社會的服務提供商對其出版物的數字使用中獲得公平和比例適當的補償 。”
但問題在於,出版商面臨的並不是官僚問題,而是它們在一個以富餘為特徵的世界中的處境發生了變化。 我在 《富餘時代的經濟力量》 一文中寫到:
對典型的報紙而言,當下的競爭環境與它們所習慣的截然相反:出版資源的數量不再稀缺,而是過分富餘。 更重要的是,這種競爭環境的變化從根本上改變了經濟權力的歸屬。 在一個以稀缺為特徵的世界中,控制了稀缺資源的人有權設定得到這些資源的價格。 以報紙為例,讀者的注意力曾是稀缺資源,而買家是廣告商……然而,互聯網是一個富餘世界,其中重要的是一種新力量:理解、索引這種信息的富餘,在這個 人人可以觸及的“稻草堆”中找出“針頭”的能力。 Google 掌握了這種力量。 因此,儘管如今受眾的注意力分散在實際上數量無盡的出版者中,廣告商雖渴望觸及卻無望覆蓋,這些讀者卻必須從同一個地方出發——Google。 因此,它就成了廣告費流向的地方。
以下是我用來演示出版行業變遷的圖示(圖中是以 Facebook 為例):
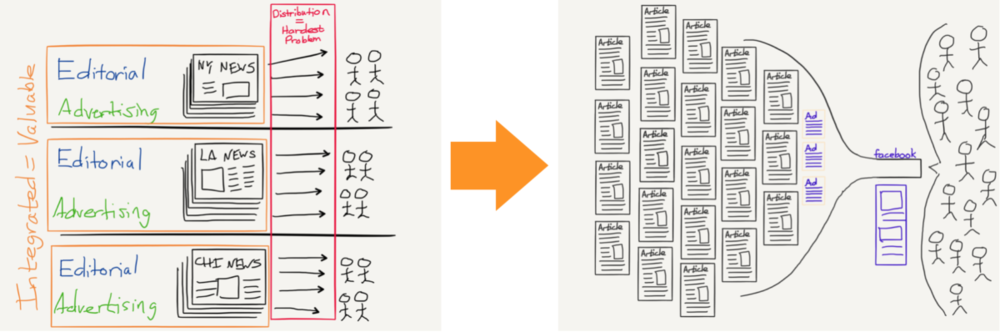
這就是為什麼所謂的“鏈接稅”注定失敗。 實際上,之前每次這種嘗試都已經失敗了。 Google 從其新聞功能中並不獲得直接收入,因此將會直接停止在歐洲提供 Google 新聞功能,或者大幅限制其顯示的內容。 而唯一會受到傷害的,除了歐洲消費者,就是那些從 Google 新聞獲得訪問量的出版物。 同樣,這 正是之前發生的 。
還有一個例子可以說明歐盟的提案是在如何試圖公然對抗市場的自然力量。 Google 搜索引擎尊重網站的 robot.txt 文件,出版方可以通過該文件讓自己的網站不被 Google 索引。 如果 Google 真的在從出版商辛苦生產的文字中獲取不公平利潤,那麼它們已經有了一個觸手可及的工具可以阻止 Google。 然而它們沒有阻止,因為現實是儘管出版商需要 Google(包括 Facebook),這一需求卻不是雙向的。 因此,如果錢可以從 Google 和 Facebook(或者本站,假如我的收入能達到 1 千萬歐元的話)流向出版商,唯一的實現形式就是依靠暴力機關執行的“轉載稅”。
但還是那句話,問題可以有一種截然相反的解決方案,那就是利用互聯網,而不是和它作對。 從大型報紙到本站這樣的小型站點,越來越多的出版者開始利用互聯網釋放的、可以觸及的巨大市場;它們開始利用免費社交媒體和搜索結果的營銷潛力,與其在意的讀者直接溝通— —然後對其收費。
我承認這個過程需要花費時間:對於在壟斷前提下成立的出版商來說,不僅要改變商業模式,還要改變 整個編輯戰略 ,以應對看重質量超過數量的世界,更是尤其困難。 因此,如果歐盟真的想要像它們在《版權指令》中所說,“保證可靠信息的供應”,那就應該讓其實際上要推行的稅收和補貼計劃更透明,而不是半遮半掩 。
GDPR 與聚合理論在規制問題上的推論
這就要說到我長久以來持有 強烈批判 態度的一則立法:GDPR。 這一法案的意圖當然是值得尊敬的——保護消費者隱私,儘管我可能有點懷疑(或許是因為我的美式思維)多數消費者比起媒體精英到底有多關注隱私。 無論答案如何,立法意圖的重要性都比不上其實際效果,而 GDPR 的實際效果就是鞏固了 Google 和 Facebook 的地位。 我在《開放、封閉與隱私》一文中寫到:
儘管 GDPR 的支持者指出 Google 和 Facebook 試圖遊說否決這一立法,因此證明了該法將會有效,這完全是弄錯了重點。 兩家公司當然不希望招致如此重磅法規中規定的處罰,這也當然會限制它們能收集的信息數量。 但支持者忽視的是,數字廣告的增長是一個長期趨勢,它最首要最顯著的驅動力是眼球:越來越多的時間被花在手機上,廣告費也會不可避免地隨之流向手機 端。 因此,要計算的關鍵不是 Google 或 Facebook 一家公司會受到多少損失,而是它們的損失相比其競爭者的程度高低。 答案顯然是“少得多”。 放在上述長期趨勢的背景下,“少得多”就意味著增長。
這就是所有大型互聯網法規,包括《版權指令》,所要面對的難題。 畢竟,Google 和 Facebook 能負擔得起、或者已經建立起內容過濾機制,並且已經獲得了足夠多的用戶關注度,因而有底氣切斷外部的內容供應。 因此,規制的必要性已經不太是個問題,更大的問題是到底可不可能規制(當然,假設規制的目標不是鞏固 Google 和 Facebook 的地位的話)。
因此,思考《版權指令》存在的問題是有益的:
首先,和商業模式一樣,規制措施也應利用互聯網來建構,而不是與其對抗。
其次,規制的起點應當是理解互聯網上的權力來自於控制需求,而不是控制供應。
要理解這種“新的”規制應該是什麼樣,可以回顧之前發生的事。 特別要看到,過去六個月中,Facebook 在保護用戶隱私方面進步顯著。 它關停了第三方對敏感數據的訪問權限,對大量有權訪問敏感數據的應用開發商進行了審查,增加了新的隱私控制功能,等等。 不僅如此,Facebook 這些舉措的對像還是全體用戶、而不僅僅是歐洲用戶,這表明它的舉動並不是由 GDPR 推動的。
實際上,它的動因是明顯的:劍橋分析(Cambridge Analytica)醜聞以及與之相關的所有負面關注。 換句話說,在用戶隱私問題上,失敗公關對 Facebook 的驅動超過了 GDPR 和 FTC 和解令 。 這並不令人驚訝。 我在 《Facebook 的動機》 一文中寫到:
或許 Facebook 還有第三個動機,不妨稱之為“醒悟後的自利行為(enlightened self-interest)”。 別忘了 Facebook 的力量是從何而來的:控制需求。 Facebook 是一個 超級聚合器 ,這意味著它擁有與用戶的直接關係、服務用戶的邊際成本為零,以及存在網絡效應;憑藉這些要素,它不斷降低獲取用戶的成本並無限擴張,進而形成良性循環。 這賦予了 Facebook 同時控制供應方(出版方)和廣告主的力量。 因此,Facebook 的終極威脅永遠不可能來源於出版方或廣告主,而是來自於需求側——那就是用戶。 但真正的危險並不是用戶同時使用競爭對手的社交網絡(儘管 Facebook 一直對此過分偏執),因為這並不足以打破 Facebook 的良性循環。 相反,唯一可能抹消 Facebook 力量的情形就是用戶主動拒絕使用 Facebook 應用。 我還懷疑,用戶唯一可能大規模抵制 Facebook 應用的情形,就是人們普遍認為 Facebook 會帶來實際傷害——就好像是在網絡上的煙癮一樣。
對 Facebook 來說,劍橋分析醜聞就好像是 美國衛生總監關於吸煙的報告 :威脅不在於規制機關會做出行動,而是用戶會做出行動。 沒有什麼比這更致命的了,因為:聚合理論在規制問題上的推論,就是終極的規制來自於用戶。
無論歐盟還是其他規制機關,如果它們真的想限制 Facebook 和 Google,或者那些實際上在用戶隱私方面造成威脅更大的廣告網絡和廣告公司,那麼終極力量就是影響用戶需求。 而撬動用戶需求的槓桿,正是要求這些公司提高其行為的透明度。
因此,如果我身在其位,就會從建立透明機製而不是執行機制入手。 我將想要確立度量用戶隱私的清晰尺度——收集數據的類型、推斷所得的數據類型、刪除用戶生成數據的機制、刪除推斷所得數據的機制、共享數據的內容和共享方——以此對 受管轄的公司進行度量,在必要的時候動用傳喚權力,並將結果發布給用戶查看。
這就是能真正通過市場向巨頭施壓的方式:不是依靠規制機關的法令,而是依靠用戶的情緒。 因為,這種方式意味著理解了世界的現狀而不是過去,意識到失敗公關(影響到需求)遠比用壟斷收益支付的罰金更能有效推動科技巨頭的改變。
本文由 onespiece 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文請於文首標明作者姓名,保持文章完整性(包括虎嗅注及其餘作者身份信息),並請附上出處(虎嗅網)及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/264015.html
未按照規範轉載者,虎嗅保留追究相應責任的權利