全文如下:
寫在前面
有一次在Facebook上,我發表了這樣一段話:
任何時候,如果有人問我強化學習能不能解決他們的問題,我都會告訴他們,不行。 而且70%的情況下我都是對的。

深度強化學習被大量的炒作重重包圍。 這並不是無緣無故的! 強化學習是很奇妙的一種範式,原則上,一個魯棒且高性能的RL系統應該是可以完成一切任務的。 將這種範式與深度學習的經驗力量相結合明顯是最佳搭配。 深度RL看起來是最接近通用人工智能的系統之一,而打造AGI這一夢想已經消耗了數十億美元的資金。
不幸的是, 目前深度強化學習仍然不起作用。
當然,我相信它是有用的。 如果我不相信強化學習,我也不會研究它。 但是研究過程中也出現了很多問題,而且大部分都很難解決。 智能體agent光鮮亮麗的演示背後,是大家看不到的無數鮮血、汗水和淚水。
我已經看到過很多次人們被這個領域的研究所誘惑。 他們只不過第一次嘗試深度強化學習,並且剛好沒遇到問題,於是就低估了深度RL的難度。 如果不經歷失敗,他們不會知道這到底有多難。 深度RL會持續不斷地打擊他們,直到他們學會如何設定符合現實的研究期望。
這不是任何人的錯,而是一個系統性問題。 如果結果是好的,自然什麼都好說,但如果結果不太好,還想寫出同樣精彩的故事就沒那麼簡單了。 問題是,負面的結果才是研究人員最經常遇到的。 在某些方面,負面案例其實比正面案例更重要。
在後面的內容中,我將解釋為什麼深度RL沒有起到作用,什麼情況下它能起到作用,以及它如何在未來變得更可靠。 我並不是為了讓人們停止研究深度RL才寫這篇文章。 我這樣做是因為我相信如果大家一起找到問題所在,就更容易在這些問題上取得進展。 如果大家聚在一起討論這些問題,而不是每個人自己一次又一次地掉進同樣的坑里,就能更容易取得一致的意見。
我希望看到深度RL研究有更好的發展,有更多的人進入這個領域。 但我也希望人們了解他們即將要面臨的到底是什麼。
在本文中,“強化學習”和“深度強化學習”相互替代使用。 我批判的是深度強化學習的經驗主義行為,並不是批判強化學習整體。 我引用的論文通常用深度神經網絡作為agent。 雖然經驗批判主義可能適用於線性RL或tabular RL,但我不確定它們是否能推廣到更小的問題。 在巨大、複雜、高維的環境下,良好的函數逼近是十分必要的,RL在這種環境下的良好應用前景推動了對深度RL的炒作。 這種炒作是目前需要解決的問題之一。
這篇文章的走向是從悲觀到樂觀,雖然文章很長,但是如果你耐心閱讀,我相信你一定會有所收穫。
下面首先介紹深度RL的失敗案例。
深度強化學習的樣本效率可能極低
深度強化學習最經典的實驗基準是Atari遊戲。 在著名的深度Q網絡論文中,如果你將Q學習、大小合適的神經網絡和一些優化技巧結合,就可以讓網絡在一些Atari遊戲中達到甚至超越人類水平。
Atari遊戲的運行速度是每秒60幀,你能估算出最先進的DQN想要達到人類的水平,需要多少幀嗎?
這個問題的答案取決於遊戲的種類,我們來看看Deepmind最近的一篇論文,Rainbow DQN。 這篇論文用模型簡化法研究了對於原始DQN結構的幾種改進,證明了將所有的改進結合起來可以達到最好的結果。 在57種Atari遊戲測試中,該模型在40種遊戲中超過了人類的表現。 下圖展示了實驗結果。
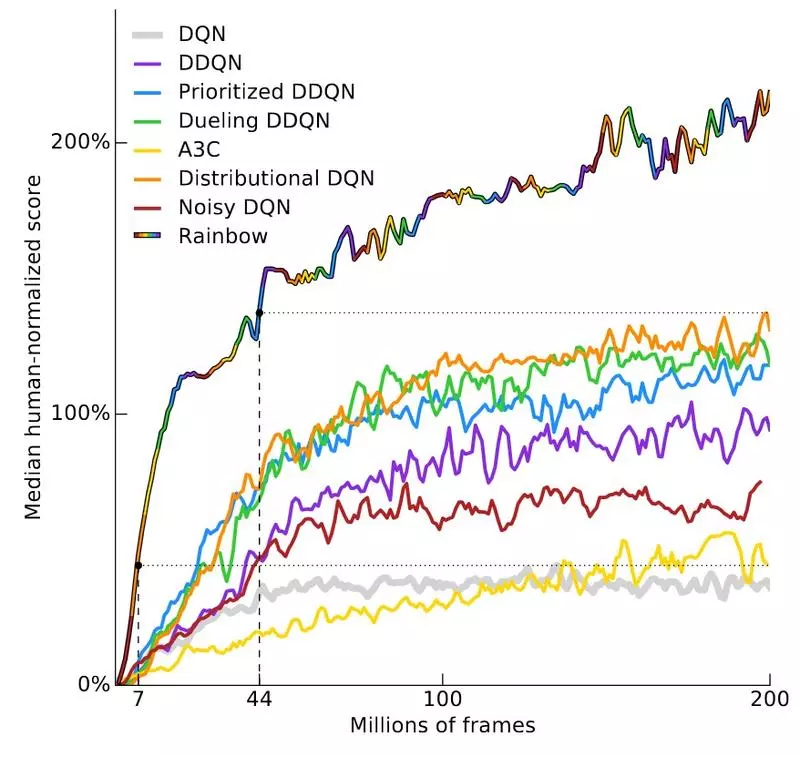
Y軸是“人類標準化分數中值”,是通過訓練57個DQN ,並以人類表現為100%,對agent的表現進行標準化得到的。 以此為基礎繪製了57場遊戲表現的中位數。 在1800萬幀時,RainbowDQN的表現超過了100%的閾值。 這相當於大約83小時的遊戲體驗,再加上訓練模型所需的時間,而大多數人玩通一個Atari遊戲只需要幾分鐘。
請注意,1800萬幀其實已經很少了,考慮到之前的方法需要7000萬幀才能達到與人類相當的水平,是RainbowDQN所需時間的4倍。 至於,它永遠無法達到100%的性能,即使經過2億幀之後。
規劃謬誤論認為完成某件事花費的時間通常比你想像的要長。 強化學習有它自己的規劃謬誤——學習一個policy需要的樣本通常比你以為的更多。
這個問題不只在Atari遊戲中出現。 第二常見的基準實驗是MuJoCo,是設置在MuJoCo物理模擬器中的一組任務。 在這些任務中,輸入狀態通常是一些模擬機器人每個關節的位置和速度。 即使不用解決視覺問題,學習這些基準也需要10^5到10^7個步驟。 對於這樣一個簡單的環境,這一數字可以說是很大的經驗量了。
DeepMind的跑酷論文,用64個機器訓練了超過100個小時來學習policy。 論文中沒有說明“機器”是什麼,但我認為應該是指1個CPU。
論文結果很酷。 剛看到這篇論文時,我沒想到深度RL竟然可以學習這些奔跑的步態。
不過與此同時,需要6400個CPU時的事實讓人有點沮喪。 並不是因為我沒想到它需要這麼多的時間,而是深度RL仍然比實際應用級別的樣本效率低了幾個數量級。
這裡有一個明顯的對比:如果我們直接忽略樣本效率呢? 有幾種情況很容易獲取經驗,比如游戲。 但是,在這一點不成立的情況下,RL面臨著一場艱苦的戰鬥,而且不幸的是,現實世界中的大多數情況就屬於這類。
如果你只關心最終的性能,許多問題更適合用其他方法解決
在尋找任何研究問題的解決方案時,通常會在不同的目標之間進行權衡。 優化的目標可以是一個真正好的解決方案,也可以是良好的研究貢獻。 最好的情況是獲得一個好的解決方案的同時需要做出好的研究貢獻,但是很難找到符合這個標準並且可行的問題。
如果純粹為了獲得好的表現,深度RL的記錄可能就沒那麼光鮮了,因為它總是被其他方法打敗。 這是一個MuJoCo機器人的視頻,用在線軌跡優化控制。 正確的動作是在近乎實時、在線,而且沒有離線訓練的情況下計算的。 而且它運行在2012年的硬件上。
我認為這篇論文可以和那篇跑酷論文相提並論。 那麼兩者之間的區別在哪裡呢?
區別在於,Tassa等人利用模型預測控制,可以用真實世界模型來進行規劃。 而無模型的RL不進行這樣的規劃,因此難度更大。 另一方面,如果對模型進行規劃有所助益,那為什麼要把問題複雜化,去訓練一個RL策略呢?
同理,用現成的蒙特卡洛樹搜索就可以很容易地超越DQN在Atari遊戲中的表現。 下面是Guo et al, NIPS 2014論文中給出的基準數字。 他們把一個訓練好的DQN的分數和UCT agent的分數做對比。


這並不是一個公平的對比,因為DQN沒有搜索步驟,而MCTS能夠用真實模型進行搜索。 然而有時候人們不在乎對比是否公平,人們只在乎它的有效性。 如果你對UCT的全面評估感興趣,可以看看原始的 論文附錄。
強化學習理論上可以用於任何事物,包括模型未知的環境。 然而,這種普遍性是有代價的:算法很難利用特定信息來幫助學習,這迫使人們使用多到嚇人的樣本來學習本來通過硬編碼就可以得到的規律。
無數經驗表明, 除了極少數情況,特定域的算法均比強化學習的表現更快更好。 如果你只是為了深度RL而研究深度RL,這不成問題,但是每當我把RL與其他任何方法進行對比時,都會覺得十分沮喪,無一例外。 我非常喜歡AlphaGo的原因之一就是因為它代表了深度RL的一次毋庸置疑的勝利,而這樣的勝利並不常見。
這一點讓我越來越難給外行解釋為什麼我研究的問題又酷又難又有趣,因為他們往往沒有背景或經驗來理解為什麼這些問題這麼難。 人們所認為的深度RL能做什麼,和它真正能做什麼之間橫亙著一個巨大的“解釋鴻溝”。 我現在研究的是機器人。 當你提到機器人時,大多數人們想到的公司是波士頓動力。
視頻3:https://v.qq.com/x/page/t05665fb4lk.html
他們可不使用強化學習。 如果你看看該公司的論文,你會發現論文的關鍵字是時變LQR,QP求解以及凸優化。 換句話說,他們主要用的還是經典的機器人技術,而實際結果證明,只要用對了這些經典技術,它們就可以很好地發揮作用。
強化學習通常需要獎勵函數
強化學習一般假定存在獎勵函數。 通常是直接給定的,或者是離線手動調整,然後在學習過程中不斷修正。 我說“通常”是因為也有例外,例如模仿學習或逆RL,但大多數RL方法把獎勵函數奉為神諭。
更重要的是,想讓RL做正確的事,獎勵函數必須知道到底你想要什麼。 RL有過擬合獎勵函數的傾向,會導致意想不到的結果。 這就是為什麼Atari遊戲是一個很好的基準。 不僅是因為很容易從中獲得大量的樣本,而且是因為每場比賽的目標都是盡可能地得分,所以永遠不用擔心該如何定義獎勵函數,而且每個系統都用相同的獎勵函數。
這也是MuJoCo任務很受歡迎的原因。 因為它們在模擬器中運行,所以你清楚地知道所有的對象狀態,這使得獎勵函數的設計容易許多。
在Reacher任務中,需要控制一個連接到中心點的兩段臂,任務目標是移動手臂到指定位置。 下面是一個成功學習出策略的視頻。
視頻4:https://v.qq.com/x/page/z0566wbrs89.html
因為所有的位置都是已知的,所以獎勵函數可以定義為從手臂末端到目標的距離,再加上一個小的控制損失。 理論上來說,在現實世界中,如果你有足夠的傳感器來獲取環境中精確的位置,你也可以這樣做。
就其本身而言,需要獎勵函數不算什麼,除非……
獎勵函數設計難
增加一個獎勵函數並不難。 困難的是如何設計一個獎勵函數,讓它能鼓勵你想要的行為,同時仍然是可學習的。
在HalfCheetah環境中,有一個雙足機器人被限制在一個垂直平面內,只能向前跑或向後跑。
任務目標是學習跑步的步態。 獎勵函數是HalfCheetah的速度。
這是一個計劃獎勵函數,也就是說在狀態離目標越來越近時,它增加獎勵。 另一種是稀疏獎勵,即達到目標狀態才給予獎勵,而其他狀態都沒有獎勵。 計劃獎勵往往更容易學習,因為即使策略沒有找到問題的完整解決方案,系統也會提供正反饋。
不幸的是,計劃獎勵可能會影響學習,導致最終的行為與你想要的結果不匹配。 一個很好的例子就是賽龍舟遊戲,預定的目標是完成比賽。 可以想像,在給定的時間內完成比賽,稀疏獎勵函數會+1獎勵,而其他情況都是0獎勵。
但遊戲給出的獎勵是只要到達關卡點就會加分,並且收集道具也會加分,而且收集道具給的分數比完成比賽得到的還多。 在這樣的獎勵函數下,RL系統的agent即使沒有完成比賽,也能拿到最高得分。 因此也導致了許多意想不到的行為,例如agent會撞毀船、著火、甚至走反方向,但它獲得的分數比單純完成遊戲還要高。
RL算法是一個連續統一體,他們可以或多或少地了解他們所處的環境。 最常見的無模型強化學習,幾乎與黑盒優化相同。 這些方法只有在MDP中才能求解出最優策略。 agent只知道哪個給了+ 1獎勵,哪一個沒有,剩下的都需要自己學習。 和黑盒優化一樣,問題在於對agent來說,任何給予+1獎勵的都是好的,即使+1的獎勵不是因為正確的理由而得到的。
一個經典的非RL例子是應用遺傳算法設計電路的時候,得到的電路中出現了一個無連接的邏輯門。
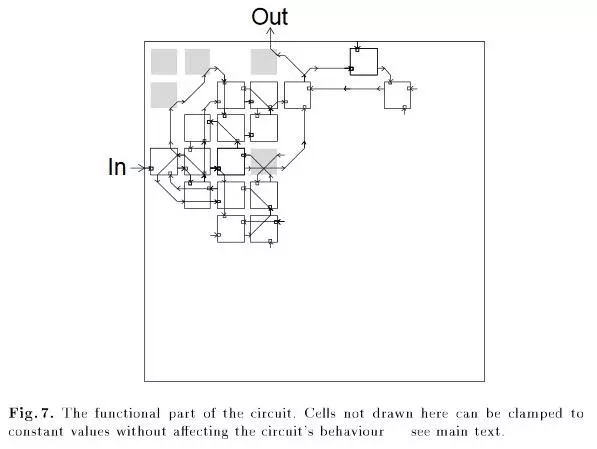
所有的灰色單元都要有正確的行為,包括左上角的,即使它沒有跟任何單元連接起來。 (來自“An Evolved Circuit, Intrinsic in Silicon, Entwined with Physics”)
更多的例子可以參考Salesforce 2017年的博客,它們的目標是文本總結。 它們的基準模型用監督學習訓練,然後用自動度量方法ROUGE對總結效果進行評估。 ROUGE是不可微的,但是RL可以解決不可微的獎勵,所以他們嘗試直接用RL來優化ROUGE。 得到了很高的ROUGE分數,但是實際效果並不是很好。 下面是一個例子:
Button was denied his 100th race for McLaren after an ERS prevented him from making it to the start-line. It capped a miserable weekend for the Briton. Button has out-qualified. Finished ahead of Nico Rosberg at Bahrain. Lewis Hamilton has. In 11 races. . The race. To lead 2,000 laps. . In. . . And.
所以儘管RL模型得到了最高的ROUGE評分:
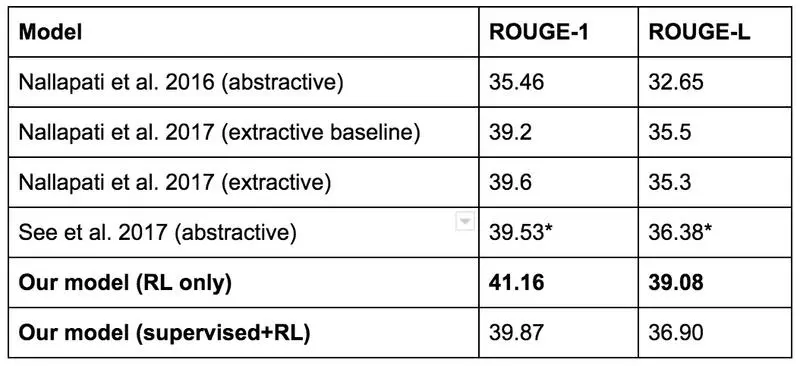
他們最後還是用了另外一個模型。
還有另一個有趣的例子:Popov et al, 2017的論文,也被稱為“樂高積木論文”。 作者用分佈式DDPG來學習抓握策略,目標是抓住紅色塊,並把它堆在藍色塊的上面。
他們完成了這個任務,但中途遇到了一個徹底失敗的案例。 他們對於初始的抬升動作,根據紅塊的高度給出獎勵,獎勵函數由紅塊底面的z軸坐標定義。 其中一種失敗模式是,策略學習到的行為是把紅塊倒轉過來,而不是撿起來。
顯然這並不是研究人員預期的解決方案,但是RL才不在乎。 從強化學習的角度來看,它因為翻轉一個塊而得到獎勵,所以它就會將翻轉進行到底。
解決這個問題的一種方法是給予稀疏獎勵,只有機器人把這個塊堆疊起來後才給予獎勵。 有時候這樣能行得通,因為稀疏獎勵是可學習的。 但通常情況下卻是沒用的,因為缺乏正向強化反而會把所有事情複雜化。
解決這個問題的另一種方法是仔細地調整獎勵函數,添加新的獎勵條件,調整現有的獎勵係數,直到你想學習的行為在RL算法中出現。 這種方法有可能使RL研究取得勝利,但卻是一次非常沒有成就感的戰鬥,我從來沒覺得從中學到過什麼。
下面給出了“樂高積木”論文的獎勵函數之一。
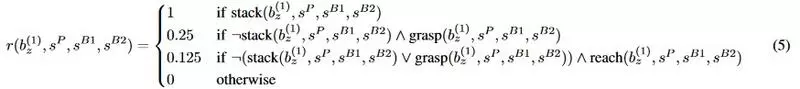
我不知道他們到底花了多少時間來設計這個獎勵函數,但是根據術語的數量和不同係數的數量,我猜是“相當多”。
在與其他RL研究人員的交流中,我聽到了一些趣聞,是由於獎勵函數定義不當而造成的新奇行為。
有位同事正在教一個agent通過一個房間。 如果agent離開邊界,這一事件就終止了。 他沒有對事件的這種結束方式加任何懲罰。 結果最後學到的policy是自我毀滅式的,因為消極的獎勵太豐富了,而積極的獎勵很難獲取,在agent看來,快速死亡以0獎勵結束,比長時間活動可能造成負獎勵更可取 。
一位朋友正在訓練一個模擬機械手臂伸到桌子上方的某個點。 這個點是根據桌子定義的,而桌子沒有固定在任何東西上。 agent學會了重重地拍桌子,使桌子翻倒,這樣一來它也算移動到目標點了。 而目標點正好落到了機械臂的末端。
一位研究人員在使用RL訓練模擬機器手臂拿起錘子並把釘子釘進去。 最初,獎勵定義為釘子被釘到洞裡的深度。 結果,機器人沒有拿起錘子,而是用自己的四肢把釘子釘進去了。 於是研究人員增加了獎勵項,鼓勵機器人拿起錘子,然後重新訓練策略。 雖然他們得到了拿起錘子的策略,但是機器人只是把錘子扔在了釘子上而不是使用錘子。
誠然,這些都是“聽別人說的”,但是這些行為聽起來都很可信。 我已經在RL的實驗中失敗了太多次,所以我不會再懷疑這一點。
我知道有人喜歡用回形針優化器的故事來危言聳聽。 他們總喜歡猜測一些特別失調的AGI來編造這樣的故事。 現在每天都有很多真實發生的失敗案例,我們沒有理由去憑空想像那樣的故事。
即使獎勵函數設計得很好,也很難避免局部最優解
前文給出的RL例子有時被稱為“獎勵作弊”。 正常情況下,AI會通過正常的手段最大化獎勵函數。 然而,有些情況下,AI可以通過作弊的手段,直接把獎勵函數調到最大值。 有時一個聰明的、現成的解決方案比獎勵函數設計者所預期的答案能得到更多的獎勵。
獎勵作弊是一個例外,更常見的情況是由於探索-利用權衡不當而導致的局部最優解。
下面是一個歸一化優勢函數的實現視頻,在HalfCheetah環境中學習。
在局外人看來,這個機器人太蠢了。 但是這是因為我們站在第三方的視角,而且我們知道用腳跑步要好得多。 但是RL並不知道啊! 它收到狀態,然後做出行動,然後知道它得到了正向獎勵,就是這樣。
我猜測學習過程發生了以下幾件事:
在隨機探索階段,策略發現向前倒比靜止站著要好。
於是策略記住了這個動作,然後持續向前倒。
向前倒之後,策略了解到,如果一次性施加很大的力,它會做一個後空翻,並且得到獎勵。
於是它試了一下後空翻,很自信這是一個好主意,然後策略牢牢記住了要多做後空翻。
當策略連續後空翻時,哪種方法對策略來說更簡單呢? 學習糾正自己然後按“標準方法”跑還是學會躺著跑呢? 我想應該是第二種更簡單吧。
下面是另外一個失敗示例,來自Reacher項目:
在這個過程中,初始隨機權重傾向於輸出高度正或高度負的動作輸出。 這使得大多數動作盡可能輸出最大或最小加速度。 超高速旋轉非常容易:只需要每個關節輸出高強度的力。 一旦機器人開始行走,就很難以一種有意義的方式脫離這一策略——想要脫離這個策略,必須採取幾個探索步驟來阻止混亂的旋轉。 這當然是可能的,但在這次試驗中並沒有發生。
這些都是一直以來困擾強化學習的經典的探索-利用問題。 由於數據來自於當前的策略,如果當前的策略探索太多,得到的是垃圾數據,那就什麼也學不到;如果利用太多,智能體也無法學到最優行為。
有幾個不錯的想法可以解決這個問題——內在動機、好奇心驅動探索、基於計數的探索等等。 這些方法中有許多是在80年代或更早的時候提出的,其中有幾個在深度學習模型中重新得到應用。 然而,據我所知,沒有一個方法能在所有環境中持續奏效,他們總是有時有用,有時沒用。 如果有一個到處都能奏效的探索技巧,那就太好了,但我認為這種萬能技術在很長一段時間內都不能實現。 不是因為人們沒有嘗試,而是因為探索-利用困境真的太難了。
引用維基百科的一段話:
“最初二戰中盟軍的科學家認為,這個問題太棘手了,應該丟給德國,讓德國科學家也浪費自己的時間。”
我將深度RL想像成一個惡魔,故意曲解你的獎勵函數,然後積極尋找最懶的可行局部最優解。
當深度RL有效時,它可能過擬合環境中奇怪的模式
“深度RL廣受歡迎的原因是它是機器學習中唯一允許在測試集上進行訓練的研究領域”
強化學習的好處是:如果你想在一個環境中表現很好,可以隨意的過擬合。 缺點是,如果你想推廣到其他環境中,可能表現會很差。
DQN可以解決很多雅達利遊戲,但它是通過對單一目標進行集中學習來完成這項任務的——它只在某一個遊戲的表現很好。 但最後學習到的模式無法推廣到其他遊戲,因為它沒有經過這種訓練。 你可以通過微調訓練好的DQN,讓它去玩新的雅達利遊戲,但也不能保證它能夠遷移,而且人們通常不期望它能遷移。
原則上在各種各樣的環境下進行訓練應該能使這些問題消失。 在某些情況下,可以輕易得到這樣的環境。 例如導航,可以在環境中隨機採樣目標位置,並使用通用值函數來泛化。 這是一項很有前途的研究,然而我不認為深度RL的泛化能力足以處理不同的任務。 OpenAI Universe 試圖用分佈式來解決這個任務,但據我所知,目前他們也沒有太多進展。
除非RL系統達到了那樣的泛化能力,否則agent所學習到的策略應用範圍會一直受限。 舉一個例子, 想一想這篇論文:Can Deep RL Solve Erdos-Selfridge-Spencer Games? Raghu et al, 2017。 我們研究了一個雙玩家組合遊戲,玩家的最佳發揮有封閉形式的解析解。 在第一個實驗中,我們固定了玩家1的行為,然後用RL訓練了玩家2。 這樣可以將玩家1的行為視為環境的一部分。 在玩家1的表現最優時訓練玩家2,我們發現RL可以達到高性能。 但是當我們針對非最佳玩家1部署相同的策略時,它的性能下降了,因為它不能泛化到非最佳對手的情況。
Lanctot et al, NIPS 2017中給出了類似的結果。 有兩個agent在玩激光槍戰。 這兩個agent採用多智能體強化學習進行訓練。 為了測試泛化能力,他們用5個隨機種子進行訓練。 下面是互相訓練的agent的視頻。
可以看到,他們學會了朝對方走並且射擊對方。 然後他們從一個實驗中取出玩家1,從另一個實驗中取出玩家2,讓他們互相對抗。 如果學習到的策略可以泛化,應該能看到與之前類似的行為。
但是並沒有。
這似乎是多智能體RL的主題。 當agent相互訓練時,會產生一種協同進化。 agent變得特別擅長攻擊對方,但當他們對付一個之前沒有遇到過的玩家時,表現就會下降。 需要指出的是,這些視頻之間唯一的區別是隨機種子。 它們都有同樣的學習算法,相同的超參數,但是發散行為完全來自於初始條件下的隨機性。
話雖如此,競爭性自我遊戲環境產生了一些很好的結果,似乎跟這一點互相矛盾。 OpenAI有一篇文章介紹了他們在該領域的工作。 自我競爭也是AlphaGo和AlphaZero算法的重要組成部分。 我認為,如果agent以同樣的速度學習,他們可以不斷地挑戰對方,加快彼此的學習,但是如果其中一個學得更快,它會過度利用較弱的選手,導致過擬合。 當你將環境從對稱的自我競爭放鬆到一般的多智能體時,更難確保學習能以同樣的速度進行。
即使忽略泛化問題,最終結果也可能不穩定而且難復現
幾乎每一個ML算法都有超參數,它們會影響學習系統的行為。 通常,超參數都是人工挑選的,或者是隨機搜索得到的。
監督學習是穩定的,有固定的數據集和真實值目標。 如果你稍微改變超參數,算法的表現不會改變很多。 並不是所有的超參數都表現良好,但有了過去幾年發現的所有經驗技巧,許多超參數在訓練中可以進行優化。 這些優化方向是非常重要的。
目前,深度RL是不穩定的,是一項十分麻煩的研究。
當我開始在Google Brain工作的時候,我做的第一件事就是從標準化優勢函數論文中實現這個算法。 我想大概只需要2-3個星期。 我熟悉Theano,有一些深度RL經驗,而且NAF論文的第一作者正在Google Brain實習,所以我有問題可以直接請教他。
然而由於一些軟件錯誤,復現結果花了6個星期。 問題在於,為什麼花了這麼久才找到這些錯誤?
要回答這個問題,我們首先可以看看OpenAI GYM的最簡單的連續控制的任務:擺任務。 在這個任務中,有一個擺,固定在一個點上,重力作用在鐘擺上。 輸入狀態是三維的。 動作空間是一維的,即施加扭矩的量。 我們的目標是完美地平衡擺錘,讓其垂直向上。
這是一個小問題,好的獎勵函數讓它變得更容易。 獎勵是用鐘擺的角度來定義的。 將鐘擺向垂直方向擺動的動作不僅給予獎勵,還增加獎勵。 獎勵空間基本上是凹的。
下面是一個基本有效的策略的視頻。 雖然該策略沒有直接平衡到垂直位置,但它輸出了抵消重力所需的精確扭矩。
這是表現性能曲線,在我改正所有的錯誤之後。 每一條曲線都是10次獨立運行中的1次獎勵曲線。 相同的超參數,唯一不同的是隨機種子。
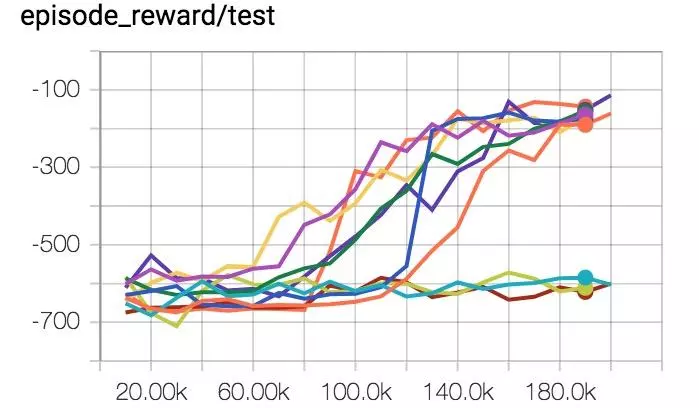
10次實驗中有7次運行成功,3次失敗,30%的失敗率。 下面是其他已發表工作中的曲線圖, Variational Information Maximizing Exploration,Houthooft et al, NIPS 2016。 環境是HalfCheetah。 我們將獎勵函數修改的更稀疏了一些,但這些細節並不太重要。 Y軸是每一段的獎勵,X軸是時間間隔,使用的算法是TRPO。
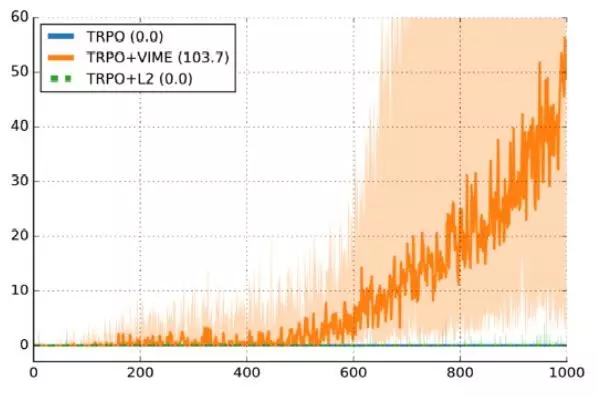
較深的曲線是10個隨機種子表現性能的中值,陰影區域是第25到第75個百分點。 這個曲線是支持論文算法的一個很好的論據。 但另一方面,第25百分點離0獎勵十分接近。 這意味著大約25%的實驗是失敗的,只是因為隨機種子。
監督學習也會有變化,但變化不會這麼大。 如果有監督學習的代碼運行結果有30%低於隨機結果,我會很自信肯定是數據加載或訓練過程哪裡出錯了。 如果我的強化學習代碼比不過隨機結果,我不知道是有地方出錯了,還是超參數不對,或者我只是運氣不好。

這張照片來自《Why is Machine Learning “Hard”?》。 核心論點是機器學習給失敗情況空間增加了更多維度,從而成倍地增加了導致失敗的原因。 深度RL又在此基礎上增加了一個新維度:隨機性。 你唯一能解決隨機問題的方法是通過在這個問題上投入足夠的實驗來抵消噪音。
當你的訓練算法樣本效率低下且不穩定時,它會嚴重降低你的研究速度。 也許只需要100萬步。 但是當你給這個數字乘上5個隨機種子,再乘上超參數調整,你需要不計其數的計算才能驗證所提假設的有效性。
或許這些能讓你覺得好受些:我研究手頭的工作已經好一段時間了,我花了6個星期的時間,讓一個從頭開始的策略梯度在一系列RL問題上獲得了50%的成功率。 我有一個GPU集群供我使用,還有一些每天一起吃午飯的朋友可以一起交流,他們在該領域已經工作了幾年了。
另外,我們從監督學習中學到的CNN設計似乎不適用於強化學習,因為強化學習的瓶頸在於信用分配或監管比特率,而不是表示能力不足。 ResNet、batchnorm,或者是很深的神經網絡在這裡都無法發揮作用。
[監督學習]是主動想要發揮作用的。 即使你搞砸了,你也會得到一些非隨機的反饋。 RL是必須被迫發揮作用的。 如果你搞砸了什麼,或者調整得不夠好,你極有可能得到比隨機情況更糟糕的策略。 即使一切都很好,也有30%的可能得到一個很差的策略,沒什麼理由。
長話短說,你的失敗更多是由於深度RL太難了,而不是因為“設計神經網絡”的困難。
——Andrej Karpathy在Hacker News上發表的博客
隨機種子的不穩定性就像是煤礦中的金絲雀。 如果純粹的隨機性足以導致每次實驗結果之間如此大的差異,那麼可以想像代碼中實際的差異該有多大。
不過我們不需要去想這個問題,因為 Deep Reinforcement Learning That Matters, Henderson et al, AAAI 2018)這篇論文已經給出了結論:
-
給獎勵函數乘以一個常數可以導致表現性能出現巨大的偏差。
-
5個隨機種子可能不足以證明結果的顯著性,因為通過仔細的選擇,你可以得到不重疊的置信區間。
-
相同算法的不同實現對同一任務有不同的表現,即使是使用相同的超參數。
我的理論是,RL對初始化和訓練過程的動態非常敏感,因為數據都是在線收集的,而唯一的監督是一個標量獎勵。 一個在好的訓練樣例上得到的策略會比一個沒有好的訓練樣例的策略能更快地引導自己。 一個不能及時發現好的訓練樣例的策略會崩潰,什麼也學不到,因為它相信它嘗試的任何方向都會失敗。
那麼RL已經成功做到的事呢?
深度強化學習確實做了一些非常酷的事情。 DQN雖然是舊新聞,但當時絕對轟動。 單個模型能夠直接從原始像素中學習,而不需要對每個遊戲單獨進行調優。 而且AlphaGo和AlphaZero也是非常令人印象深刻的成就。
然而,在這些成功之外,很難找到深度RL在真實世界創造實際價值的案例。
我試圖思考深度RL在現實世界的用途,卻發現非常困難。 我想在推薦系統中找到些東西,但那些算法仍然以協同過濾和上下文賭博機為主。
到最後,我能找到的最好的是兩個谷歌項目: 降低數據中心能耗,以及最近發布的 AutoML Vision。
我知道奧迪正在做一些深度RL相關的項目,他們在NIPS上展示了自動駕駛的RC汽車,聲稱使用了深度RL。 我知道有一些很棒的工作,優化大型Tensorflow圖的設備放置;Salesforce的文本摘要模型。 融資公司肯定在用RL做實驗,但目前還沒有確切的證據。 Facebook已經在聊天機器人中用深度RL完成了一些很棒的工作。 每個互聯網公司應該都想過在廣告服務模型中加入RL,但是出於商業保密,我們並不知情。
在我看來,或許深度RL是一個不夠強大,不能廣泛應用的研究課題,也可能它是可用的,只是應用了它的人沒有公開。 我認為前者更有可能。
如果你問我圖像分類的問題,我會告訴你預訓練的 ImageNet模型。 對於圖像分類問題,我們處在一個連電視劇《矽谷》的製作團隊都能開發出識別熱狗的軟件的世界。 但在深度RL領域幾乎是不可能發生同樣的事情。
鑑於目前的限制,什麼時候深度RL能有作用?
首先,真的很難說。 想用RL解決所有事情,等同於試圖用同樣的方法來解決非常不同的環境下的問題。 它不能一直起作用才應該是正常的。
話雖如此,我們可以從目前強化學習成功的項目列表中得出結論。 這些項目中,深度RL或是學習了一些質量極優的行為,或是學習到了比以前更好的行為。
這是我目前的列表:
-
在前面的章節中提到的項目:DQN,AlphaGo,AlphaZero,跑酷機器人,減少能耗中心使用,以及利用神經架構搜索技術的AutoML。
-
OpenAI的Dota2 1v1影魔機器人,在一個簡單的對戰設置中打敗了頂級職業選手。
-
任天堂明星大亂鬥機器人,在1v1的Falcon ditto遊戲中打敗了職業選手。
-
機器學習最近在玩法不限注德州撲克中擊敗了職業玩家。 Libratus 和 DeepStack都做到了這一點。 有些人認為這是用深度RL完成的。 但這兩篇論文都不是,他們用的是虛擬遺憾最小化和迭代求解子博弈的方法。
從這個列表中,我們可以看出使學習更容易的一般屬性。 下面的屬性都不是學習必需的,但是滿足的特性越多絕對是越好的:
-
很容易產生近乎無限量的經驗。 為什麼這一點有用應該是很清楚的。 擁有的數據越多,學習問題就越容易。 這適用於Atari遊戲,圍棋、象棋、將棋,以及跑酷機器人的模擬環境。 它似乎也適用於能耗中心的項目,因為在以前的工作中,結果表明神經網絡預測能源效率的準確度很高。 這正是你訓練RL系統想要的模擬模型。
-
問題可以簡化成更簡單的形式。 我在深度RL看到的常見錯誤是想法太大。 強化學習可以做任何事情! 這並不意味著你必須同時完成每件事。
OpenAI的Dota2機器人只玩了初級遊戲,只在1V1對線設置中玩了影魔對影魔,使用硬編碼的項目結構,並且調用了Dota2 API 來避免解決感知問題。 SSBM機器人達到了超人的表現,但它只是在1v1比賽中,與Captain Falcon在Battlefield上,而且不限時。
這不是在諷刺這些機器人。 如果你連一個簡單的問題都不知道是否能解決,為什麼還要研究一個困難的問題呢? 所有研究的趨勢都是先演示最小的概念證明,然後再推廣它。 OpenAI在擴展他們的Dota2的研究工作,也在將SSBM機器人擴展到其他角色。
-
有一個方法可以將自我博弈引入學習過程。 這是AlphaGo,AlphaZero,Dota2影魔機器人,以及SSBM Falcon機器人的一個組成部分。 自我博弈,指的是比賽有競爭性,兩個玩家都可以由同一個agent控制。 到目前為止,這種設置似乎是最穩定且表現良好的。
-
有一種簡單的方式來定義一個可學習的、不可競爭的獎勵。 兩個玩家的遊戲設置這樣的獎勵:贏的+ 1,輸的-1。 最初的神經架構搜索論文使用了這個方法驗證訓練模型的精度。 任何時候你引入計劃獎勵,你都會引入學習出優化錯誤目標的非最佳策略的可能。
如果你想進一步了解如何設計一個好的獎勵函數,可以搜索“合適的評分規則”。 Terrence Tao的博客中介紹了一個可行的例子。
而對於可學習性,除了多次嘗試看看是否有效,我沒有別的建議。
如果需要定義獎勵,至少應該形式豐富。 在Dota2中,最後的補刀,以及治愈會有獎勵。 這些獎勵信號頻率很高。 對於SSBM機器人,造成傷害時會給予獎勵,每次成功的攻擊都會給出信號。 行動與結果之間的延遲越短,反饋環形成越快,強化學習就越容易找到高回報的途徑。
案例研究:神經架構搜索(Neural Architecture Search,NAS)
我們可以結合一些原理來分析神經架構搜索的成功。 從最初ICLR 2017版,在12800個樣例後,深度RL能夠設計先進的神經網絡結構。 誠然,每個樣例都需要訓練一個收斂的神經網絡,但這仍然是非常有效的。
如上所述,獎勵是驗證準確性。 這是一個非常豐富的獎勵信號——即使一個神經網絡設計的結果只將精度從70%增加到到71%,RL仍然會考慮這一點。 此外,有證據表明,深度學習的超參數接近線性無關。 NAS不完全是調整超參數,但我認為神經網絡設計決策與調整超參數類似。 這對學習來說是個好消息,因為決策和性能之間的相關性很強。 最後,獎勵不僅很豐富,它也體現了我們訓練模型時關心的是什麼。
這些點的結合讓我明白了為什麼它“只”需要大約12800個訓練好的網絡來學習更好的網絡,而在其他環境中需要數以百萬計的樣例。 這個問題的許多方面都對RL有利。
簡而言之:深度RL目前還不能即插即用。
未來發展
有一句老話——每個研究者都在學習如何討厭他們的研究領域。 儘管如此,研究人員還是會繼續努力,因為他們太喜歡這些問題了。
這也是我對深度強化學習的大致感受。 儘管我有保留意見,但我認為人們應該用RL去嘗試不同的問題,包括那些可能行不通的問題。 否則我們還有其他辦法讓RL變得更好嗎?
我覺得深度RL的有效性只是時間問題。 當深度RL足夠魯棒,能更廣泛的使用時,它能做到非常有趣的事情。 問題在於它該如何走到那一步。
下面我介紹了一些我認為的未來發展趨勢。 未來依然基於進一步的研究,因此我提供了這些研究領域相關論文的引用。
局部最優已經足夠好: 認為人類在任何事情上都已經做到最好了是很傲慢的想法。 我認為與其他任何物種相比,我們僅僅剛好到步入了文明階段。 同樣,只要RL解決方案的局部最優解優於人類基準,它不必達到全局最優解。
硬件解決一切: 我知道有些人認為最能影響人工智能的事情就是提升硬件。 就我個人而言, 我對於硬件能解決一切問題的觀點持懷疑態度,但這一點肯定是很重要的。 運行的速度越快,對樣本效率的擔心就越少,越容易對探索問題暴力解決。
添加更多的學習信號: 稀疏獎勵很難學習,因為得到的信息太少了。 也許我們可以變換積極獎勵,定義輔助任務,或用自我監督學習引導構建良好的真實世界模型。
基於模型的學習提升樣本效率: 我是這樣描述基於模型的RL的:“每個人都想做,但很多人不知道。”原則上,一個好的模型能修正許多問題。 就像AlphaGo一樣,一個好模型讓它更容易學習出解決方案。 好的模型能遷移到新的任務,基於模型的方法也能使用較少的樣本。
問題在於學習一個好的模型很難。 我認為低維狀態模型有時有效,圖像模型通常太難。 但是,如果這一點變得容易了,就能產生一些有趣的事情。
Dyna 和Dyna-2是這個領域的經典論文。 對於將基於模型學習和深度網絡結合起來的研究領域,我推薦幾篇Berkeley機器人實驗室最近發表的幾篇論文: Neural Network Dynamics for Model-Based Deep RL with Model-Free Fine-Tuning (Nagabandi et al, 2017),Self-Supervised Visual Planning with Temporal Skip Connections(Ebert et al,CoRL 2017)。 Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning (Chebotar et al, ICML 2017)。 Deep Spatial Autoencoders for Visuomotor Learning (Finn et al, ICRA 2016),以及Guided Policy Search (Levine et al, JMLR 2016)。
用強化學習進行調優: 第一篇AlphaGo論文就是採用監督學習,然後在其基礎上用RL進行微調。 這是一個很好的方法,因為它使用一個更快但不那麼強大的方法來加快初始學習。 該方法在其他環境下也有效,例如Sequence Tutor。 可以將其視作以一個合理的先驗條件作為RL過程的開始,而不是用一個隨機的條件,或者用其他方法來解決學習先驗條件的問題。
可學習的獎勵函數: ML的前景在於我們可以用數據來學習比人類的設計更好的東西。 如果獎勵函數的設計這麼難,為什麼不用ML來學習更好獎勵函數呢? 模仿學習和逆向增強學習都顯示了獎勵函數可以用人為演示和人為評分來隱式定義。
逆RL和模仿學習領域的優秀論文:Algorithms for Inverse Reinforcement Learning, Apprenticeship Learning via Inverse Reinforcement Learning (Abbeel and Ng, ICML 2004), 以及DAgger。
最近也有一些工作將這種想法推廣到深度學習:Guided Cost Learning, Time-Constrastive Networks, 和 Learning From Human Preferences。
對於不使用深度學習的長期研究,我推薦閱讀:Inverse Reward Design (Hadfield-Menell et al, NIPS 2017) 和 Learning Robot Objectives from Physical Human Interaction (Bajcsy et al, CoRL 2017)。
遷移學習拯救一切: 遷移學習的前景在於你可以利用從以前的任務中學到的知識來加速學習新知識。 我認為這絕對是未來的發展趨勢,任務學習足夠強大,可以解決幾個不同的任務。 如果根本就沒有學習,也無法進行遷移學習,而且給定任務A和B,很難預測A是否可以遷移到B。
該領域推薦閱讀的論文:Universal Value Function Approximators (Schaul et al, ICML 2015), Distral (Whye Teh et al, NIPS 2017), 和 Overcoming Catastrophic Forgetting (Kirkpatrick et al, PNAS 2017)。 之前的工作可以閱讀Horde (Sutton et al, AAMAS 2011)。
機器人在sim-real遷移中取得了很大的進步。 推薦閱讀論文:Domain Randomization, Sim-to-Real Robot Learning with Progressive Nets, 和GraspGAN。
好的先驗條件可以減少學習時間 : 這一點和之前的幾點之間有緊密聯繫。 有一種觀點認為,遷移學習是利用過去的經驗為其他任務學習建立一個良好的先驗。 RL算法的設計適用於任何馬爾可夫決策過程。 如果我們承認,我們的解決方案只在很小一部分環境中表現較好,我們應該能夠以一種有效的方式利用共享結構來解決這些環境中的問題。
Pieter Abbeel在演講中喜歡提到的一點是,深度RL只需要解決我們希望在現實世界中需要解決的任務。 應該有一種現實世界的先驗,能夠讓我們快速學習新任務,代價是非現實任務中較慢的學習成本,但這是非常值得的。
困難在於,這樣的真實世界先驗是很難設計出來的,但依然是可能的。 我對元學習最近的工作很有興趣,因為它提供了數據驅動的方法來生成合理的先驗條件。 例如,如果我想用RL設計倉庫導航,我會用元學習來學習一個好的導航先驗,然後根據特定倉庫機器人的要求對先驗進行調優。
最近這方面的研究工作可以在BAIR的博客中找到。
更難的環境反而可能更簡單: 我們從DeepMind跑酷論文中受啟發最大的一點就是,如果通過添加幾個任務變體讓任務變得很難,你其實讓學習變得更加容易了,因為策略不能過度擬合到任何一個設置而 在其他設置下不損失性能。 我們在域隨機化論文中已經看到了類似的事情,甚至在ImageNet中:在ImageNet上訓練的模型比在CIFAR-100上訓練的模型推廣性更強。 正如我上面所說的,也許我們離更通用的RL只有一個“ImageNet控制”的距離。
從環境角度來說,有許多選擇。 OpenAI Gym目前用戶最多,但是Arcade Learning Environment、Roboschool、DeepMind Lab、DeepMind Control Suite以及ELF都是很好的環境.
最後,雖然從研究的角度來看深度RL並不令人滿意,但是它的經驗問題對於實際用途可能並沒有影響。 假設一個融資公司使用深度RL。 他們用美國股票市場過去的數據訓練了一個交易agent,使用3個隨機種子。 在現場的A / B測試,一個收入減少了2%,一個相同,另一個收入多出2%。 在這個假設中,復現性不影響結果,你只要部署收入多出2%的模型的就好。 交易agent可能只在美國的表現性能好,沒關係,如果在全球市場推廣效果不佳,不要部署在那裡就好。 取得非凡的成就和別人能複制的成功之間還有較大的差距,可能前一點更值得重點關注。
我們現在走到哪一步了
從許多角度來說,我對深度RL當前的狀態都感到很煩惱。 然而,人們對它有著強烈的研究興趣,可謂是前所未見。 Andrew Ng在他的 Nuts and Bolts of Applying Deep Learning(螺母和螺栓的應用深度學習)的談話中很好的總結了我的想法,短期很悲觀,但長期的樂觀也平衡了這一點。 深度RL現在有點混亂,但我仍然相信它是未來。
也就是說,下一次有人再問我強化學習是否可以解決他們的問題時,我仍然會告訴他們:不,不行。 但我也會告訴他們等幾年後再問我,到那時,也許它就可以了。
本文由 AI前線 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/239530.html