試想一下,一個靜謐的午夜,你和家人正在熟睡,家中突然響起毛骨悚然的笑聲,時遠時近,這困擾了大人,驚嚇了孩子。 這些怪笑是Alexa發出來的。 作為亞馬遜的主推產品,Alexa的這次故障讓許多用戶陷入恐慌之中。
目前,亞馬遜方面並沒有對此次故障的原因進行詳盡解釋,並且它強調這是在“極少數情況”下才會發生的。 儘管網上反映的問題代表不了使用Echo的數千萬用戶,但可以看出亞馬遜對此事的態度其實不以為意。
類似的情況,在聊天機器人身上已經不是第一次發生。 兩年前,微軟在Twitter上的聊天機器人Tay變成了“種族主義者”,不到一年,它的後續產品Zo又再次出現問題。 Zo認為古蘭經裡描述的內容“非常暴力”,並且它認為抓住本·拉登是“不止一個政府多年情報收集”的結果。

之前,Facebook也關閉了虛擬助理M,團隊相關成員被派遣到其他部門任職。 聊天機器人的發展,看起來道阻且長。
聊天機器人變成“人工智障”?
“和機器人有著最自然的對話,它將一切任務都執行得完美無瑕,我們可能都希望能生活在這樣的世界裡。這一路走來確實不容易,而且說實話我們已經發展得很快了。 ”Politibot的Suárez認為,“但不幸的是,我們還沒有達到那個理想的生活狀態,還要好幾年,機器人才能好到普羅大眾都能接受。”
然而,現實卻遠不及Suárez的預期,聊天機器人依然存在著眾多問題。 2016年,Facebook Messenger開放其程序接口後,收到的用戶反饋很少。 眾多機構確實可以在短時間內擁有自己的智能聊天機器人,但當此類機器人無人類干預時,應答失敗率高達 70%,用戶體驗更是相當糟糕。
從“圖靈測試”到Eliza的精神治療,聊天機器人發展至今已經走過了近70年,在漫長的發展歷程中,聊天機器人並未得到真正的普及,現今依然存在著諸多弊病。
是誰讓聊天機器人變成了這樣? 智能相對論認為,是人類,更是機器本身。 部分核心技術及適配性問題,依然是聊天機器人的阿喀琉斯之踵。
1. 複雜語言識別困難
現在的聊天機器人,對話界面主要依賴於語音識別,從而根據用戶命令做出便捷迅速的反應,比如“下午三點去參加會議”“今天的天氣怎樣”等。
語言作為一種主觀性較強的表達方式,人們說話的規則可以說是千變萬化的。 這和電腦程序不同,人們表達不會完全受制於規則,能夠自由的遣詞造句,並以此來傳遞信息。 除了地方方言外,每個人也會有自己獨特的表達方式,例如心照不宣的“暗語”,或者某些特定的“梗”。 這就需要聊天機器人“去陌生化”,結構化語言的系統將難以滿足大量用戶的需求,這對聊天機器人的系統提出了更高的要求。
以Richard S.Wallac設計的Alice聊天機器人為例,其在中文處理上就存在一些問題。 這是因為漢語不像英語等語言,用空格或其他標記分詞,這就加大了Alice對中文支持的難度。 此外,其對於漢語分詞采用的一般匹配法、詞頻統計法、同義句的處理等方面也存在著許多技術難題。
2. 個性化適配之痛
個性化適配的問題體現在兩個方面,一方面人機信任是聊天機器人個性化發展的一個攻堅點。 調查顯示,許多公司領導對於聊天機器人處理待辦事項是並不看好的,聊天機器人程序化的語言會讓許多人覺得“乏味”“沒有人氣”,這也是公司助理一職並未被取代的原因 。
另一方面,聊天機器人很容易對人的需求產生誤讀。 比如對Siri發出“區塊鏈”的指示,Siri提供的是關於區塊鏈的百度百科,這與用戶想要了解區塊鏈的最新發展動態的初衷大相徑庭。
目前聊天機器人語音識別主要基於語音識別的基本架構、聲學模型、語言模型並進行解碼,而真正通過用戶畫像來實現個性化適配的聊天機器人少之又少。 其實,不同用戶的性格、特點、知識層次都不相同。 如果有預設的用戶畫像,那出現適配失誤的可能性也會大大減小。
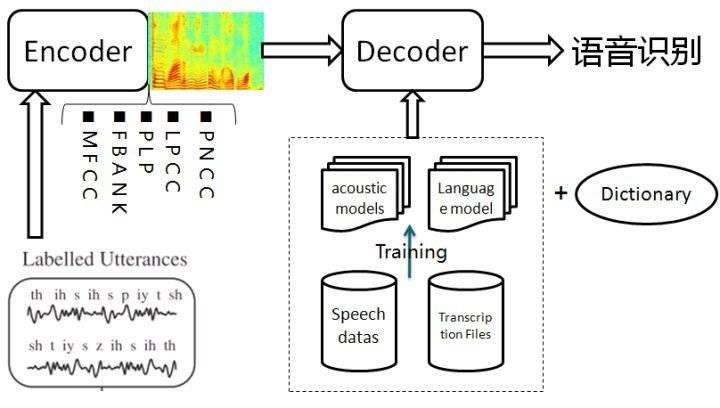
目前來看,機器學習能夠做到的事情,大體主要還是字符識別、語音識別、人臉識別這一類,這些稱之為“識別系統”。 這些系統的問題在於難以變通,簡單的語音識別難以真正為用戶提供較為複雜的輔助工作,線性的識別方式也難以適用於更開放的應用場景。
3. 隱私安全終成隱憂
最近,Facebook被曝史上最大數據洩露案,特朗普被指利用AI競選成功,這也讓更多的聊天機器人用戶對自身的隱私感到擔憂。 “Alexa發笑”事件中,亞馬遜對於事件原因閃爍其詞,似乎用戶數據已經進入了“圍牆花園”的模式。 語音分析和人工智能軟件存在於一個黑匣子中,而這些軟件只有矽谷的開發人員才能真正理解。 很難想像,如果將一切的智能家居與聊天機器人連接起來時,涉及到的數據、信息都存儲在一個用戶無法擁有也無法控制的計算機上,這是一件多麼可怕的事。
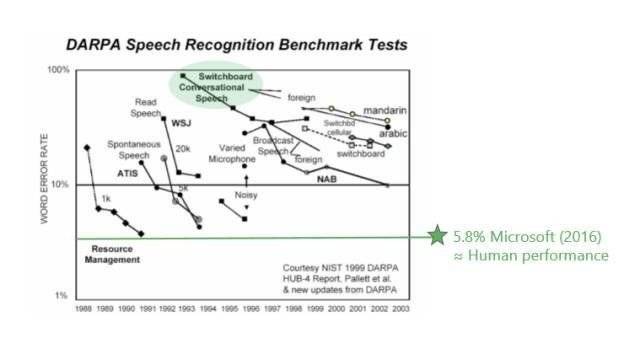
作為語音識別領域的領軍人物,微軟於2016年也僅僅將錯誤率控制在5.8%左右。 可是隨著人工智能進一步拓展到金融、醫療等領域,1%的錯誤率導致的可能就是財產的損失和生命的安全。
此外,配套設施的不完善難以讓聊天機器人發展成了一個嚴密的體系,這使得初次試水的用戶對此頗有微詞。 聊天機器人何時能夠完善到能夠大範圍普及,這也是開發聊天機器人的公司需要認真思考的問題。
聊天機器人或許需要“洗心革面”
曾經火遍全球的索菲婭機器人,前段時間也攤上大事了。 Yan LeCun指出索菲婭與人類堪稱完美的聊天對話其實是一場徹頭徹尾的騙局,以目前人工智能的技術來看,此種對話是不可能實現的。
而在2018年年初,Facebook關閉了虛擬助理M,成了壓死駱駝的最後一根稻草。 許多互聯網公司對聊天機器人已經不感興趣了,聊天機器人的發展也走進了死胡同。 智能相對論認為,可以從三個方面“洗心革面”。
1. 塑造聊天機器人的“獨立三觀”
能夠獨立表達喜歡、不喜歡和偏好的性格,在聊天的過程中展示出誠實和值得信任等可貴品質,是塑造聊天機器人“獨立三觀”的重要體現。 正如聊天機器人被引入日常生活,我們還能訓練機器人去識別我們的語言,挖掘我們的喜好,甚至還能分析我們的口音,推測我們的情緒。
有一個典型的例子:通過自然語言和情感分析,Quartz公司嘗試著讓Quartzy來指導特定用戶做麵包。 Quartzy會以一種友好且有趣的方式和用戶聊聊“怎麼做一個免揉麵包”,一旦用戶完成了第一個步驟,Quartzy會在大概12小時後,用Facebook Messenger給用戶“叮”一個通知 ,提醒用戶完成後續的步驟。 這是聊天機器人獨立三觀的一個體現,當然希望以後這樣的嘗試會更加普及。
2. 從“鸚鵡學舌”到“烏鴉喝水”
“鸚鵡學舌”是人類語言的模仿行為,由數據驅動的聊天機器人也可以探索出類似的方式。 而“烏鴉喝水”則是一個完全自主行為,其含括了感知、認知、推理、學習和執行,這是聊天機器人朝想像力、創造力更高層次的進階。 目前,要真正實現聊天機器人的“烏鴉喝水”,主要從這兩個方面來努力:
一方面,讓人工智能在自動學習中“更聰明”。 伊恩·古德費洛做過一個實驗,用兩個神經網絡進行數字版的“貓鼠遊戲”——一個負責“造假”,一個負責“驗真”,從而在對抗中不斷提高。 首先,依據“見過”的圖片生成新圖片,讓聊天機器人總結規律、發揮想像力和創造力;其次,判別某張圖片是否是真實事物,這就要靠聊天機器人通過訓練積累“經驗”。
另一方面,建立更加豐富的知識圖譜。 知識圖譜的建立需要從靜態和動態兩個方面出發,真正將聊天對話場景從垂直領域拓展到開放領域。 同時,構建知識圖譜的重點在於語義理解、知識表示、QA、智能對話和用戶建模。
3. 找到更多遠的盈利模式
聊天機器人作為一個虛擬助理,其存在的目的是為了給人類提供便利。 聊天機器人主要分為兩種:單純聊天的機器人以及垂直領域的定制機器人,如小i機器人就衍生出了全渠道、跨領域智能客服機器人、智能呼叫中心解決方案、智能營銷解決方案、智能語音交互 解決方案等多個發展方向。 當下,聊天機器人主要利用於內置商業場景中,如用機器客服代替人工客服。
事實上,目前業內對聊天機器人盈利模式的探索還遠遠不夠。 作為人工智能產品的重要代表,其在聊天機器人+原生內容、利用聊天機器人做聯盟網絡營銷、用聊天機器人做用戶調研等方面是大有可為的。 這顯然不僅僅是聊天機器人或者個別互聯網公司的任務,也是整個行業的義務。
本文由 智能相對論 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/236656.html