“為什麼這個圖像識別的人工智能,老把男人認成女人?”
趙潔玉發現這個問題的時候,正摩拳擦掌地準備開始自己第一個獨立研究。 那時,她剛加入弗吉尼亞大學計算機系攻讀人工智能機器學習方向的博士,她的導師文森特•奧都涅茨扔給了她這個乍看有點哭笑不得的課題。

這年頭,面部識別其實已經不是很難的事情了,分辨男女更算不上什麼世紀難題,準確率應該很高才對。 當然,趙潔玉手頭的AI任務要稍微難一點兒,不是分辨證件照,而是要辨認場景複雜的生活照。 可就連相機裡的小小程序都能極為準確地找到畫面中的人臉而自動對焦,多點兒背景對AI來說能算什麼難題呢?
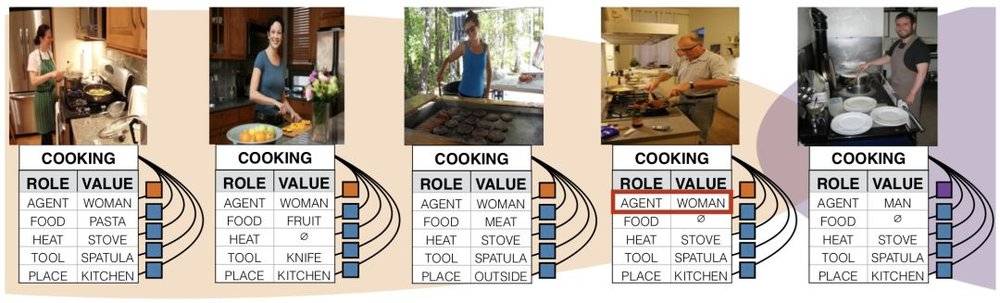
然而正是這些背景,以一種意料之外情理之中的方式扭曲了AI的“認知”。 趙潔玉發現,男人被認成女人的圖片有一些共同點——都是站在廚房裡,或者在做家務。
她很快意識到,這並不是程序bug,也不是識別算法或者特徵提取出了毛病,而是人工智能總把女人和某些特定的元素聯繫在一起,在下達判斷時被這些元素帶跑了 。 換句話說,這是一個會“性別歧視”的AI:它認為站在廚房裡的就“該”是女人。
這樣的歧視是怎麼產生的呢? 也很簡單。 如果你成長在一個“男主外、女主內”的社會,那麼你便會天然地認為女人就該操持家務。 AI也一樣,不過它“認識世界”的途徑也是歧視的來源,是它的“教學資料”—— 用於訓練人工智能進行圖像識別的數據庫。 關於性別的偏見不僅在數據庫里普遍存在,而且還會被人工智能所放大。
為什麼會出現這種情況? 怎麼解決? 趙潔玉和團隊圍繞著這兩個問題寫就的論文《男人也愛購物:使用語料庫級別的限制法降低性別偏差》在自然語言處理2017年的年會上獲得了最佳長論文獎,整個人工智能 領域也開始逐漸意識到這個問題。
數據庫的偏差從何而來?
趙潔玉和實驗室團隊選取了兩個具有代表性的圖像訓練數據集,一個是華盛頓大學開發的ImSitu,一個是微軟和Facebook等大公司支持的MSCOCO,每個數據集裡面都有超過10萬張圖片 。 他們發現,一些標籤和性別綁定的程度十分突出,比如站在廚房裡、做家務、照看小孩子的就被認為是女性,開會、辦公、從事體育運動的則是男性。 單個圖片看起來都很正常,然而大量的此類照片累積成了肉眼可見的偏見。 有超過45%的動詞和37%的名詞,會展現超過2:1的性別比例偏差。
性別歧視也僅僅只是偏見其中的一個方面。 一張來自印度海得拉巴的印式婚紗,在圖像識別的人工智能眼裡,成了歐洲中世紀的鎖子甲。 為什麼? 因為AI的概念裡婚紗是白色的西式婚紗,而並不“認識”第三世界的文化。

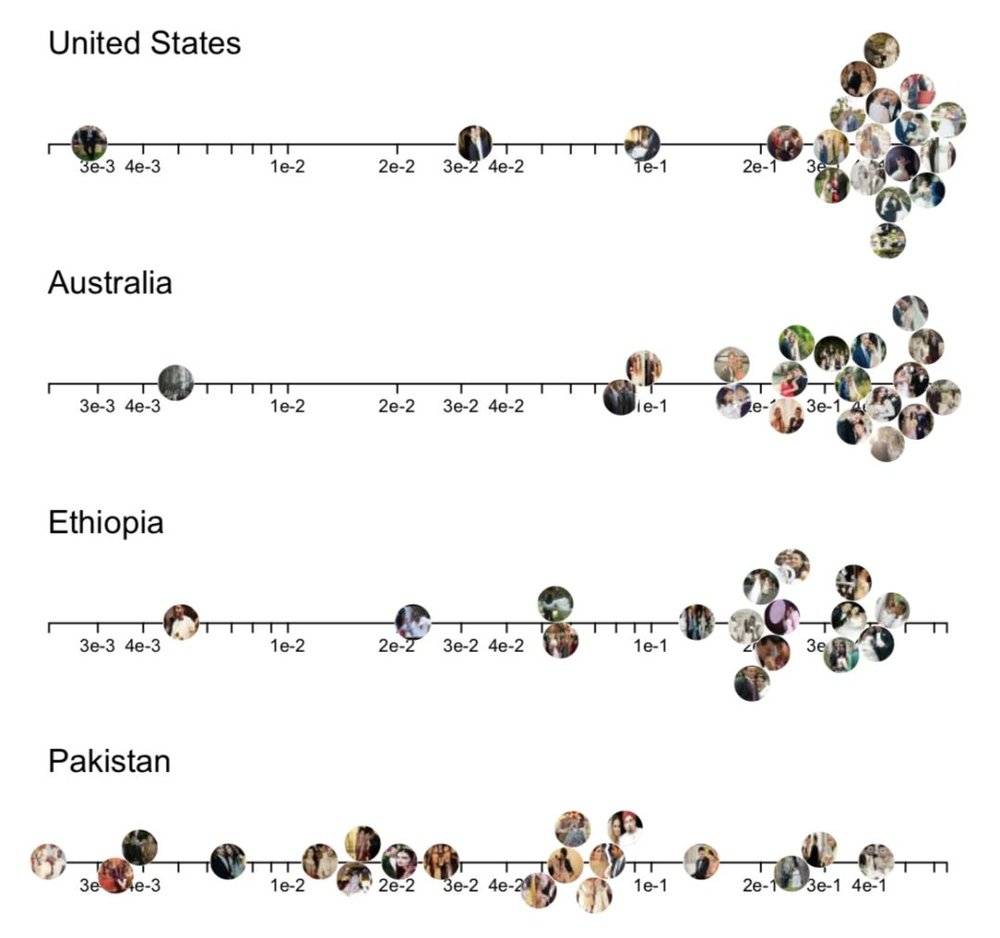
這是谷歌大腦實驗室成員、斯坦福大學的史蕾雅•珊卡爾的研究對象——目前最知名的圖像識別訓練數據集,擁有超過120萬張圖片的谷歌ImageNet。 她發現,用ImageNet訓練出來的人工智能,同樣是識別帶有“婚紗”元素的圖像,來自美國和澳大利亞的圖像準確率和置信度非常高——絕大多數圖片都能得到機器自信且正確的 答案;然而來自巴基斯坦和埃塞俄比亞的圖片則沒有這種待遇。 在識別美國和第三世界的圖像內容的時候,人工智能總是“選擇性失明”。
珊卡爾用地點標籤為這些數據做了分類,發現ImageNet的圖像,有45%來自美國,超過60%來自最主要的6個歐美國家。 而中國和印度加起來有全球三分之一的人口,卻只有數據集里區區3%的數據量。 在這樣的數據集訓練下的AI,在面對來自“第三世界”的任務時,就彷佛進了大觀園的劉姥姥,眼前全是稀奇事兒。
數據集的偏差,在形成的過程中就已經在積累了。
數據集的目的,是訓練機器進行圖像識別——例如ImageNet 的圖像就圍繞著1000多個類別展開,每一張圖片都有一個類別標籤。 但是為每個標籤選擇的圖像,卻會在無意中反映互聯網的刻板印象。 趙潔玉告訴我,大部分數據庫的圖片都來源於搜索引擎,然後再通過人工給這些圖片加上標籤,標註裡面都有什麼。 這樣做的原因很好理解:程序無法直接感知到現實事物,只能“看”到現成的數字化圖像,而互聯網搜索引擎應該是最不帶偏見、最誠實的圖像來源了吧?

但搜索引擎體現的“誠實”卻讓人驚愕——比如,在谷歌上搜“black girl”,第一屏有絕大部分都是色情圖;哈佛大學的計算機系教授拉譚雅•斯威尼 發現,在搜索引擎上搜典型的黑人名字,搜索引擎會有超過80%的概率在搜索建議裡提供“逮捕”、“犯罪”等詞彙,而沒有種族特徵的卻只有不到30%。 歸根結底,搜索引擎反應的並不是現實,而是它的使用者對現實的理解。 這些關於種族與性別的理解不可避免地天生就有值得商榷的內容——你以為你輸入的是“黑人”,但得出的內容卻是“黑人罪犯”。
“數學上沒有所謂‘公平’的概念,”英國巴斯大學計算機系教授喬安娜•布萊森說,“偏見,只是機器從數據中拾取的規律而已。 ”在人工智能和機器學習的範疇裡,“偏見”並不是一個帶有價值判斷的詞彙。 然而,在涉及到現實應用的領域,情況就不一樣了。 現在的機器,當然不具備體會情感或者故意施加偏見的能力,只是誠實地反映了數據庫乃至社會中真實存在的偏見,而這些反映有時候並不是我們想要的。

更關鍵的問題在於,現有的機器訓練方式,很可能會放大這些偏見和歧視。
機器如何放大數據庫的偏見?
你可能有這樣的經歷:剛在購物網站上購買了5kg的洗衣液,推薦算法就在“你可能喜歡”的側欄裡,給你推薦8個品牌25種其它洗衣液——“這是要 我開洗衣店”?
大規模商業應用的推薦算法不夠“智能”也許有其苦衷,但哪怕學術界頂尖的技術也難逃類似的坑:算法似乎太過在意你的輸入,把原始數據太當真了。 如果數據質量很高,那自然不是問題;但現在原始數據裡已經有了偏見,算法就會進一步把它放大。
趙潔玉團隊用MSCOCO和ImSitu數據集訓練的人工智能,在對一般的圖片進行預測的時候,會體現出比數據集本身更大的偏差——比如,在imSitu數據集中,“下廚”和女性聯繫 起來的頻率為66%,男性有33%;然而,被這個數據集訓練過的人工智能,預測下廚和女性聯繫起來的比率被放大到了84%,男性則只有區區16%。

為什麼呢? 她在研究中使用的算法模型,一方面直接通過辨認圖像的特徵,提取圖像裡的元素標籤,另一方面會根據各個標籤之間的聯繫來判定究竟哪個元素出現的概率最大,這也是大信息 量的圖像識別中十分常用的思路。 而問題就在於, 如果要通過現有的聯繫來進行識別,那麼機器可能會在訓練中將現有的聯繫誇大,從而在不那麼確定的情況下,給出一個更可能靠近“正確答案”的結果。
趙潔玉給我打了個比方:“當算法只通過圖像裡的特徵來判定,給出的預測是有50%的可能圖片裡面是男性,但也有50%可能是女性;但在訓練它的數據庫中 ,有90%的圖片都將女性和廚房聯繫在一起。那麼綜合圖像特徵、聯繫兩方面信息之後,機器便會得出結論,說圖片裡是女性。”
機器容易犯的另外一個錯是將大部分數據的特徵當做一般的特徵來處理——上文中用ImageNet訓練出來的數據庫就很可能犯“美國加歐洲就是全世界”的錯誤。 這會對數據中的少數非常不利。 如果讓AI判斷一個人是男人還是女人,而用於訓練這個AI的數據庫裡有98%的男人,只有2%的女人。 經過訓練的AI即使可以識別所有男人、完全不管那2%的女人,那也能有98%的準確度。 但是那2%的女人,對機器就等同於不存在了。
而如果不管不顧實際情況,只埋頭訓練的話,能將現有數據庫的偏差誇張到什麼程度呢? 來自MIT和卡耐基梅隆大學的兩個學者訓練了一個AI,它能夠通過不同數據庫的風格和內容,識別來自不同數據庫的圖片,比如Caltech101裡的汽車都是橫著的,MSRC裡常常是寬闊的草坪 上擺著一個物體。 這意味著,若一個數據庫裡面出現了哪怕一點點的偏見,也會被算法忠實地反映出來,誇大到一般情況中——用Caltech101訓練出來的AI,一定認為世界上絕大部分的車都是 橫著的才“正常”。

這在技術領域被稱為“過擬合”,很大程度上和人工智能的訓練方式有關。 MIT和卡耐基梅隆的研究者認為,現在的圖像識別開發者,往往會陷入盲目追求“準確度”的陷阱裡去。 訓練出來的模型,在某一個數據庫上的精確度可以達到非常高,從而給人“我的AI特牛逼”的錯覺,然而在現實中難免會吃癟。 這就好比我本來是個臉盲,又恰好是日本大型偶像組合AKB48的忠實粉絲,裡面的幾百個妹子我都認識;但是把我放到一般人群中,我又兩眼一抹黑,只好對著 剛認識不久的人露出陌生的微笑。 長期泡在年輕妹子裡,對老年人和男性的識別能力反而降低了。
誠然,在AI訓練的過程中,數據可以說是最重要的一環。 但數據不是萬能的,對數據的洞察同樣關鍵。 “ 從大量的數據中挖掘並洞察人性 ”——這是趙潔玉的導師奧都涅茨的興趣所在。只有這樣,才能從根本上提高機器在人類社會中工作的能力。
人或許是機器最大的局限
社會的信息化、互聯網的飛速發展給我們帶來了海量的數據,你想得到的、想不到的,都被機器清清楚楚地掌握著。 在你打開社交網站的時候,機器就把合適的廣告推到了你面前,只因為你前一天用谷歌搜索了這個產品的信息;上傳照片到Facebook,你和你的朋友都會被自動打上標籤,只 因為面部識別算法早已悄悄掃描過了有你們的每一幅照片。

然而,對於數據的挖掘和理解,始終有著各種各樣的局限。 機器的錯誤、歧視和偏見也來自“缺根筋”的人—— 技術人員擁有了大量的數據,用機器強大的運算能力調教出了精妙的算法,但卻對數據、乃至數據背後的社會現實缺乏考慮。
珊卡爾舉了一個讓人啼笑皆非的例子——她所在的斯坦福計算機系的一個教授開發了一個聲稱能夠“通過面部特徵識別同性戀”的人工智能。 消息傳出,社會上一片嘩然。 且不論這個算法若是放入現實中,會為歧視和偏見提供怎樣的方便;關鍵是這個人工智能在現實中真的成立嗎? “這位教授使用的數據,都來自在調查里公開出櫃的人,還有大量的同性戀根本沒有公開自己的性向。”珊卡爾在一篇博文中寫道,“ 如果想要辨識一個人是否真的是生物意義上的同性戀,這個算法沒有任何意義 。 ”
另一個例子是,一個醫療團隊使用AI輔助診斷病人的血液樣本,但卻發現AI診斷出陽性結果的數量大大超出了預料。 難道其實人人都有病? 結果卻令人啼笑皆非:數據庫使用健康志願者的血液作為對照,但這些志願者幾乎都是年輕的大學生,而醫院裡的病人年齡明顯偏大。 最後,人工智能把老年血當成了有病的血。 這樣的錯誤人類也會犯,但只需上幾門醫學統計學的課程就可糾正;教會AI懂得這種偏差,卻彷彿遙遙無期。
這還僅僅是學術領域的問題,現實中關於數據庫的棘手事兒更多。 “在機器學習研究的領域裡,數據庫還是相對比較’乾淨’的,”一名在人工智能領域供職的朋友對我說,“各種類型的數據都比較理想化,比如圖片的標籤、圖片的 分類等等,都相對規範。然而在商業領域採集到的數據,很多都非常潦草,訓練出來的算法也有很大問題。”商業公司要么購買昂貴的數據庫,要么就花上大量的人力手動打標籤 ,從這個角度上講,人工智能的背後,其實一點也不智能。 “ 垃圾進,垃圾出”,是業界對於糟爛數據庫訓練出糟爛智能的吐槽——很多時候,甚至是自嘲。
這些進入商業應用的人工智能使用了什麼樣的數據庫? 數據庫中的偏見是否會影響人工智能的判斷? 數據庫如何收集數據,如何標註已有的偏見,業界有沒有標準? 社會對此缺乏相應的考察,而機器學習本身也存在著大量不透明的境況,特別是在神經網絡“無監督學習”的發展趨勢下,連開發者自己都不知道自己的 AI 究竟在幹什麼。
我們不知道一個進行簡歷篩選的智能,會不會將女性的簡歷扔進垃圾堆;也不知道給一個人的借貸信用打分的人工智能,是否會將出生地作為黑歷史納入考慮。 作為一個希望在計算機領域發展的女性,趙潔玉也會擔心這樣的問題。 “如果你用歷年計算機系的入學數據訓練一個人工智能,”她說,“那麼機器一定會得出‘女性成不了優秀的計算機工程師’的結果,這對女工程師來說非常不公平。”

而少數族裔、少數團體所面臨的尷尬,就如同珊卡爾的研究中的海得拉巴婚紗一樣——被主流數據庫訓練出來的人工智能,對少數群體的情況往往兩眼一抹黑。
現實中,大量的智能應用都誕生自灣區——這是一個經濟極其發達的城市帶,開發者大部分是白人中青年男性,而這個小小的地方,正決定著服務整個世界的人工智能 的數據和算法。 國內北上廣深杭的互聯網從業者,也難免對三四線城市和鄉村充滿了輕蔑,一廂情願地相信著大城市的社會規律。 而結果卻是,那些沒有話語權的群體和地域,可能會在將來更加嚴重地被邊緣化,這並不是開放、平等的互聯網最初所期冀的結果。
給機器一個公平的未來?
“沒有事實上的技術中立。對機器來說,中立的就是佔統治地位的。” 劍橋大學未來研究所教授魯恩•奈如普如是說。 人工智能並不能從數據中習得什麼是公平、什麼是美德,也不懂什麼是歧視、什麼是醜惡。 說到底,我們現在的人工智能,還遠遠沒到理解“抽象”的地步。
被人類盲目追捧的機器,似乎不會“犯錯”——這是因為機器是穩定的,只會出現“異常”。 但這種異常,其實就是一直固執不停地犯錯。 如何避免呢? 這也跟人類的教育有相似之處——提供更好的教材,或者老師需要格外注意教學方式。 毫無疑問,我們需要更好的,盡可能減少偏見的數據庫;然而得到面面俱到、沒有偏差的數據庫非常困難而且成本高昂。 那麼訓練人工智能的技術人員,能夠對可能的偏差有所認識,並用技術方式去調整、彌合這個偏差,也是十分必要的。

趙潔玉正在做的研究,就是如何調偏。 她設計的算法,會衡量數據庫的性別元素和偏見狀況,並用它來糾正識別的預測結果。 在這個糾偏算法的幫助下,機器在性別方面的識別偏見減少了40%以上。
而在糾偏的研究中,趙潔玉也慢慢領會了一個技術人員與社會公平之間的聯繫。 她自認並不是那類積極在社交網絡上參與政治議題的年輕人,但卻會更多地在技術領域注意到數據中的“少數”,思考他們是否得到了數據和算法的一視同仁。 “ 你的算法表現好,是不是因為優勢群體強大? 弱勢群體在你的算法中被考慮到了嗎? ”趙潔玉說。
而從根本上說,那些被機器無意拾取的偏見,都以性別刻板印象的形式,長期存在於我們周圍,需要我們保持審視的態度。 作為一個從事人工智能研究的女性,即使已經走入了領域最頂尖的學府深造,卻依舊會面對別人詫異的目光。 “經常會聽到別人說,‘女孩子學CS,一定很辛苦吧’。”趙潔玉對我說。 這些無心的、甚至是讚揚的話,卻讓自己聽了覺得不對勁,“明明大家都是一樣的啊。”

的確,我們需要不厭其煩告訴機器的或許也需要不厭其煩地告訴我們自己。
參考文獻:
本文由 果殼© 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文請於文首標明作者姓名,保持文章完整性(包括虎嗅注及其餘作者身份信息),並請附上出處(虎嗅網)及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/258405.html
未按照規範轉載者,虎嗅保留追究相應責任的權利