聽說過“睡夢羅漢拳”麼?
電影《武狀元蘇乞兒》中,周星馳在夢中得到老乞丐心法傳授,學會了睡夢羅漢拳。

只是睡了一覺,醒來就武功天下第一。

邊睡邊學習,可能不少同學都YY過……真正做到能有幾人?
沒想到,現在AI已經學會了。
剛剛,兩位人工智能界的大牛:Google Brain團隊的David Ha(從高盛董事總經理任上轉投AI研究),瑞士AI實驗室的Jürgen Schmidhuber(被譽為LSTM之父),共同發布了最新 的研究成果:World Models(世界模型)。

簡而言之,他們教會了AI在夢裡“修煉”。
AI智能體不僅僅能在它自己幻想出來的夢境中學習,還能把學到的技能用到實際應用中。
一眾人工智能界同仁紛紛發來賀電。
還有人說他們倆搞的是現實版《盜夢空間》,並且P了一張電影海報圖:把Ha和Schmidhuber頭像換了上去……

這種神奇能力是怎麼回事?
量子位結合兩位大牛的論文,嘗試解釋一下。
在夢裡開車
在夢境中學,在現實中用,可以說是高階技能了,我們先看一個比較基礎的:
在現實裡學,到夢境中用。
David Ha和Schmidhuber讓一個AI在真正的模擬環境中學會了開車,然後,把它放到了“夢境”裡,我們來看看這個學習過程:
先在真實的模擬環境中學開車:

當然,上圖是人類視角。 在這個學習過程中,AI所看到的世界是這樣的:

把訓練好的AI智能體放到AI的夢境中,它還是一樣在開車:

這個夢境是怎麼來的? 要講清楚這個問題,量子位還得先簡單介紹一下這項研究的方法。 他們所構建的智能體分為三部分,觀察周圍世界的視覺模型、預測未來狀態的記憶模型和負責行動的控制器。
負責做夢的主要力量,就是其中的記憶模型。 他們所用的記憶模型是MDN-RNN,正這個神經網絡,讓Google Brain的SketchRNN,能預測出你還沒畫完的簡筆劃究竟是一隻貓還是一朵花。

在開車過程中,記憶模型負責“幻想”出自己在開車的場景,根據當前狀態生成出下一時間的概率分佈,也就是環境的下一個狀態,視覺模型負責將這個狀態解碼成圖像。 他們結合在一起生成的,就是我們開頭所說的“世界模型”。
然後,模型中的控制器就可以在記憶模型生成出來的虛假環境中開車了。
在夢裡學打Doom
做夢開車很簡單,但兩位大牛的研究顯然不止於此。 既然AI幻想出來的環境很接近真實,那理論上講,他們這項研究的終極目的也是可以實現的:讓AI做著夢學技能,再用到現實中。
這一次,他們用了VizDoom,一個專門供AI練習打Doom的平台。
“做夢”的主力,又是我們前面提到過的記憶模型。 和賽車稍有不同的是,它現在不僅需要預測環境的下一狀態,為了讓這個虛擬環境盡量真實,同時還要預測AI智能體的下一狀態是死是活。
這樣,強化學習訓練所需的信息就齊全了,夢境中的訓練,GO!

夢境重現了真實環境中的必要元素,和真正的VizDoom有著一樣的遊戲邏輯、物理規則和(比較模糊的)3D圖形,也和真實環境一樣有會扔火球的怪物,AI智能體要學著 躲避這些火球。
更cool的是,這個夢境可以增加一些不確定因素,比如說讓火球飛得更沒有規律。 這樣,夢中游戲就比真實環境更難。
在夢境中訓練之後,AI就可以去真正的VizDoom中一試身手了:
AI在VizDoom中的表現相當不錯,在連續100次測試中跑過了1100幀,比150幀的基準得分高出不少。
怎麼做到的?
他們所用的方法,簡單來說就是RNN和控制器的結合。
這項研究把智能體分為兩類模型:大型的世界模型和小型的控制器模型,用這種方式來訓練一個大型神經網絡來解決強化學習問題。
具體來說,他們先訓練一個大型的神經網絡用無監督方式來學習智能體所在世界的模型,然後訓練一個小型控制器使用這個世界模型來學習如何解決任務。
這樣,控制器的訓練算法只需要在很小的搜索空間中專注於信任度分配問題,而大型的世界模型又保障了整個智能體的能力和表達性。
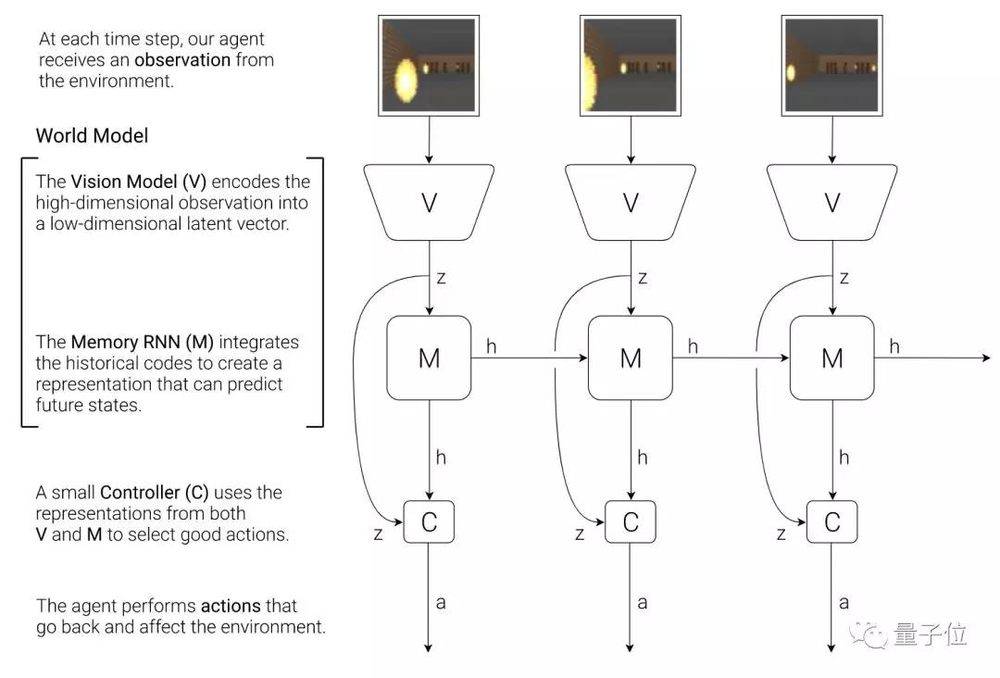
這裡的世界模型包括兩部分,一個視覺模型(V),用來將觀察到的高維信息編碼成低維隱藏向量;一個是記憶RNN(M),用來借歷史編碼預測未來狀態。 控制器(C)借助V和M的表徵來選擇好的行動。
在我們上面講到的開車、打Doom實驗中,視覺模型V用了一個VAE,變分自編碼器;記憶模型M用的是MDN-RNN,和谷歌大腦讓你畫簡筆劃的SketchRNN一樣;控制 器C是一個簡單的單層線性模型。
把這三個模型組裝在一起,就形成了這項研究中智能體從感知到決策的整個流程:
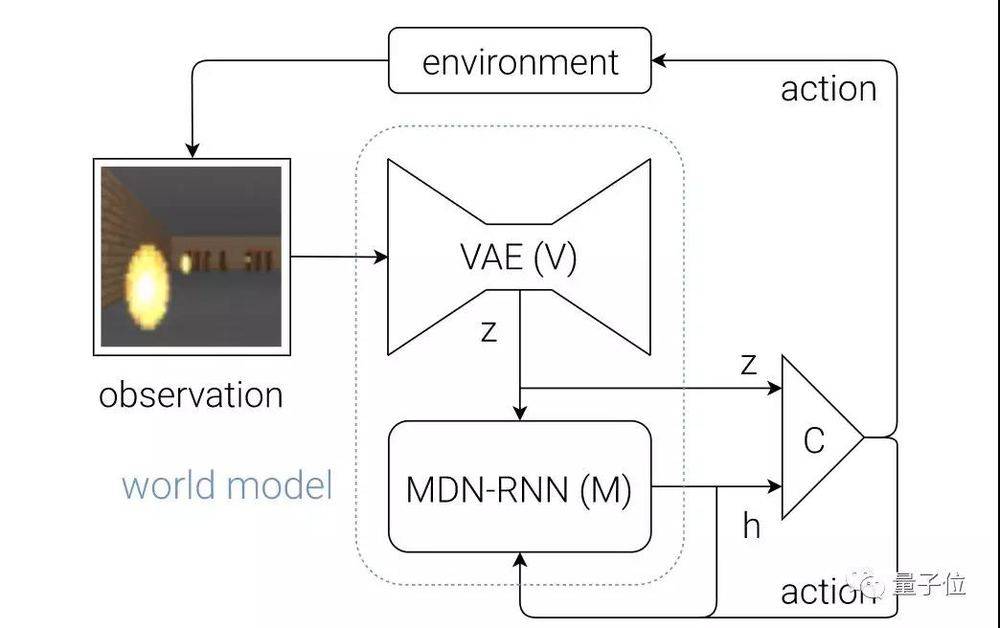
視覺模型V負責處理每個時間步上對環境的原始觀察信息,然後將這些信息編碼成隱藏向量zt,和記憶模型M在同一時間步上的隱藏狀態ht串聯起來,輸入到控制器C,然後 C輸出行為向量at。
然後,M根據當前的zt和at,來更新自己的隱藏狀態,生成下一步的ht+1。
這有什麼用?
讓AI會“做夢”,還能在“夢境”中學習,其實有很多實際用途。
比如說在教AI打遊戲的時候,如果直接在實際環境裡訓練,就要浪費很多計算資源來處理每一幀圖像中的遊戲狀態,或者計算那些和遊戲並沒有太大關係的物理規則。 用這個“做夢”的方式,就可以在AI自己抽象並預測出來的環境中,不消耗那麼多計算資源,一遍又一遍地訓練它。
在這項研究中,他們還借助了神經科學的成果,主要感知神經元最初出於抑制狀態,在接收到獎勵之後才會釋放,也就是說神經網絡主要學習的是任務相關的特徵。
將來,他們還打算給VAE加上非監督分割層,來提取更有用、可解釋性更好的特徵表示。
本文由 量子位 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/237872.html