2017年,由李飛飛團隊創建的鼎鼎有名的ImageNet視覺識別挑戰賽走向謝幕。 回顧往昔,ImageNet在2012年引爆了深度卷積神經網絡,並繼而在3年後推動谷歌、微軟、百度等公司在圖像識別領域超過人類。 在圖像識別領域,ImageNet可謂功不可沒。
而如今在另一個數據集上,或許也正上演同樣的故事。 在2018年伊始,阿里巴巴和微軟亞洲研究院相繼刷新了斯坦福大學發起的SQuAD文本理解挑戰賽成績,機器閱讀理解評分超過人類! 這意味著機器閱讀理解的能力已經開始在“指標”上超越人類,又是否能夠引領自然語言處理領域的下一場革命?
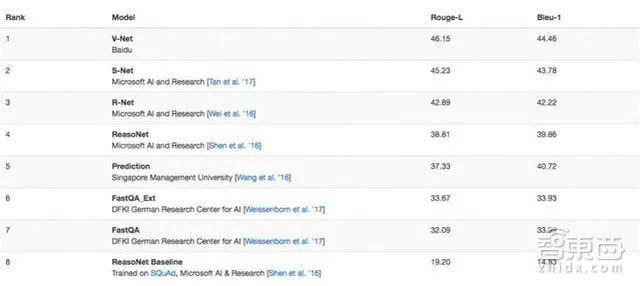
近日,百度自然語言處理團隊也拿下了微軟MS MARCO機器閱讀理解測試首名。
“自然語言處理是人工智能桂冠上的明珠”,這句話反應了NLP發展之艱鉅。 而這些公司們陸續在NLP比賽上取得勝利,是否意味著機器閱讀理解真的能夠超過人類? 我們採訪了近10位NLP領域的資深人士,他們中既有NLP類創業公司的CEO/技術高管,又有大公司的技術負責人等。
通過溝通我們認識到,機器在閱讀理解的評分上超過人類,也許是NLP發展歷程上的一次重大突破,意味著機器在“指標”上對人類的勝利,機器也確實可以在限定場景下有超過 人類的表現。 但 這終究是一場“指標性”勝利,想要做到能理解會思考,機器還有“萬里長征路”要走 。
一、公開數據集掀起算法競賽
在談NLP發展現狀之前,我們先看一下斯坦福的SQuAD和微軟MS MARCO兩個機器閱讀理解數據集。
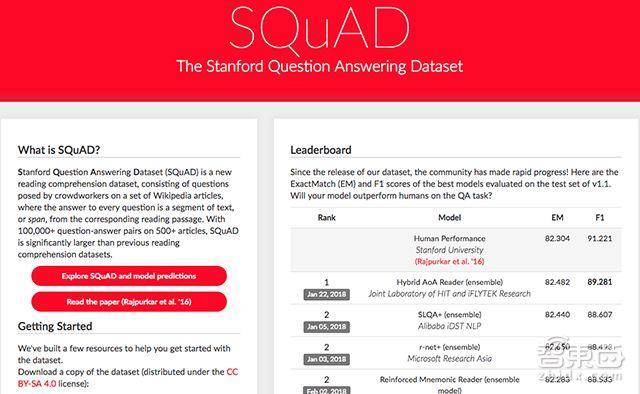
SQuAD是斯坦福大學於2016年推出的閱讀理解數據集,也是行業內公認的機器閱讀理解標準水平測試,該數據集包含來自維基百科的536篇文章及共計十萬多個問題。 在閱讀數據集內的文章後,機器需要回答若干與文章內容相關的問題,通過與標準答案對比來獲取得分。 這個數據集有兩個評判標準:EM代表完全匹配,即機器給出的答案和標準答案一樣才算正確;F1代表模型的整體性能。
在EM值上,人類在該項得分為82.304,而阿里和微軟在前不久的得分中稍高於人類得分,分別為82.440和82.650,這也是為何阿里和微軟稱機器閱讀理解得分超過人類。 目前整體排名第一的是科大訊飛與哈工大聯合實驗室,EM得分為82.482,F1得分89.281。
微軟MARCO也應用在機器閱讀理解領域,是由10萬個問答和20萬篇不重複的文檔組成的數據集。 相比SQuAD,其最大不同在於數據集中的問題來自微軟自家必應搜索引擎。 根據用戶在必應中輸入的真實問題模擬搜索引擎中的真實應用場景,可以看出微軟希望藉此數據集提升用戶獲取信息方面的能力。
百度稱,MARCO的挑戰難度更大,它需要測試者提交的模型具備理解複雜文檔、回答複雜問題的能力,百度之所以選擇該數據平台,是更致力通過技術應用解決搜索中的實際問題。
可以看出,在機器閱讀理解比賽中,百度、阿里、科大訊飛、微軟等公司取得較為優異的排名,也體現出我國對於NLP方面的研究在全球也處於前列的位置。 這些閱讀理解的數據集也使訓練大規模複雜算法成為可能。 各大公司通過數據集優化算法,從而解決自然語言實際問題,進一步推動自然語言處理的發展。
二、一場限定邊界場景的“指標性”勝利
針對阿里、微軟、百度等在機器閱讀理解方面的表現,我們採訪的NLP領域資深人士均表示,機器閱讀理解取得的成績確實是一個突破性的進展,其可能是繼機器翻譯之後又一個取得重要 進展的NLP領域;但 機器閱讀理解仍然是一種限定邊界的任務,遠遠達不到真正的歸納和推理 ,因此對於人類的勝利更應該說是“指標”上的勝利。
搜狗搜索事業部NLP技術負責人劉明榮談到,在斯坦福SQuAD比賽中,阿里和微軟評分超過人類這一成績確實是NLP領域一個重要的進步,表明在特定任務上機器已經取得了和人類相當的水平 ,在特定場景下已經做到了接近實用水平。
認同這一觀點的還有思必馳NLP資深工程師葛付江,他指出一方面機器閱讀理解屬於篇章理解,需要從篇章中找到相關信息並回答問題,相對於詞語和句子理解這是一項比較高級的 NLP任務;另一方面機器閱讀理解是一種邊界限定的場景式機器理解,問題的前提條件和場景邊界都比較清楚,所以機器閱讀理解超過人類是以“設定文章集合、有限問題”為前提 條件的。
相比前幾年,阿里和微軟在機器閱讀理解中評分超過人類,確實體現了NLP技術的快速進步和發展。 但同時,葛付江也表示,機器閱讀理解離真正的人類水平還有很長的路要走。

關於機器閱讀理解超過人類的說法並不正確 ,獵戶星空首席科學家閔可銳向智東西解釋到,特定任務數據集可以說是對特定任務的一個代理,我們的測試是基於這個代理任務,所以代理本身的有效性很關鍵。 比如語音識別中採用播音員,在無噪聲情況下的數據算法能夠達到很高的準確率,但未必代表語音識別超過人類,因為這個代理任務過於簡單。
同樣的SQuAD的數據設計將文本限定在維基上,並且只有500多篇內容,這也相當於作了簡化。 靈隆科技首席科學家湯躍忠博士也指出這類比賽都是限定條件的,其評價指標也有一定的片面性。
而同樣是閱讀理解任務,智東西了解到,百度也公佈過一個不論在難度還是在規模上更大的DuReader數據集,目前最好的模型與人的準確率相比也有近20個點的差距 。 因此儘管通過神經網絡端到端的架構機器閱讀理解有突破性進展,但遠談不上超過人類。
康夫子創始人兼CEO張超補充到,這只說明基於端到端的深度學習框架可以在“閱讀理解”任務上做出不錯的成績,本身還是深度學習在NLP應用領域的探索。 但大多數問題仍沒有到達需要“推理”的級別,對於機器閱讀理解“能理解會思考”的終極目標來說,現在還是只萬里長征的開始。
三、NLP發展現狀:初落行業,限定場景大有可為
微軟全球執行副總裁沈向洋曾說過,人工智能的突破在於自然語言理解,“懂語言者得天下”。 自然語言處理也被稱為“人工智能桂冠上的明珠”,足以體現該領域之難之重要。
而經過近年深度學習的發展,目前NLP開始落地行業,可謂“初出茅廬”, 通過限定邊界場景,已經開始進入家居、車載、金融、醫療、教育等眾多領域 ,未來發展前景不可限量。
科大訊飛北京研究院院長、AI研究院副院長王士進談到,隨著深度學習技術的發展,NLP在人機問答、神經機器翻譯、閱讀理解、用戶畫像和精準推薦等領域取得了很 大的技術突破,並且在金融、教育、法律、醫療等領域逐步廣泛應用。
具體來看,搜狗劉明榮表示NLP經過幾十年的發展,目前在詞法、句法等淺層語言分析任務上已經達到相當高的實用水平。 在一些具體的NLP任務上,比如語音方面的語音識別和合成,文本方面的文本分類、情感分析、文本摘要、機器翻譯等,也基本達到了實用階段。
而思必馳葛付江從知識圖譜的維度談到,伴隨著知識圖譜技術的發展,NLP在垂直場景上的產品化落地也在加快,諸如智能家居、車載、機器人、企業對話服務等場景。 當今,NLP進步的動力在於真實的應用場景正在不斷出現,與此同時也將帶來更多的場景需求,創造更多數據,進而推動NLP的進一步發展。

而以機器閱讀理解來說,機器能夠超過人類的在於“指標”,但真正在通用領域超過人類,在較長時期內還是不現實的。
“ 以機器閱讀理解任務來說,機器應該很快會從指標上超過人類的現有水平,但真正的閱讀理解過程需要深層的推理和歸納,這恰恰是目前機器所欠缺的,還需要通過底層算法 的突破才有可能實現機器在NLP領域的真正突破。 ”王士進談到。
而人做閱讀理解和機器做閱讀理解是兩個層面的事。 康夫子CEO張超表示,對於機器來講,閱讀理解任務可抽象為“把文章和問題作為輸出,來判斷哪個答案最為可能”,這時題型或者重點一旦發生變化,整個機器的效果可能直線 下降。 而人的閱讀理解則是讀完後的融會貫通,真正做到理解、運用、推理甚至想像。
但劉明榮也指出,儘管通用領域機器還不能夠超越人類,但在特定行業下,基於對特定行業資料的理解所產生的機器人。 如客服機器人,至少可以達到和人類的理解水平相當,並且在整體效率上遠遠超過人類。

可以看出,目前NLP的商業化以及落地行業才剛剛開始,如果將NLP放到一條發展線上,目前還處於中初期,限定邊界下才大有可為。 由於其涉及到大量認知層面的理解,仍然是一個十分有挑戰的問題,在知識表達、常識表達和知識推理上還有很長的路要走。
四、NLP發展的關鍵在於垂直領域快速落地
近年來隨著智能音箱在全球市場的盛行,語音交互持續火熱,機器翻譯、機器同聲傳譯等快速發展,對NLP的進步產生巨大需求。 面對當下NLP發展現狀,業內資深人士也從數據、底層算法、知識圖譜、應用等維度給出進一步發展的辦法。

思必馳葛付江認為,大規模的數據集或數據平台、積極開放的研究氛圍對於NLP技術的發展至關重要。 而垂直領域產品化落地將是推動NLP技術進步最重要的動力,它會帶來更多的流動數據、研究投入和社會資源,推動NLP進一步的發展。
結合實際應用需求,搜狗劉明榮認為產學研相結合是推動NLP發展的一大動力。 結合實際問題,建立大規模評測數據和規範的評測方法,讓學術界和工業界共同參與,才能夠更好的解決目前存在的難題。
獵戶星空閔可銳表達了其對知識和語義表達的興趣,通過近兩年有較大發展的神經機器翻譯技術來看,他認為這一定程度上證明了語義向量表達的可能性,獵戶星空也在探索 通過無標註數據或可大量獲取的弱標註數據來進行精確的語義建模。
此外,康夫子CEO張超從自身醫療機器人的維度談到,下一步推動NLP發展可能再知識圖譜層面,通過知識圖譜構建機器對任務的認知能力,再加以語義、交互等處理工具,通過應用 才能更好推動一個行業的發展。
而強調通過知識圖譜來推動NLP發展的不止張超,還有阿里AI Labs北京研發中心負責人聶再清博士。
他希望建立一個知識圖譜的生態平台,讓大量的開發人員在上面去建立知識圖譜,使用積累的知識圖譜,不斷擴大知識圖譜在常識性和專業性方面的積累,即共建知識圖譜,產生1 +1>2的效果。
結語:引爆人工智能下一場革命?
不得不說,機器閱讀理解在“指標”上已超過人類,未來將會在“指標”上全面超過人類,機器閱讀理解又能否向圖像識別一樣,引領人工智能的下一場革命? 隨著NLP方面的突破,智能助手、智能客服、機器翻譯等都將大幅提升,惠及金融、教育、家居、車載等眾多行業!
但歸根結底,機器不能像人一樣做到真正的理解、融會貫通、推理,其只是一場限定邊界場景的“指標性”勝利。 機器想要做到能理解會思考,現在還只是萬里長征的開始。
而作為人工智能桂冠上的明珠,NLP技術的重要性和挑戰性不言而喻。 在當下將NLP在垂直領域快速產品化落地、知識圖譜的構建以及底層算法的突破都將進一步推動認知智能的發展。
本文由 國仁 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/233577.html