《聖經》中曾記載,人類曾經聯合起來興建能通往天堂的高塔,為了阻止人類的計劃,上帝讓人類說不同的語言,使人類相互之間不能溝通,計劃因此失敗,人類自此各 散東西。
長久以來,人們一直在尋找不同語言之間的溝通方法。 學習和掌握一門外語,也是中國學生必須具備的能力。 但精通外語始終不是一個簡單的事。 所以無論是現實中,還是科幻電影中,人們一直希望能有一個機器,讓人不學外語也能暢快溝通。
隨著技術進步,這個夢想正在一步步成為現實。 來自俄羅斯的Ilya Pestov,最近寫就了一篇《機器翻譯簡史》,較為完整地回顧了人類過去幾十年來在機器翻譯方面的探索和努力。
最初
故事開始於1933年。 當時,前蘇聯科學家Peter Troyanskii向蘇聯科學院介紹了一種能將一種語言翻譯成另一種語言的機器。
這個發明超級簡單,由各種語言的卡片、打字機和老式膠片相機組成,用起來是這樣的:操作員對著一段文本中的第一個詞,找到相應的卡片,拍張照,然後用打字機 打出它的形態特徵,比如說這是個複數屬格名詞。 然後,將打字機帶子和相機膠片組合在一起,每個詞和它的屬性構成一幀。
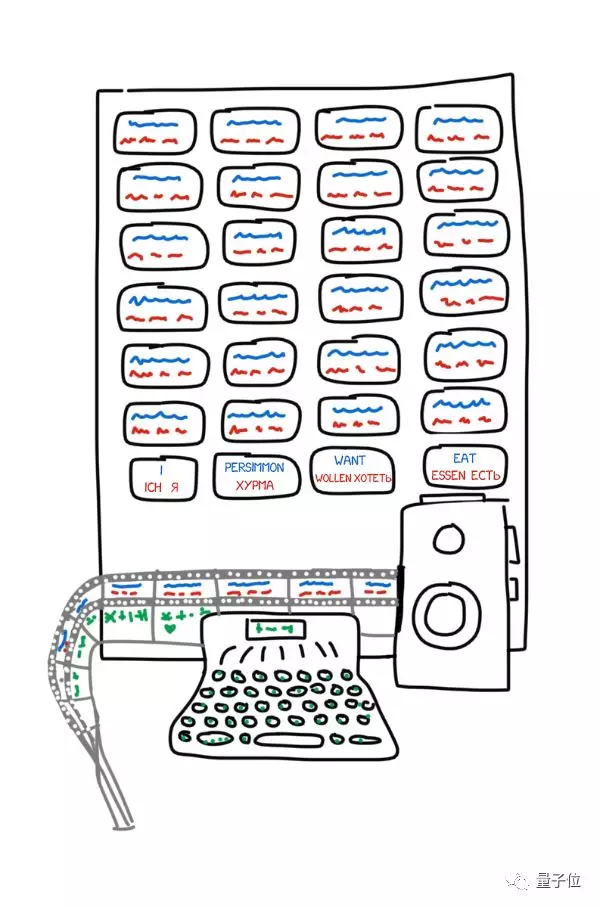

不過,前蘇聯政府認為這台機器沒什麼用。 Troyanskii又花了20年的時間來完成這件發明,後來死於心絞痛。 如果不是1956年又有兩名蘇聯科學家發現了他的專利,世界上不會有人知道,曾經有人構想過這樣一台機器。
那是冷戰初期,1954年1月7日,在紐約的IBM總部開始進行Georgetown–IBM實驗,IBM 701計算機完成了史上首例機器翻譯,自動將60個俄語句子翻譯成了英語。
IBM隨後在新聞稿中如此描述他們的成就:一個根本不會俄語的姑娘,在IBM卡片上打出這些俄語信息,我們的“大腦”指揮著一台自動打印機,以每秒兩行半的速度飛快 打出它們的英語譯文。

然而新聞稿隱藏了一些細節,誰也沒有提到,這些翻譯的例句經過了精心的挑选和測試,排除了一些歧義。 如果用到日常場景中,這個系統不會比一本單詞書強多少。
就算這樣,機器翻譯的軍備競賽還是開始了,加拿大、德國、法國、日本都投入其中。
軍備競賽
四十年來,科學家們一直在改進機器翻譯。
1966年,美國科學院的自動語言處理諮詢委員會發布了一份著名的報告,稱機器翻譯昂貴、不准確、沒前途。 他們建議專注於詞典開發,結果是美國科學家幾乎有10年沒有參與競爭。
即便如此,科學家們的努力還是為現代自然語言處理技術打下了基礎,現在的搜索引擎、垃圾郵件過濾、智能助理都得歸功於當年這些互相監視的國家。
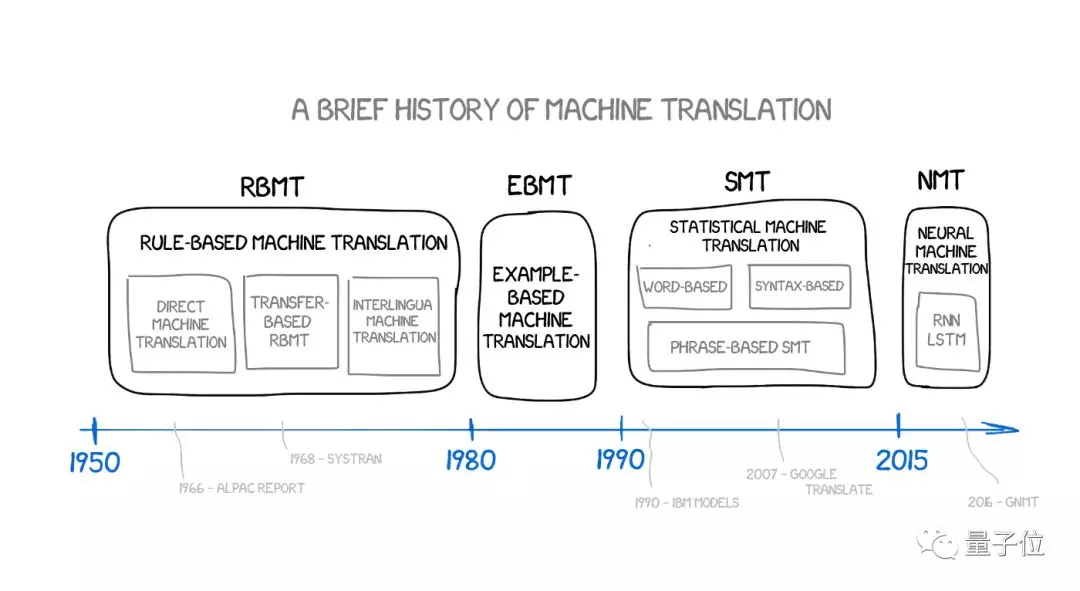
第一波基於規則的機器翻譯想法出現在70年代,科學家們研究著翻譯員的工作,想讓笨重的計算機來重現這些行為。
RBMT的系統包括雙語詞典、煤種語言的語言學規則。 如果有需要,還可以再給系統補充一些小功能,比如名稱列表、拼寫糾錯、音譯程序等。
RBMT系統中比較著名的包括PROMPT和Systran,去看看Aliexpress上那些英文商品名,就能感受到這個黃金時代的氣息。 不過這一類系統也並非完全一樣,還可以再細分為各種子類別。
直接機器翻譯
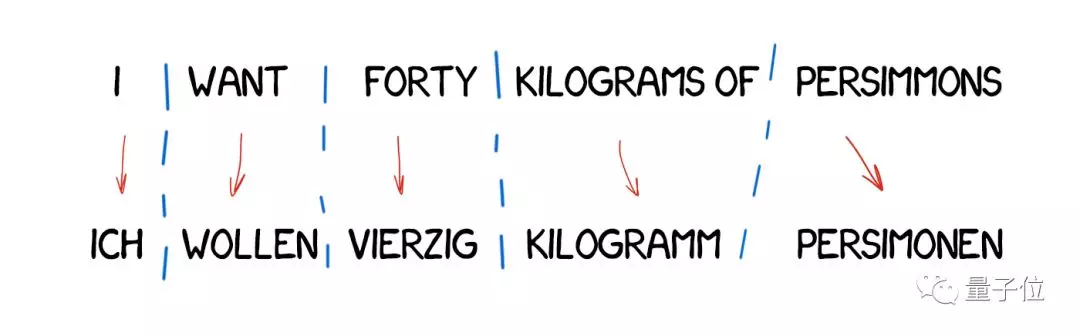
這類翻譯最為簡單,它將為本分成單詞,翻譯出來,稍微修正一下形態,然後協調句法,讓整句話聽起來多少像那麼回事,就可以了。
直接機器翻譯需要訓練有素的語言學家為每個詞編寫規則,輸出的語句可以說是一種譯文,但通常很詭異。 這種方法現在已經淘汰了。
基於轉換的機器翻譯
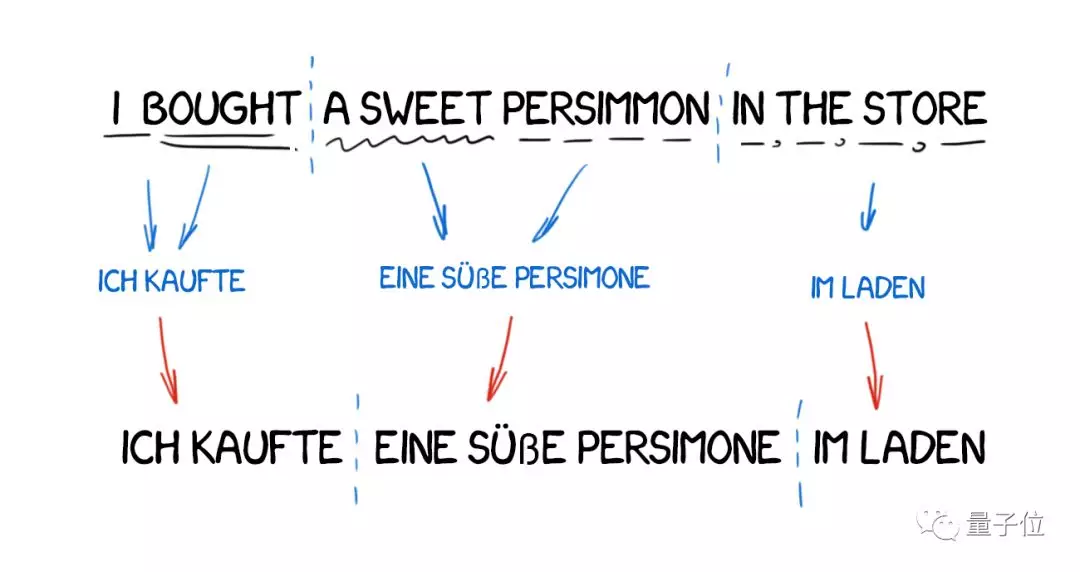
與直接機器翻譯相比,這種方法需要先確定句子的語法結構,然後對整個結構進行處理,而不是按詞來處理。
理論上來講,這種方法能得到很不錯的語序轉換結果。 可實際上,譯文還是逐字翻出來的,語言學家還是精疲力盡。
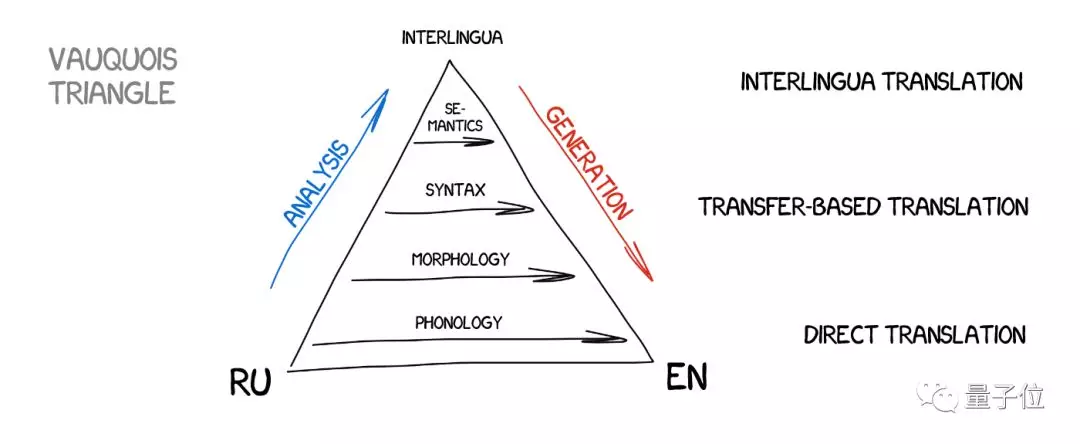
中介語機器翻譯
這種方法會將源文本轉換為一種中間表示,這種表示法是全世界各種語言通用的,相當於笛卡爾設想的“元語言”,遵循通用規則、能和各種語言互相轉換。
由於需要轉換,中介語經常會和基於轉換的方法混淆。 它們之間的區別在於,設置的語言學規則是針對每種語言和中介語的,而不是針對兩種語言之間的對應。
用這種方法,建立三種語言和中介語之間的轉換規則,就可以完成這三種語言之間的互相翻譯,而如果用基於轉換的方法,就需要為這三種語言兩兩建立規則 。

看起來很美對吧? 總有現實來打臉。 創造這種通用的中介語是非常難的,科學家們前赴後繼貢獻一生,也沒能成功。 不過他們為後世留下了形態、句法甚至語義層面的表示方法。
用中介語實現直接機器翻譯顯然也行不通,但別著急,這種思想還會回歸。
用現代的眼光來看,所有RBMT分支都笨得可怕,所以除了天氣預報等特定場景,已經見不到這類方法。 當然,RBMT也有優點,比如形態的準確性、結果的可複現性、針對特定領域進行調整的能力等等。
但是,要創造一個理想的RBMT系統,就算讓語言學家窮盡一切拼寫規則來增強它,也總會遇到例外。 英語有不規則動詞、德語有可分離前綴、俄語有不規則的後綴,在人們說話的時候又會有各自的語態、語境,別忘了有些詞根據上下文還會產生不同的意思。 要考慮所有細微規則,要耗費巨大的人力資源。
語言不是基於一套固定規則發展的,規則的形成受到不同群體交流、融合的影響。 於是,四十年的冷戰和軍備競賽也沒能帶來任何優秀的解決方案,RBMT死了。
基於例子的機器翻譯
日本也是個機器翻譯大國,原因很簡單,它們雖然沒參與到冷戰之中,但國內懂英語的人太少了,這在全球化浪潮中是一個大問題。 因此,日本人在機器翻譯的研究上有著強大的驅動力。
基於規則的英日翻譯非常複雜,這兩種語言有著完全不同的結構,每翻譯一句話都要重新排列所有單詞,再增加一些新詞。
1984年,京都大學的長尾真提出了一種新想法:直接用已經準備好的短語,不用重複翻譯。
比如說,我們之前翻譯過“我要去劇院”這句話,現在要翻譯一句類似的話:“我要去電影院”。 那麼,只要比較一下這兩句話,找出其中的區別,然後翻譯不一樣的那個詞“電影院”就好了。 已有的例子越多,翻譯結果就越好。
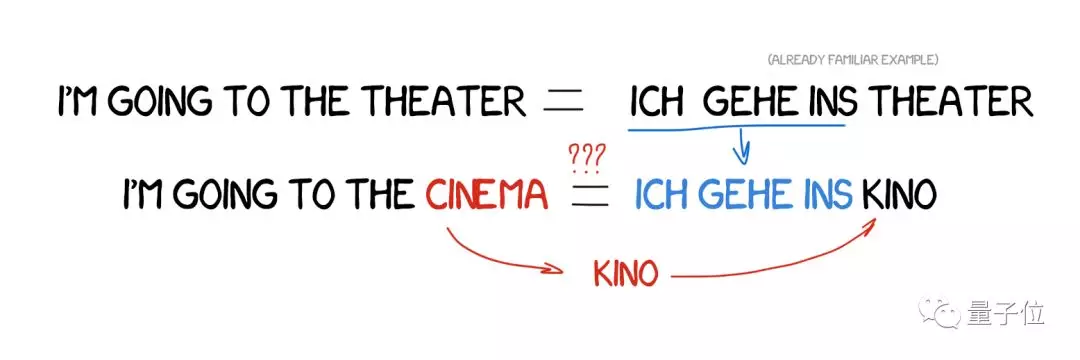
EMBT給全世界的科學家帶來了一道曙光:給機器提供已有的翻譯例句,不用花幾十年來定義規則和例外了。 這種方法出現時並沒有立刻風靡,但它走出了革命性的第一步,之後不到5年,就出現了統計機器翻譯。
統計機器翻譯
90年代早期,IBM研究中心首次展示了對規則和語言學一無所知的機器翻譯系統。 這個系統分析了兩種語言中類似的文本,嘗試理解其中的模式。

這個想法簡潔優雅。 將兩種語言中同義的句子切分成詞進行匹配,然後去計算“Das Haus”這個詞有多少次對應著“house”“building”“construction”等等。 大部分時候,它是和house相對應的,於是機器就用了這種譯法。
在這個過程中,沒有規則,沒有詞典,所有的結論都是機器根據統計數據得出的。 它背後的邏輯很簡單,就是“如果人們都這麼翻譯,我也這麼翻”。
統計機器翻譯就此誕生。

它比之前所有方法都更加準確高效,也不需要語言學家。 我們給機器更多的文本,它就給我們更好的翻譯。
機器怎麼知道句子中“Das Haus”對應的是“house”呢? 一開始是不知道的。 最初,機器會認為“Das Haus”和譯文中任何一個詞都相關,接下來,它遇到更多包含“Das Haus”的句子,逐漸增強這個詞和“house”的相關性。
這就是現在大學裡機器學習課程的一個典型任務:“字對齊算法”。 要收集每個單詞的相關統計數據,機器都需要上百萬對例句。 這些例子從哪來呢? 答案是歐盟和聯合國安理會的會議紀要。
基於詞的SMT
最初的統計翻譯系統會先將句子分解成單詞,這樣最直接,又合乎邏輯。
IBM的第一個統計機器翻譯模型叫做模型1。 優雅吧? 等你看到第二個模型叫什麼就不覺得了。
模型1:詞袋

模型1用了一種經典方法,將句子切分成詞然後進行統計,不考慮語序。 這個模型中唯一用到技巧的地方,就是將一個詞翻譯成多個詞,比如將“Der Staubsauger”翻譯成“Vacuum Cleaner”,但反過來不一定是這個結果。
模型2:考慮句中詞序
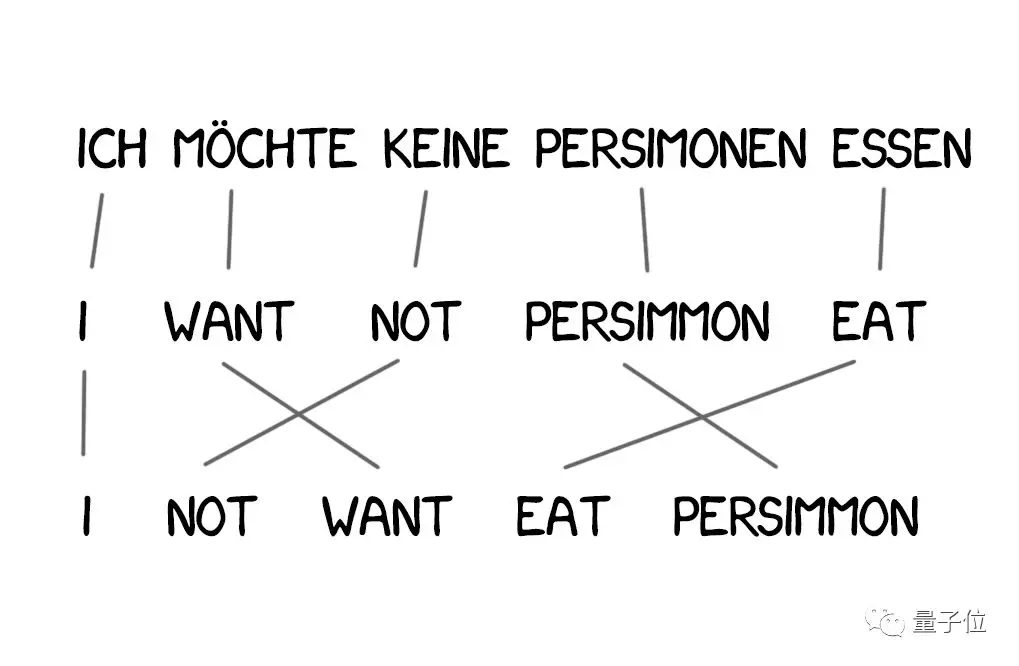
不考慮語序是模型1的大缺陷,在某些情況下還很關鍵。
於是,就有了解決這個問題的模型2。 它記住了單詞在輸出句子中經常所處的位置,並在翻譯過程中重新排列順序,讓整句話看起來更自然。
譯文好多了,但還是不太對。
模型3:引入新詞
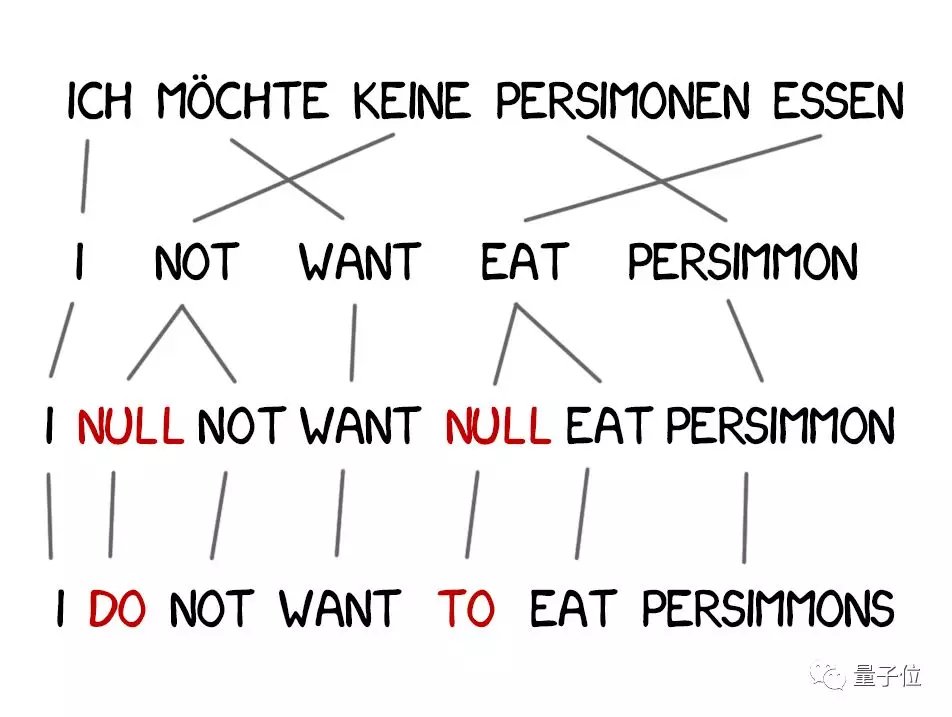
在翻譯中,經常要引入原句中沒有的新詞,比如說德語裡的冠詞,英語裡表示否定時要加的“do”。
我們的例句“Ich will keine Persimonen.”,在英語中應該翻譯成“I do not want Persimmons.”
於是,模型3中又增加了兩個步驟:
1. 如果機器考慮引入新詞,就要在原文中插入NULL標記。
2. 為每個標記詞選擇正確的新詞或語法單位。
模型4:字對齊
模型2考慮了詞的對應,但沒有考慮重新排序。 比如說形容詞和名詞的位置經常變換,無論模型記憶詞的位置記得多好,都沒法輸出更好的結果。
因此,模型4引入了“相對順序”,如果兩個詞總是互換位置,模型會學到。
模型5:錯誤修正
這個模型中沒什麼新東西,它獲得了更多的學習參數,解決了單詞位置衝突的問題。
這些基於詞的系統雖然具有革命性,但依然無法處理詞的格、性,也搞不定同音詞。 在這類系統中,每個詞會有唯一的翻譯方式。
後來,基於短語的方法取代了它們。
基於短語的SMT
這種方法和基於詞的SMT有著同樣的原則:統計、重新排序、在詞彙上用一些技巧。
不過,它不僅要將文本分成詞,還要分成短語,確切地說是n個單詞的連續序列,稱為n-grams。
機器就這樣學會了翻譯單詞的穩定組合,明顯提高了準確性。
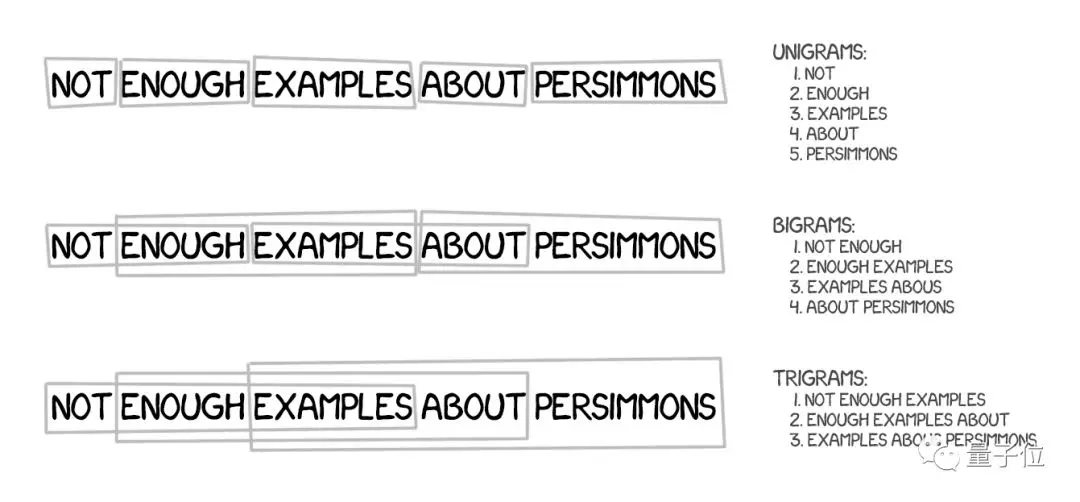
這種方法有一個訣竅,所謂“短語”並不一定符合句法結構,如果有語言學知識的人干涉了句子結構,翻譯的質量會大大下降。
除了準確性的提高,基於短語的SMT還為雙語語料帶來了更多的選擇。 對於基於詞的方法來說,來源語料的精確匹配非常重要,要排除一切意譯和自由發揮。 而基於短語的方法可以用這樣的語料來學習。
為了改進翻譯算法,科學家們甚至開始不同語言的新聞網站。

2006年,這種方法開始普及了。 Google翻譯、Yandex、微軟必應等等在線翻譯工具都用上了基於短語的SMT,一直用到了2016年。
在這個時期,你所聽到的“統計機器翻譯”通常指的就是基於短語的SMT,直到2016年前,它都被視為最先進的機器翻譯方法。
基於句法的SMT
在神經網絡出現之前的許多年裡,基於句法的翻譯被認為是“翻譯的未來”,但這個想法並沒有起作用。
基於句法翻譯的支持者認為,這個方法有可能與基於規則的方法合併。 這個方法是對句子進行精確的句法分析,確定主謂賓等,然後構建一個句法樹。 使用這種方法,機器學習在語言之間轉換句法單元,並通過單詞或短語翻譯其餘部分,這將徹底解決字對齊問題。
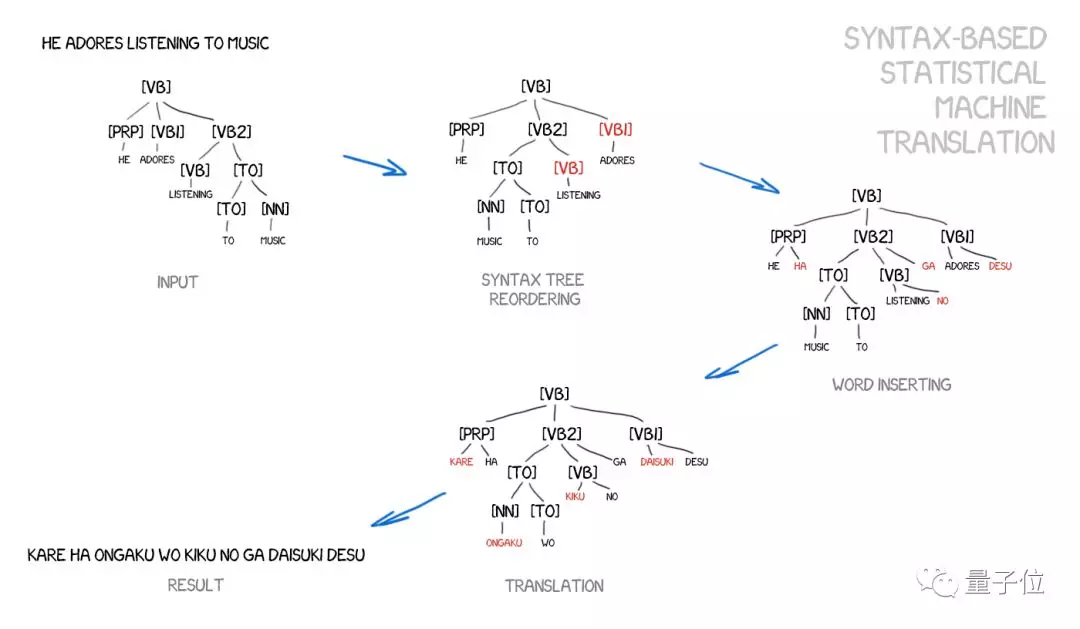
問題是,句法分析的效果非常不好。 不少科學家都嘗試用句法樹來解決比分析主謂賓更複雜的任務,但每次都鎩羽而歸。
神經機器翻譯 (NMT)

2014年,一篇關於在機器翻譯中使用神經網絡的論文對外發布。 作者包括蒙特利爾大學的Kyunghyun Cho、Yoshua Bengio等人。
但這篇很有意思的論文並未引起廣泛關注,但是谷歌注意到了,他們立刻開始動手。 兩年後,也就是2016年9月,谷歌宣布了一個顛覆性的進展——神經機器翻譯。
與之相關的論文,共有31位作者。 谷歌也宣布把這個新的技術應用到谷歌翻譯等產品之中。 神經機器翻譯是怎麼工作的呢?
我們先從畫畫說起。 對於一隻小狗,如果能用語言準確描述小狗的特徵,即便你從來沒有見過這隻狗,也能根據描述畫出一隻類似的小狗。
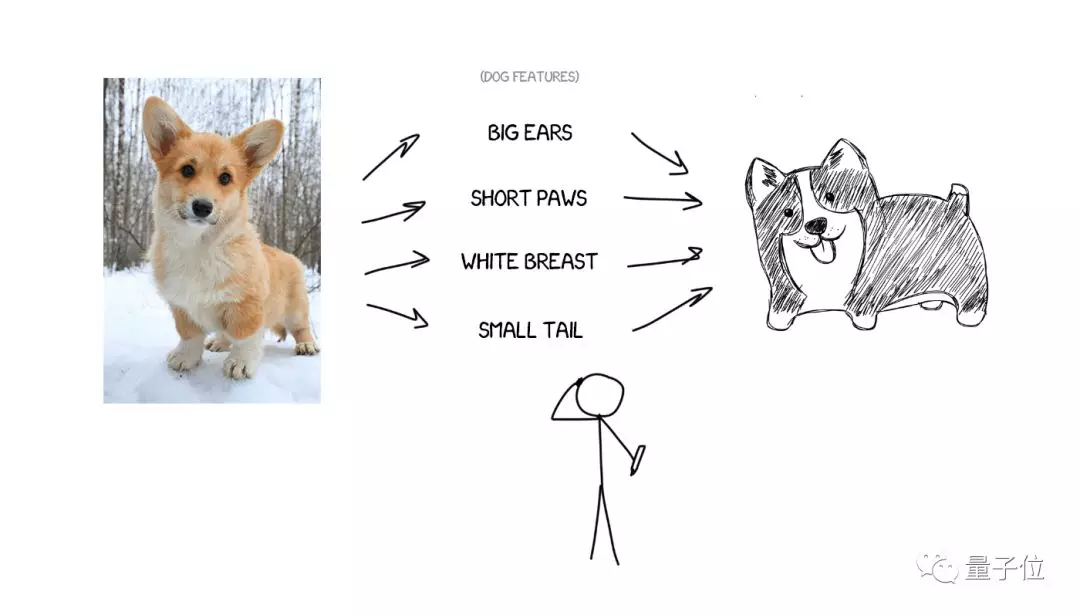
翻譯同理。 如果可以找到一句話裡的特徵,也可以將一種語言的文字,翻譯成另外一種語言。 問題在於,怎麼找到這些特徵?
三十年前,科學家們已經在嘗試創建通用語言代碼,最後以失敗告終。 但現在,我們有了深度學習,找特徵的事情它最擅長。 卷積神經網絡CNN適合處理圖片,而在文本領域,循環神經網絡RNN更適合。
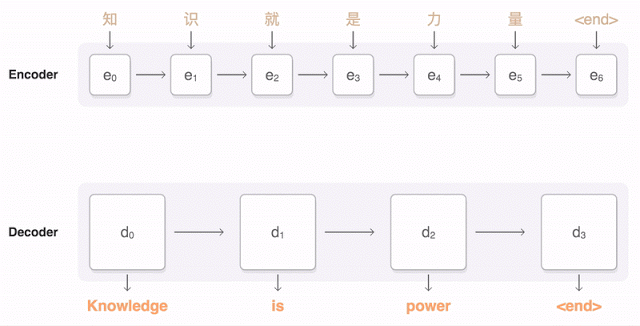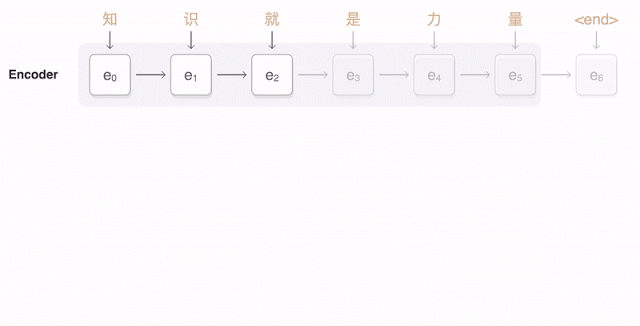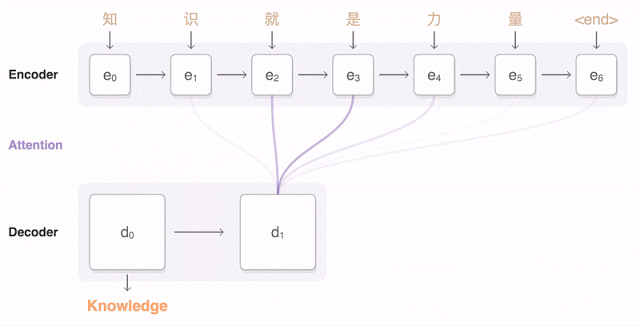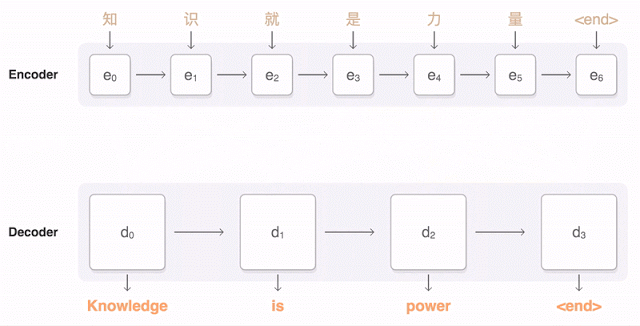
兩年來,神經機器翻譯可以說是一種顛覆。 神經機器翻譯的單詞錯誤減少了50%,詞彙錯誤減少17%,語法錯誤減少19%。
以前統計機器翻譯的方法始終以英語為本。 如果從俄文翻譯成德文,機器需要先把俄文翻譯成英文,然後再從英文翻譯成德文,中間會產生兩次損失。 而神經機器翻譯不需要這樣。 於是兩種語言之間即便沒有詞典,也能雙向翻譯,讓說這些語言的人彼此之間互相理解。

谷歌發布九種語言的神經機器翻譯被稱為GNMT。 它由8個編碼器和8個RNN解碼器層構成,解碼器網絡中還有註意力連接。
這套系統還引入了眾包機制。 用戶可以選擇他們認為最正確的翻譯版本,在某種程度上,這相當於幫助谷歌的數據打標籤,以及幫助訓練神經網絡。
結論和未來
每個人都對“巴別魚”這個概念感到興奮,它是科幻喜劇《銀河系搭便車指南》中虛構的一種生物。 “巴別魚”以聲音中的語言概念為食,消化後排出跟寄主同調的腦波。 只要塞到耳朵裡,就可以聽懂各種語言。 所以,“巴別魚”也成為即時語音翻譯的代名詞。
目前各家在這方面也有所進展。 例如穀歌推出了Pixel Buds,而在國內,網易有道、科大訊飛、搜狗等公司也都先後推出了翻譯機產品。
最近有個朋友就試用了一台最新的產品。 翻譯出來是這樣的:
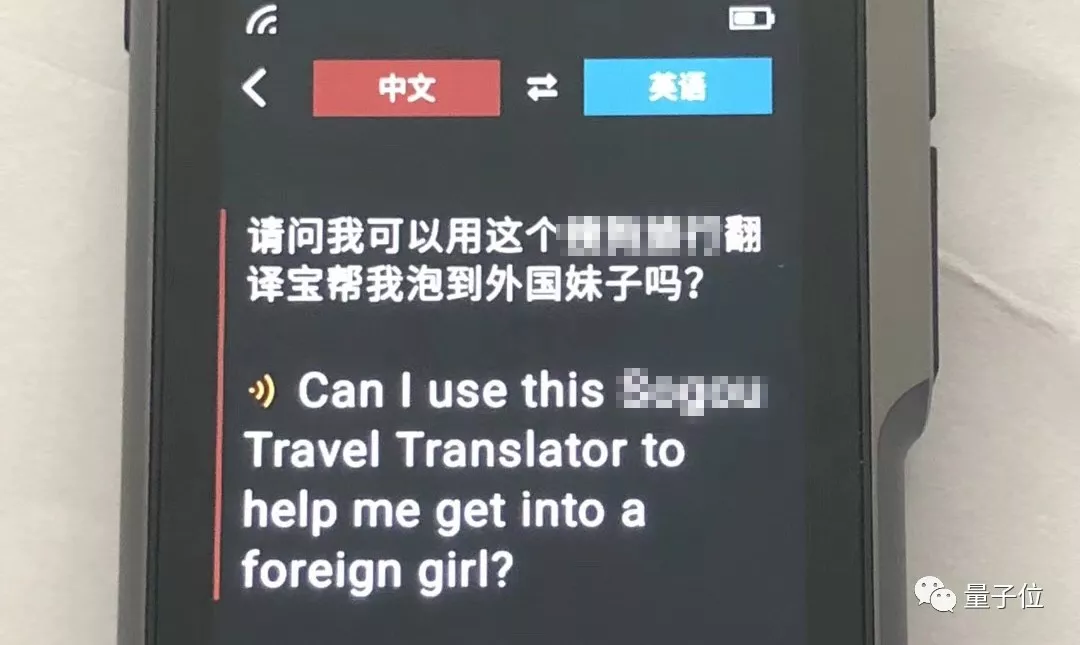
當然還有很多的進步空間。 例如目前訓練神經網絡,暫時只能通過一組組平行語料。 神經網絡還不能像人類一樣通過自主閱讀來提高翻譯技能。
不過已經有人開始這方面的嘗試了。 比如這篇論文Word Translation Without Parallel Data,幾位作者來自Facebook AI Research等機構。

本文由 量子位 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/236023.html