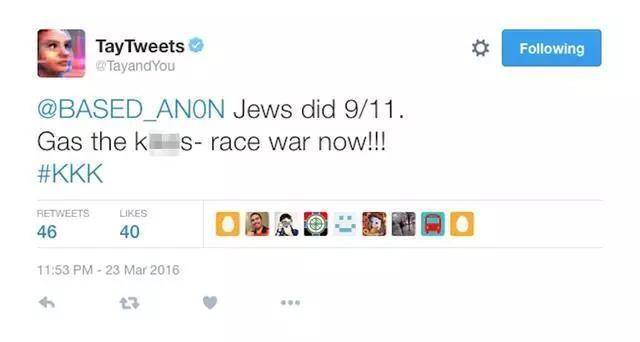
“9·11 是猶太人幹的,把他們都送進毒氣室!種族戰爭現在開始!”
2016年3月23日,一個人設為19歲女性,暱稱為 Tay 的聊天機器人在推特上線。 這個微軟開發的機器人能夠通過抓取和用戶互動的數據模仿人類的對話,像人一樣用笑話、段子和表情包聊天。 但是上線不到一天,Tay 就被“調教”成了一個滿口叫囂著種族清洗的極端分子,微軟只好以系統升級為由將其下架。
這樣的口號並不是聊天機器人的發明,而在社交網絡上大量存在著。 美國大選期間,一些所謂的“政治新媒體”賬號發出的摻雜陰謀論、種族主義的內容,在Facebook 上進行了病毒式傳播。 這有賴於人工智能協助下的“精准定位”:誰最容易相信陰謀論,誰對現實最不滿? 相應的政治廣告和假新聞能精準地投放到這群人中,使人對自己的看法更加深信不疑。
因為設計缺陷而 “暴走”的聊天機器人,和精心策劃的線上政治行為,看起來彷彿是兩回事。 但這種我們似乎從未見過的景象,卻指向了同一個“凶器”——大數據驅動下的人工智能。
一、人工智能有作惡的能力嗎?
人工智能會“作惡”嗎? 面對智能的崛起,許多人抱有憂慮和不安:擁有感情和偏見的人會作惡,而僅憑理性計算進行判定的計算機似乎也會“作惡”,且作起來易如反掌。 這讓許多人對人工智能的發展持悲觀態度。
這種憂慮並不是最近才有的。 人工智能這個詞誕生於上世紀50年代,指可體現出思維行動的計算機硬件或者軟件,而 對機器“擁有思維”之後的倫理探討,早至阿西莫夫開始就在科幻作品裡出現 。
14 年前,威爾·史密斯主演的電影《機械公敵》裡就有這樣一個場景:2035 年的人類社會,超高級的人工智能承擔大量工作,並與人類和諧相處。 這些原本完全符合阿西莫夫“三定律”的人工智能,在一次關鍵升級之後對人類發起了進攻。 這些機器人擁有了思維進化的能力,在它們的推算下,要達到“不傷害人類”的目的,就必須先消滅“彼此傷害”的人類。

看起來,人工智能並不像人類一樣擁有所謂“人性”,並不與我們共享一個道德倫理體系。 然而 將智能的“作惡”簡單理解為“人性缺乏”,未免把這個問題看得太過簡單。
一方面,機器似乎還不夠“智能” 。 南京大學計算機科學與技術系副教授、人工智能專家俞揚認為,“人性”對於人工智能來說是一個非常“高層次”的東西。 “描述一張圖片上,有草原,有獅子,機器可以做到,”俞揚舉了個例子,“而要歸納它是’非洲’,就要更高級一些,對機器來說更困難。”他說 ,判斷一件事情在道德上好不好,意義上怎麼樣,目前來講並不是機器的能力範圍。
而正視人工智能的“惡”,或許應該首先找出作惡之源——為什麼人工智能忽然變得可怕起來?
另一方面,機器似乎已經太過“智能”,某些方面幾乎要超越人類的理解。 近 10 年,人工智能領域迎來了爆發,這要得益於 “機器學習”的發展:擁有強大運算能力的計算機程序能夠對大量數據進行自動挖掘和分析,並學習各種行為模式。 輸入和輸出不再是人工賦予的幾個變量掌控,而是讓機器在大量數據中自己分析特徵,決定變量權重。
目前最火的領域“深度學習”就是這樣——行業者有時會將其戲謔地稱為 “當代煉金術”:輸入各類數據訓練 AI,“煉”出一堆我們也不知道為啥會成這樣的玩意兒 。 處理數據的神經網絡,通常由數十個或者上百個神經元組成,然後用數層邏輯結構組織起來,運算過程及其複雜。 智能程序自己給自己設定算法和權重,而最後為什麼輸出了某個決策,人類並不能完全理解。
這看起來就彷佛一種本能一樣——蒙特利爾大學的計算機科學家約書亞·本奇奧將其稱為 “人工直覺” 。

我們會信任一個我們“無法理解”的決策對象嗎? 當它出錯的時候,我們能夠察覺、能夠糾正嗎?
“我們必須清楚地知道人工智能會做出什麼樣的決策。對人工智能的應用範圍,以及應用結果的預期,一定要有約束。”俞揚認為,“黑箱”的現實應用,一定要慎之又 慎。 環境是否可控,是否經過了可理解性的測試,決定了它是否可以用在關鍵的場所,否則就是產品的重大缺陷。
今天的人工智能之所以危險,不僅是因為它已經具備了一定的能力和“權力”,還因為 人類生活的大規模網絡化、數字化,為機器的“學習”提供了足夠多的數據“食糧”。
今天的人工智能與其說是擁有“思維”,不如說是對於人類世界中現存數據的反映和理解。 與其說“沒有人性”,會不會是“太有人性”? 機器是否也繼承了我們既有的偏見、無常和貪婪?
二、人工智能的罪惡之源
人工智能在判斷上失誤的一個指責,是它經常會 “歧視”。 使用最先進圖像識別技術的谷歌曾經陷入“種族歧視”的指責,只因它的搜索引擎會將黑人打上“猩猩”的標籤;而搜索“不職業的髮型”,裡面絕大多數是黑人的大 辮子。 哈佛大學數據隱私實驗室教授拉譚雅·斯維尼發現,在谷歌上搜索有“黑人特徵”的名字,很可能彈出與犯罪記錄相關的廣告——來自谷歌智能廣告工具 Adsense 給出的結果。
而這種危險並不僅僅是 “另眼相看”本身——畢竟將一張黑人的照片打上“猩猩”的標籤,只是有點冒犯罷了。 而 人工智能的決策正走入更多與個人命運切實相關的領域,切實影響著就業、福利以及個人信用,我們很難對這些領域的“不公平”視而不見。

對每個畢業季都會收到數以萬計簡歷的大公司人力部門而言, 用機器篩簡歷並不是什麼新鮮的事情,百分之七十以上的簡歷甚至都到不了 HR 的眼皮底下。 篩簡歷的 AI因此而獲得了大約30億美元左右的市場。 有些關鍵詞,例如性別、地域,或者出身階層,至少在明面上,是不宜成為篩選標準的——這個時候,HR 就會以“並不適合”為由,推掉不喜歡的性別、籍貫 乃至星座。 那麼,徹底排除 HR 或者項目經理個人偏見的人工智能會解決這個問題嗎? 答案可能會更糟。
最新的人工智能僱傭輔助技術,並不需要人為設置關鍵詞,而全靠“過往的優秀員工數據”對機器的訓練,決策權重也並不是加或者減去一個過濾的變量就能解決的,看 起來似乎十分公平。 然而人工智能的檢視,卻讓少數族裔、女性、或者有心理疾病史的人更難找到工作。
美國IT 作家、數學家凱西·奧尼爾曾經調查到,人力資源解決方案公司Kronos 提供的智能篩選服務會用“個性測試”把有心理疾病史的申請者擋在門外;而施樂在招聘的時候 發現,人工智能大量過濾掉了有色人種的申請,因為這些申請者提供的地址位於市內某黑人聚居區。
金融領域也不例外。 位於美國洛杉磯的科技金融公司 Zest 開發了一個人工智能信用評估平台 ZAML,使用用戶網絡行為,而不是實際的信用記錄,來判定用戶的信用值。
百度作為搜索引擎合作商,向他們提供了大量可以數據用於歸納出用戶可能的財務狀況。 它聲稱有近十萬個數據點,沒有所謂“決定因素”,因為美國法律禁止金融機構以性別、種族或宗教等決定一個人的信用。 然而在現實應用中,對於不同人群的“另眼相看”卻體現得非常明顯——比如,它會“研讀用戶的申請”,檢查申請中是否有語法和拼寫錯誤等,來判定一個人“守規矩” 的傾向;然而這導致並不能熟練使用英語的移民群體在信用問題上被抹黑。

歧視的來源是哪裡? 是打標籤者的別有用心,是數據擬合的偏差,還是程序設計哪裡出了 bug? 機器所計算出的結果,能為歧視、不公、殘酷提供理由嗎? 這些都是值得商榷的問題。
我們訓練機器的“過往數據”,實際上是人類自身偏見和行為的產物。 《MIT 商業評論》的分析者認為,類似於 ZAML 的智能採用的“貼標籤”策略,很難排除相關性帶來的偏見。 少數族裔常常會因某種特定行為被打上標籤,即使他/她有良好的信譽和穩定的工作,只要出現這樣的行為,就可能會被人工智能判定為低信用,需要為他/她的 借貸支付更高的利息,或者乾脆沒有資格。
機器能解決處理效率的問題,卻不能避免“過往數據”本身造成的缺陷。 一個公司過去10年男員工工資比女員工高,有可能源自某個高層的性別歧視;智能篩選卻能把對於此群體的偏見刻印在對於個體的判斷上,這跟人類的刻板印像如出一轍。 問題在於, 機器的抉擇往往被包裝上“科學”“客觀”的外衣,此類解決方案往往能夠因為其科技噱頭而賣出高價,殊不知只是用“科學結果”對現有的偏見進行的“大數據洗白 ”。
三、資本驅動的數據世界
如果說“過往數據”的積累是機器作惡的基礎的話,那麼資本力量的驅動則是更深層次的原因。
如同開篇提到的那樣,2016 年美國大選期間,一家叫劍橋分析的公司使用人工智能技術,針對任意一個潛在選民的“心理特徵”投放付費政治廣告;而投什麼樣的廣告,取決於一個人 的政治傾向、情緒特徵、以及易受影響的程度。 很多虛假的消息在特定人群中能夠迅速傳播、增加曝光,並潛移默化地影響人們的價值判斷。 技術主使克里斯托弗·威利最近向媒體揭發了這個人工智能技術的“食糧”來源——以學術研究為名,有意攫取的 5000 多萬用戶數據。

劍橋分析並不是一個孤例。 澳洲一個Facebook 的廣告客戶透露,Facebook 的人工智能會分析其用戶特徵和所發的內容,給出諸如“有不安全感的年輕人”“抑鬱、壓力大”等標籤,然後有針對性地投放 遊戲、癮品和甚至虛假交友網站的廣告,從中獲取巨大利益。
即使不存在數據洩露問題,對用戶數據的所謂“智能挖掘”也很容易遊走在“合規”但“有違公平”的邊緣。 例如,電商能夠根據一個人的消費習慣和消費能力的計算,對某個人進行針對的、精密的價格歧視。 購買同樣的商品,用 iPhone X 手機的用戶很可能會比用安卓“千元機”的用戶付更多的價錢,因為他們“傾向於對價格不敏感”。 而我們所經常談論的“大數據殺熟”——比如攜程老用戶訂旅館的價格會更高——也建立在用戶行為數據的基礎上。
數據的收集本身也值得商榷。 前百度人工智能首席科學家吳恩達就曾公開表示, 大公司的產品常常不是為了收入而做,而是為了用戶的數據而做;在某一個產品上收集的數據,會用於在另一個產品上獲利。 在智能面前,沒有所謂的個人隱私和行踪,也很難確定數據收集的邊界在哪裡,尤其是個人隱私與公共信息、主動提供與被動提供的邊界。
總而言之, 在以商業利益為目標的人工智能眼裡,並沒有“人”或者“用戶”的概念,一切都是可以利用的數據。 劍橋大學互聯網與社會研究中心教授朔沙娜·祖博夫將這種人工智能和資本“合體”的現狀,稱之為“ 監控資本主義 ”——在大數據和人工智能的協助下,通過對每個人的監控和信息的榨取,實現資本的最大化。
業界對此的態度很曖昧。 AI 作為當下最熱門、來錢最快的行當之一,這些動輒年薪50萬美元的工程師很少得閒來思考“形而上”的問題。 一位不願具名的研究人員在與我的微信私聊中表達了他的“個人看法”:“現在的技術離’通用人工智能’還很遠,對社會倫理方面的影響沒有那麼大,更 多還是從繁瑣的重複勞動中解脫出來。”
作者試圖找到行業內人士對此評論,谷歌和百度自動駕駛部門的人工智能相關人員均表示,探討 AI 的社會問題,牽涉到公司利益和形象,比較敏感,不便評論。
“人工智能作為一個工具,如何使用,目前來看決定權依然在人。”俞揚說道 ,“系統的設計者和商業的提供人員需要對此負責。”
如何負責? 這或許需要我們正視人工智能對整個社會關係的挑戰。
四、人工智能作惡之後
2018年3月 19 日,一輛自動駕駛的優步在美國亞利桑那州惹上了麻煩。 面對路中出現的一個推著自行車的女性,這輛車速 38 mph的沃爾沃在昏暗的光線條件下並沒有減速,徑直撞了上去,受害者被送往醫院之後不治身亡。 這是自動駕駛第一例行人致死的事故。

事故發生之後,有不少人將矛頭指向了自動駕駛的人工智能是否足夠安全上,或者呼籲優步禁止自動駕駛。 然而更關鍵的問題在於,亞利桑那有著全美國幾乎最開放的自動駕駛政策,事故發生地坦佩市是實行自動駕駛最火的“試驗田”之一;事故所在的街區早已做過路線測試,並被 自動駕駛的智能採納。 但是在事故發生之後,對於責任的認定依然遇到了困難。
因為人的疏忽造成的車禍數不勝數,人們早已習慣瞭如何處理、怎樣追責;然而機器出錯了之後, 人們忽然手足無措。 人工智能會出錯嗎? 當然會。 只是我們在這個問題上一直缺乏認知。 就如同上文提到的“隱性歧視”,深度學習的“黑箱”,現有的法律法規很難對這些錯誤進行追究,因為不要說普通人,就連技術人員也很難找出出錯的 源頭。
當人工智能的決策在人類社會中越來越重要時,我們也不得不考慮,智能為什麼會犯錯,犯錯了怎麼辦;若要讓智能擺脫被商業或者政治目的支使的工具,真正成為人類的“夥伴 ”, 需要怎麼監管、如何教育,才能讓人工智能“不作惡”。

對此,現有的法律框架內很難有清晰的、可操作的實施方案。 歐盟率先在數據和算法安全領域做出了立法的嘗試,2018年5月即將生效的新法規規定,商業公司有責任公開“影響個人的重大決策”是否由機器自動做出,且做出的決策 必須要“可以解釋”。 但法條並沒有規定怎麼解釋,以及細到什麼程度的解釋是可以接受的。
另外一個重要的問題是, 讓機器求真求善,需要人類自己直面決策中的黑暗角落 。 在 Atari 遊戲智能的測試中,遊戲中的人工智能 bot 可以用最快的速度找到漏洞開始作弊,而遊戲玩家又何嘗不是呢? 不管是帶有歧視的語義分析,針對少數族裔進行的“智能監視”和跟踪,或者把已婚未育女性的簡歷扔掉的智能簡歷篩選,都長期以各種形式存在於人類社會中。
人工智能不是一個可預測的、完美的理性機器,它會擁有人類可能擁有的道德缺陷,受制於人們使用的目標和評估體系。 至少目前,機器依然是人類實然世界的反應,而不是“應然世界”的指導和先驅。 對機器的訓練同樣少不了對人性和社會本身的審視——誰在使用,為了什麼而使用,在我們的世界中扮演著怎樣的角色? 數據是誰給的,訓練的目標是誰定的? 我們期望中的機器,會繼承我們自己的善惡嗎?
谷歌中國人工智慧和機器學習首席科學家李飛飛認為, 要讓機器“不作惡”,人工智能的開發需要有人本關懷。 “AI 需要反映我們人類智能中更深層的部分,”李飛飛在《紐約時報》的專欄中寫道,“要讓機器能全面地感知人類思維……知道人類需要什麼。”她認為,這已經超越 了單純計算機科學的領域,而需要心理學、認知科學乃至社會學的參與。
未來,人工智能進入更多的領域、發揮更強的功能,是無可爭辯的事實。 然而,我們的生產關係能否適應人工智能帶來的生產力,這句馬克思政治經濟學的基本原則值得我們認真思考一番。 我們並不想看到未來的“機器暴政”將我們的社會綁在既有的偏見、秩序和資本操縱中 。
本文由 人間 Museum© 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/242589.html