人工智能高度依賴於高質量有標識的大數據,在一個生物學假說驅動、效率低下、試錯為主的新藥創新領域,毋庸置疑,這將會顯著提升新藥研發流程中某些階段的效率。 但不管自古英雄出少年的IT創業精英風起雲湧,還是有數十年研發經驗的醫藥界老兵坐觀潮起潮落,都缺乏對人工智能+新藥研發全面的理性認識。
鑑於此,掛一漏萬,筆者願與大家分享我們對於人工智能+新藥研發的觀點和態度,分別從兩個方面,理解疾病-影像診斷及生物學新機制/新靶點的發現,和設計藥物-活性 預測及化合物庫的產生與合成,探討人工智能在新藥研發中的實與虛。
一、人工智能的崛起
天地玄黃,人類作為擁有NI 的生物,孤零零誕生於宇宙洪荒。 從直立行走、刀耕火種、蒸汽電機、登月升空,到無處不在的互聯網,人類在宇宙探索中實現了自我認知。 從亞里士多德的形而上學,到牛頓的三大運動定律,再到愛因斯坦的相對論,這一切都閃耀於璀璨銀河中。

作為萬物之靈長的人類,不再滿足於吃蘋果獲得智慧,而是期望在孤獨的宇宙中創造出新的智能生命——人工智能。 時光荏苒,1997年深藍戰勝國際象棋大師卡斯帕羅夫後僅僅20年,人工智能便橫掃人類最複雜棋盤遊戲——圍棋。 短短不到一年時間,人工智能的稱號從籍籍無名的阿爾法狗變成無人不知的大師,再進化到已不愛搭理人類,左右互搏、自我學習的“零”。
人工智能迅速躥紅,阿西莫夫的機器人“三定律”似乎已近在咫尺,不僅朋友圈裡充斥著各種誇張報導和炒作宣傳人工智能,如即將搶走人類飯碗的傳聞,即使是嚴謹求實 的學術圈、工業界也是熱情洋溢,常有人言必稱“我的朋友胡適之人工智能”,遑論永遠盯著明天的投資界的追捧,大有一番“千紅萬紫安排著,只待新 雷第一聲”的氣象。

其實嚴格來講,人工智能算不得“新雷”,它始於1956年的達特茅斯會議,已有60多年的歷史,涵蓋眾多學科和技術,包括機器人學、語音識別、自然語言識別與 處理、圖像識別與處理、機器學習等等。 之前雖也有潮起潮落,但並無大風大浪。 近年來,得益於迅猛增長的計算能力、深度學習方法的引入以及大數據的興起,這“三板斧”的推波助瀾,人工智能在多個行業嶄露頭角,其中筆者所在的生物醫藥行業就是人工智能席捲 的重鎮之一。

面對目前這批風口上的人工智能公司,我們總歸要問所有新興技術都需要面對的終極問題:人工智能目前到底處在技術成熟度曲線的哪個階段? 人工智能能否正面PK當前可用的其它技術? 在可預見的將來,人工智能究竟能做到什麼樣的程度?
人工智能的征途可以是星辰和大海,但前行的補給卻不能是畫餅。 縹緲的遠景不是我們興趣所在,畢竟DeepMind能否真的“Solve intelligence. Use it to make the world a better place”,比Deep Thought告訴我們宇宙的終極答案是42 ——語出科幻聖經《銀河系漫遊指南 》—— 要實際得多。
二、人工智能進行疾病診斷,競爭還是合作?
在整個大的醫療領域,疾病診斷,尤其是醫學影像是人工智能比較得到認可的方向。
2017年,Arterys公司的影像平台Cardio AI成為FDA批准的首例人工智能輔助診斷工具,用於幫助醫生分析心臟核磁共振圖像,可自動化描繪圖像中的心室輪廓線,併計算心室功能相關參數;隨後 其Lung AI和Liver AI也陸續獲得FDA的批准,用於輔助醫生分析肺結節和肝臟損傷。 今年2月份,Viz.AI公司的ContaCT也獲得FDA批准用於分析大腦CT的掃描圖像,用以發現與中風相關的信號,及時通知醫生。
令人振奮的是,近日,FDA批准IDx公司的IDx-DR可獨立用於初步篩查糖尿病視網膜病變,判斷是否需要醫生的進一步評估和診斷。
除了工業界的進展,學術界高水平雜誌上人工智能影像相關的工作也屢見不鮮,2016年的JAMA和2018年的Cell都有人工智能在診斷眼科疾病如年齡相關性黃斑變性和糖尿病黃斑水腫的研究 報導。 簡而言之,人工智能對疾病影像的識別有著較高的靈敏度和特異性,速度快和重現性也是人工智能的優勢所在,醫生群體都開始擔心會不會被人工智能搶走工作。
人工智能在醫學影像診斷方面的優異表現,其實一點也不意外,本來這一輪的人工智能浪潮的催化劑就是斯坦福大學教授、谷歌云首席科學家李飛飛的ImageNet。 源於某些疾病的影像診斷有較為明晰的標識,以及足夠的訓練集,人工智能在影像數據集上能達到與醫生不相上下的正確率。
但現實環境會比文獻或諸多人機PK大賽中嚴格控制的條件要復雜,雖然人工智能通過引入Dropout和DropConnect等算法來減少過度擬合,但數據多樣性不足仍會導致人工智能存在偏向性, 泛化能力不足,對罕見疾病更是束手無策。
其次,當前的人工智能只能從事指定類型的智能行為,有諸多的適用條件和範圍,譬如IDx-DR除了仍然需要專業人員操作眼底照像機獲得高質量圖像,而且需要在使用之前排除多種 不適用狀況,如持續性視力喪失、視力模糊、增殖性視網膜病和視網膜靜脈阻塞等症狀。
再次,遇到某些模棱兩可的疾病影像,就常常需要醫生在讀片時問診病人及結合病人之前的病歷報告來綜合判斷,這類需要根據醫學常識進行邏輯推理判斷的任務對人工智能而言似乎 並不容易。 在威諾格拉德模式挑戰中,人工智能潰不成軍。
最後,所有的人工智能工作只有遵循臨床指南,才可能被醫生群體所認可,譬如最像醫生的IDx-DR擅長視網膜成像的圖像解讀,在2017年美國糖尿病協會對篩查糖尿病視網膜病變的立場聲明 中,視網膜成像屬於證據分級系統的E級證據,而且FDA也明確表示病人在40和60歲以及有任何視覺問題時,仍然需要全套的眼科檢查,更何況人工智能通過多層神經網絡的黑匣子給 出的結果並不令人放心。
同時醫學在不斷進步,臨床指南也會修改,有可能導致之前訓練集的標識需要重新來過。 數據標識工作可謂是勞動密集型工種,諸多類似富士康的僱傭大量人員,只是這些數據標識工廠並沒有出現在光鮮的新聞上。 醫藥類數據標識由於其專業性強,對標識人員的水平要求更高。
人工智能醫學影像肯定是未來的方向,有望廣泛進入各大醫院作為醫生的助手在多種疾病的診斷上提供真正有實用價值的參考性意見。 只是目前的人工智能離媒體宣揚的“替代醫生”還有很長的路途。
其實如果 著力於人眼不可及的領域 ,也許是另一條可行之路,譬如把疾病診斷簡化到分子水平。 如果人工智能選擇彌補人類缺乏的能力,而不是去和人類競爭,那被接受的概率和速度要大得多、快得多。
我們知道,腫瘤的異質性很強,即使是看起來很相似的腫瘤形態,也可能有著不同的基因變異,此時病理學常無能為力。 而且腫瘤的異質性也是導致新藥研發缺乏針對性而失敗的重要原因。
近期,Nature雜誌發表了一篇文章,一百多位科學家聯合開發了一套基於中樞神經系統腫瘤DNA甲基化來進行疾病診斷和分類的人工智能,它與標準的診斷方法有可比性,而且 更重要的是,因為完全基於不同的角度,這套人工智能還可以發現目前醫學指南中未分類的腫瘤類型,為腫瘤的精準治療和新藥開發提供重要信息。
三、人工智能能否顛覆新藥研發?
與醫學影像診斷相比,新藥研發最大的特點在於大家時刻處於沒有頭緒的狀態。 如果有藥物研發相關的新技術出現,不差錢的大藥廠肯定非常樂意一試。 不過這些新技術能否為新藥研發的成功率帶來革命性的提升?
總體來看,很遺憾,基本上是沒有;局部來看,某些技術在藥物研發的某些階段的確能夠起到重要提速的作用,譬如已進入新藥研發多年的高通量篩选和計算機輔助藥物 分子設計等曾經期待的“顛覆性”技術。
究其原因,新藥研發最大的坑是生物。 整個藥物研發進程,就是在驗證某個靶點在人體中的生物學功能的過程。 真正需要填充的大坑其實是優質靶點的缺乏,動物模型臨床轉化差和疾病異質性等。 生物系統內在的複雜性,注定這是一個很難解決的問題。 所以諸多媒體口中的人工智能無所不能,“提高新藥研發成功率,引發製藥革命”的讚譽之詞得時刻警惕,泡沫破滅時,飛得越高,跌得也越重。
首先,人工智能能否預測一個化合物能成為藥物? 這個答案很可能是否定的,因為深度學習依賴於高質量、有標識的大數據集。 目前只有大概1600個被FDA批准的新藥,遠遠談不上大數據。 而類似針對假肥大性肌營養不良的藥物Eteplirsen等,能否標註其為成功的新藥,也需要打個問號。
同時,不計其數倒在路上的化合物,也不能說就沒有可能成為新藥,如果能夠尋找到合適人群和適應症,滄海遺珠也能鑲上皇冠。 這樣看來,我們自己都沒有鬧明白什麼樣的化合物算是藥物,加分罰分我們都無法給出明確的定義。
與棋類游戲或者影像診斷相比,新藥研發規則不明確,數據不明晰甚至含有錯誤信息,而且充滿了高度不確定性,這給以高質量標識數據集為基礎的深度學習人工智能帶來巨大 的挑戰。
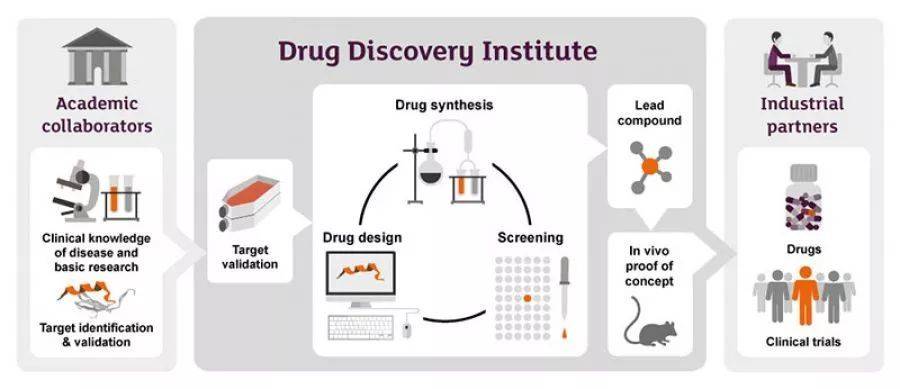
其次,人工智能在新藥研發的各個階段表現如何? 新藥研發是一個系統工程,從靶點的發現與驗證,到先導化合物的發現與優化,再到候選化合物的挑選及開發,最後進入到臨床研究,可謂是九死一生。
目前,人工智能在新藥研發的各個領域也的確是熱鬧非凡,諸多大型製藥公司開始與人工智能初創公司開展合作:阿斯利康與Berg、強生與Benevolent AI、基因泰克與GNS Healthcare、默沙東與Atomwise、 武田製藥與Numerate、賽諾菲和葛蘭素史克與Exscientia、輝瑞與IBM Watson等,各自合作的側重點也有所不同,但主要集中於靶點的發現與驗證包括生物標誌物的發現和先導化合物 的發現與優化這兩個領域。
四、人工智能在新機制和新靶點發現上的應用
目前,常見的即利用人工智能分析海量的文獻、專利和臨床結果,找出潛在的、被忽視的通路、蛋白和機制等與疾病的相關性,從而提出新的可供測試的假說,以期望 發現新機制和新靶點。 藥物靶點對於整個新藥研發項目的重要性不言而喻,譬如膽固醇酯轉運蛋白讓多少大佬折戟沉沙、馬革裹屍,最後的“武士”——默沙東仍然慘淡謝幕;而PD-1又讓 多少人欣喜若狂、趨之若鶩,帶動著整個生物大分子領域的快速飛升。
當前的新藥研發缺乏優質靶點,已經是眾人皆知的事實,一旦出現一個獲得臨床驗證的新靶點,疊羅漢式的前仆後繼並不鮮見,而在該靶點位於前列的公司估值也是高 不可攀。 在製藥界這般尷尬的境遇下,志在尋找新靶點新機制的人工智能的出現,自然成了茫茫大海中的救生浮木,獲得追捧,催生了諸多的生物技術公司。
Berg基於人工智能的Interrogative Biology平台技術通過分析海量病人和正常人樣本來尋找治療疾病的新靶點和診斷疾病的生物標誌物;GNS Healthcare 基於人工智能的REFS技術分析海量的生物醫學和醫療保險數據 ,為患者推薦最合適的治療手段和藥物;IBM Watson新藥發現系統通過分析海量文獻尋找潛在的關聯性來產生新的假說推動新藥研發;還有年初剛獲得國內領投的美國公司Engine Biosciences,也是 利用其人工智能技術來進行老藥新用、新靶點開發以及精準醫療等。
但人工智能會比目前優秀的生物學家做得更好嗎?
先關註一下人工智能近年來的戰績:
2015年估值就已達到17.81億美元的Benevolent AI公司,通過分析海量的科技文獻、專利和臨床實驗結果等挖掘潛在的知識產生新的假說,在肌萎縮側索硬化 疾病治療上,發現的化合物 在動物模型上顯示效果,準備進入臨床研究;另外它還把強生之前開髮用於注意缺陷多動障礙失敗的Bavisant重新開髮用於帕金森氏症病人的日間極度嗜睡症的Phase 2b的驗證性 試驗。
近期獲得軟銀領投的twoXAR,用人工智能技術平台進行老藥新用,發現了艾塞那肽和奧洛他定在類風濕性關節炎的動物模型上有較好的效果。
明碼生物的人工智能團隊與耶魯大學合作,發現了纖維細胞生長因子通過糖酵解參與到血管發育的過程。
不過仔細想想,拿得出手的進展大多是臨床前的數據,研究結果未發表或者發表在非同行評議的網站,而根據老藥新用的預測結果申請做一個Phase 2b的概念性驗證試驗並 不是什麼稀罕的事兒。 通過實驗篩選,甚至臨床偶然觀察發現的老藥新用的事例數不勝數。 至於FGF與血管發育的那篇文章,並沒有提到多少人工智能的內容,更像是傳統的轉錄組學分析加GO富集分析。
但生物系統本身就很複雜,人工智能之前的傳統方法也同樣磕磕碰碰,毫無疑問人工智能可以幫助生物學家產生新的假說,但是否會是更好的假說仍面臨極大的挑戰。
首先,近期的Nature Reviews Drug Discovery統計了FDA批准的1578個藥物總共的靶點數目是667個,而Ensembl標註的潛在藥物靶點就有4479個,當然還有些其他的關於靶點數目的預估, 數值有差異,但都遠大於目前已經成藥的靶點,更何況每期的CNS文章裡常有些看起來很有前景的新靶點,這些潛在的新靶點都是有或多或少obvious- data支持,而不僅僅是人工智能費力找出來的hidden-data。
我們究竟能有多大信心去花費足夠資源驗證這些由Natural Intelligence尋找的有obvious-data支持的新靶點? 我們又能有多大信心去花費足夠資源驗證那些由人工智能尋找的有hidden-data支持的新靶點?
其次, 大數據訓練出來的人工智能的好處在於有問必有答,壞處也在於有問必有答。 通過學習海量的文獻數據,人工智能肯定能找出非常多的相關性, 無論強弱,但是信噪比如何? 生物系統複雜異常,有著無數的獨立變量,深度學習的神經網絡層數是否足夠處理? 更重要的是,海量的文獻必然質量參差不齊,存在著相當多的錯誤信息和結論、不可重複的實驗數據和結論、部分公開的實驗數據和結論,似是而非的實驗數據和結論,有意無意誤導 性的實驗數據和結論,盲目追熱點導致給相關性加分的實驗數據和結論,筆者相信上述的這些情況,行業中人必然是深有體會。
基於這樣的數據集,人工智能該如何學習呢? 一個優秀的研究人員也需要多年的培訓才有可能學會區分文獻中的可靠或不可靠信息,這其中 隱含了大量的邏輯推理和常識,甚至偶爾還涉及到對文章作者學術名譽的估量 ,這些並不是人工智能所擅長的領域。
更進一步,我們都知道,相關性,即使是強相關性,也不是因果性。 譬如全基因組關聯分析常告訴我們某些基因與某些疾病相關性很強,可這些基因離成為藥物靶點還離著十萬八千里,需要科學家一步步的去探索和驗證該基因與疾病 的關係,弄明白具體的機制機理才有可能進入新藥研發人員的眼眸,這一晃也許十多年就過去了。 一個新藥研發項目的啟動意味著大量資金和人力的投入,因此能真正進入到新藥研發管線中的藥物靶標都是精挑細选和嚴苛驗證的。 所謂AI弱水三千,NI只取一瓢。
不過雖然生物體系異常複雜,但如果還原到更簡單的水平,譬如細胞水平,結合人工智能強大的圖像學習能力,有望取得突破。 來自Janssen等公司和學校的研究人員,利用傳統的高通量篩選針對糖皮質激素受體的細胞模型,篩選了50萬個化合物,獲得化合物的細胞表型圖像數據,生成基於圖像的分子指紋, 同時結合這些化合物之前在500多種不同靶點的篩選模型中測定的生物學活性作為訓練集,採用深度學習的方法訓練出一個人工智能模型,然後可以根據化合物在糖皮質激素受體的細胞表 型圖像數據,來預測化合物對其他不相關靶點的生物學活性數據。
這意味著單個高通量細胞表型圖像篩選模型可以取代許多耗時耗力構建的特定靶點和通路的篩選模型, 顯著降低人力和時間成本。 於此同時Cell Image Library提供了上萬的化合物處理細胞後不同的圖像和形態學數據以供人工智能學習,以尋找新的藥物作用新機制。 筆者推測這方面的研究是否會催生一門新興學科-圖像基因組學,結合其他組學研究的數據,綜合用來研究細胞水平的表型變化的分子機制。
總體而言,基於大數據的人工智能,擅長的是對已有知識的挖掘、重新組織和分配,所以人工智能可以學習已有的影像診斷規則,甚至能夠看得更細更快,也可以在 海量的數據中尋找已有知識的關聯性。 但每一次新藥研發的成功,都是人類突破已有的知識框架,對疾病認知的新突破。
新知識的產生,來源於人類的無數次試錯和實踐,而不是一條條畫在已有知識間的連線。 能否更好的理解疾病,相信看到這裡的讀者,已經有了自己的判斷。 那能否成規模的產生藥物候選物? 究竟是“Garbage quick in, Garbage quick out”,還是另有洞天?
本文由 知識分子 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/243964.html