採訪 | 王藝
過去一年,從技術向產業,有哪些值得記住的人和事? 未來一年,AI 場景化落地還有哪些可能性? 8 位 AI 行業的局內人,向我們講了講他們的故事和看法。
1998 年 11 月 5 日,北京知春路希格瑪大廈,微軟中國研究院(後更名為微軟亞洲研究院(MSRA))成立了。 毫無意外地,從當年比爾蓋茨在總部建立微軟研究院到 MSRA,自然語言都是最早確定的小組之一。
「得語言者得天下」,微軟全球執行副總裁沈向洋說過。 其中的考量很簡單,語言難,相比於以語音、圖像為代表的感知智能層,以自然語言處理技術為代表的認知智能層是當下人工智能發展的主要難題。
語言也意味著一切。 「如果 NLP 取得突破的話,那麼知識獲取就會突破,推理就會突破,解題、回答問題、預測等能力都會取得突破。」微軟亞洲研究院副院長周明說。 他認為,語言一旦突破,會帶動認知智能的突破,帶動整個人工智能的突破。
1999 年,清華大學任教的周明,在李開復邀請下加入微軟亞洲研究院負責自然語言計算組。 過去十八年,他帶領團隊解決語言相關的人工智能基礎問題,自然語言理解業務已經覆蓋中文,日文,英文三種語言,在分詞、句法分析、語義分析、機器翻譯、情感分析、問答、理解 、文摘、搜索引擎、聊天對話等技術點都有所佈局。
這些研究成果逐漸應用於微軟Office、必應搜索、Windows 等產品,團隊還參與研發包括微軟輸入法、英庫詞典(必應詞典)、中英翻譯、微軟中國文化系列(微軟對聯、微軟字謎、 微軟絕句)等重要產品和項目。 微軟小冰(中國)、Rinna(日本)、Zo(美國)等聊天機器人系統開發的背後,同樣也有他們的身影。
在這次專訪中,周明向機器之能講述了這一年 NLP 圈的起伏變化。 他認為,如果要用一個詞來形容 NLP 圈的 2017,那這個詞應該是「想像」。
以下為對話原文,機器之能做了不改變原意的整理。
Q1:微軟亞洲研究院在 NLP 領域的技術佈局包括哪些?
這張圖能很好的展示微軟 NLP 的佈局,我們有產業、產品和研究三個層面的佈局。
產品佈局主要是通過必應(Bing)搜索體現的,搜索是很考驗自然語言處理能力的一項應用,因為它涉及到對問題、文檔進行理解。 理解能力加強後,搜索的準確度就會有所加強。 另一方面有了理解能力,用戶在搜索框提一個問題,系統自然就能返回一個答案,不需要像以前一樣,需要用戶從若干個頁面鏈接中自己尋找。 此外,搜索業務還能夠與問答系統進行整合,通過對話和回答為用戶提供信息服務。
產品層面除必應團隊外,我們還有微軟商業智能團隊,他們和必應團隊一樣,著重解決如何將自然語言技術做好、落地、實現很好的用戶體驗這個問題。
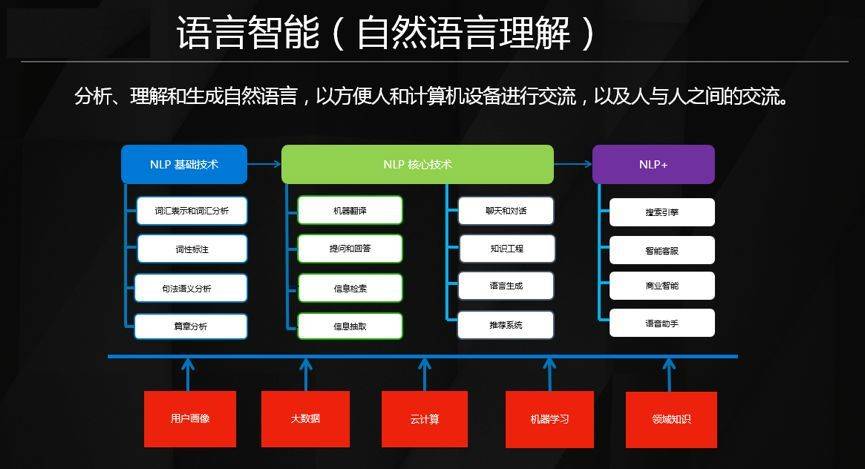
研究層面微軟在總部和 MSRA 都有佈局,主要從事圖中 NLP 基礎技術和核心技術兩個欄目下的這些技術點的研究。 比如偏基礎研究的團隊會研究知識如何表達(Embedding),如何做語義分析這類問題;偏應用技術的團隊會解決機器翻譯、問答理解、信息檢索、推薦、聊天對話等問題。
產品團隊和技術團隊合作,就是 NLP+,解決搜索引擎的關鍵技術、客服、商業智能、語音助手等等問題。 比如我們的智能助手微軟小娜(Cortana),聊天機器人小冰等等。 在底層我們會和用戶畫像、大數據、雲計算、機器學習、知識圖譜等相應團隊合作,我們將他們的成果用在自然語言分析和推理上。
所以說我們每一個團隊在做技術的時候都不是獨立的,都可以得到周圍相關團隊的支持,我們是按全局一盤棋的設想來佈局的。
Q2:那麼作為研究院,具體來說微軟亞洲研究院如何與產品部門,例如微軟(亞洲)互聯網工程院進行協作的?
自從建院以來,MSRA 一直強調要做有用的研究,所以我們和產品組有很好的合作,我們會互相了解對方的需求。 我們研究院知道公司的產品戰略,知道他們需要用到怎樣的技術,對於有些還不存在的技術,我們會想要超前一些,把他們能用到的技術提前開發出來。 另外產品部門也知道我們的需求,比如我們需要數據,產品組就會提供很多數據來給我們使用。
一旦我們研究院把某些技術突破了,產品組就能很快地將技術融入到他們的產品之中。 因為我們雙方已經很默契了,所以基本上從我們的技術成型,到他們上線,「一夜之間」就能完成。 像上個月我們參與 SQuAD 比賽的 R-NET 就已經在微軟的產品中得到使用。 當然,有的時候產品組需要重新編寫代碼,因為產品需要有安全性、速度等等的考量,還要跟已有的系統很好地配合。
Q3:過去一年,MSRA NLP 取得了哪些進展?
這一年的進步可以總結成四個方面,神經機器翻譯、聊天機器人、閱讀理解、創作。
首先神經機器翻譯,這裡有幾個例子。 紅色字體是原來做的不好的地方,現在有了神經機器翻譯,能夠做的非常好,句子非常流暢,用詞非常準確,和人的標準答案相仿,甚至有的地方你會感覺到比人類 翻譯的還要好。

神經機器翻譯發展的前提是有大規模的雙語對照語料,只要數據夠大,就能達到這樣的效果。 所以在科技新聞領域,因為語料很多,現在翻譯效果已經能夠達到人類的水平,但是在一些其他語料較少的領域,比如科學論文,翻譯水平還是不行。
去年微軟和華為合作,在 Mate 10 手機中嵌入微軟的神經網絡機器翻譯,可以算得上是在終端運行神經網絡機器翻譯的第一例。 在手機上運行神經網絡,由於運算速度、存儲能力的限制,微軟機器翻譯產品團隊對網絡做了不少針對性的優化。
聊天機器人方面,我們和微軟(亞洲)互聯網工程院合作,從 2014 年起推動微軟小冰,後來有了日本、美國、印度、印度尼西亞一共五個版本,可以說進展還是很快的。

現在小冰各個產品的用戶總和已經達到兩億多,平均交互輪數是 23 輪,我認為這很了不起。 小冰的技術落地後,小冰團隊最近又做了一個音箱,讓她以實體的形式走進家庭。 微軟小冰之外我們還有智能助手微軟小娜(Cortana),能夠完成面向任務的對話交互。
閱讀理解方面我們剛剛在 SQuAD 數據集上的 EM 分值上超越了人類,這是一個突破,帶動了一些產品的進展,例如搜索引擎、客服等。
創作的話我們探索了一些對對聯、寫詩、譜曲等等。
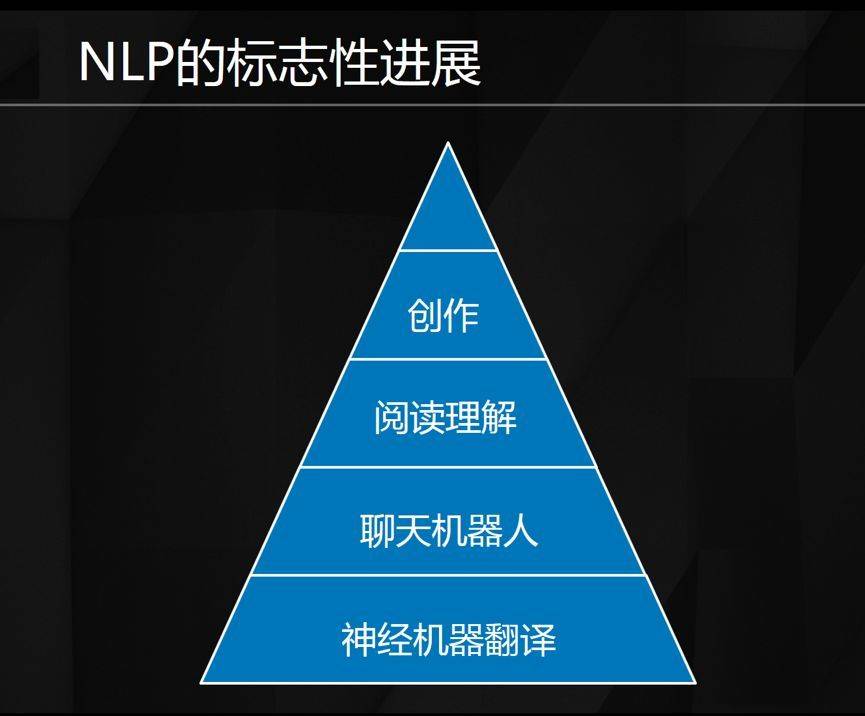
這四個方面代表了我們在 NLP 領域的一些進步。 在這張圖中我用金字塔形來表示這四個技術之間的關係,難度是逐級上升的。
最下面神經網絡機器翻譯現在效果已經非常好了,因為它是 Single-turn,一句進一句出。 聊天機器人就要難一些,是 Multi-turn,對以前聊的東西也要有記憶。 機器閱讀理解除了當前的句子,上下文,還要融入世界知識,會更難一些。 最後創作,最開始我們都不了解要怎麼建模,因為創作是感性的東西,比如寫詩、寫詞,強調靈感和文采,要為這些東西建模其實是很難的。 目前我們在創作方面只是能利用簡單的技術進行模仿,離人類真正的創作水平還很遠。
再往上其實還有更難的,比如解決一個問題、做決策、做預測,都是和自然語言相關的,是認知智能的一部分,現在我們還沒有做很多。
Q4:除了在現有產品中能夠使用到的技術,MSRA 還做了哪些腦洞大開的創新?
有很多,舉個例子,我們做的對聯。 微軟沒有一個產品能用到它,必應、Office、Azure 都用不上,但是我們認為對聯是人工智能的一個重要標誌,因為它代表著創作,創作是當前人工智能還需要摸索的一個領域。
我認為做腦洞大開的創新有兩層意義,一是促使你去思考和解決人類常見的問題,二是開腦洞產生的技術可以旁徵博引,比如我們做了對聯,這裡面的一些技術可以 放到微軟的機器翻譯裡面,提高機器翻譯的準確率。 實際上科學之間是相通的。
Q5:NLP 技術在整個人工智能領域中,處在怎樣的地位? 有怎樣的意義?
這個要從技術本身講起了。 因為圖像、語音技術都是 Single-turn 的技術,就是一個輸入一個輸出。 而自然語言是 Multi-turn,做完一次輸入輸出後,要把結果作為下輪輸入的一部分繼續輸出。 最典型的例子就是多輪對話,系統需要結合之前的對話生成內容;還有就是機器閱讀理解,需要考慮上下文;寫詩,一句詩是一個Single-turn,那寫個絕句就是做四次Single- turn,而每一次都要將之前的結果考慮進去。
這有什麼意義呢? 我認為可以理解為兩個層面。 首先,從 NLP 技術本身來說,有很多原來不敢想像的應用現在可以落地了,比如自動客服、神經網絡機器翻譯,原來不敢做,現在可以往前走一點了。 第二層我認為,因為 Multi-turn 是其他智能領域還做不好的技術,一旦這一技術有所突破,再加上世界知識的普遍使用,從技術上會反哺圖像識別和語音識別等。 他們現在是 Single-turn,將來有可能是 Multi-turn;他們現在沒用到背景知識,將來有可能可以結合背景知識做一些事情。
所以說 NLP 對其他智能,對整個人工智能領域都會有推進作用,這也就是為什麼沈博士(指沈向洋)說「得語言者得天下」的原因。
Q6:你在 ACL 等國內、國際學術會議中也擔任要職,那麼就你觀察,這一年在理論研究層面,有哪些明顯的趨勢?
自四年前語言學相關議題大規模引入神經網絡以來,效果相較於統計時代有了很大的提升。 除了下圖展示的這些基本的問題之外,這些年我們著重解決的問題還包括如何用小數據訓練出與大數據相仿的結果、如何用單語數據幫助雙語數據進行翻譯水平的提升(因為有 的場景下雙語語料很少,卻有大量的單語數據)、強化學習在聊天和機器翻譯中的應用等。
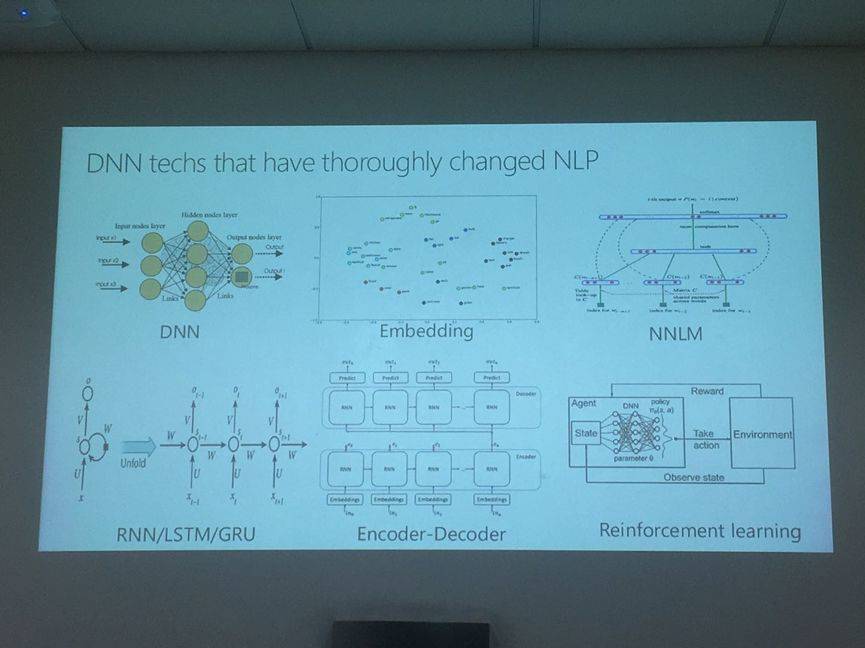
具體到這一年的話,在神經網絡機器翻譯任務上我們看到了更多單語數據的加入。 比如我們研究院劉鐵岩博士領導下的對偶學習的研究對神經網絡機器翻譯的影響,就用大規模單語數據,提高了神經機器翻譯的水平。
在對話方面,我們已經能夠利用用戶的當前輸入和上下文以及用戶畫像進行個性化建模,這裡面涉及到很多模型理論上的研究和設計,比如怎樣做用戶畫像,怎樣對上下文信息進行編碼,怎樣 通過注意力模型將最重要的信息捕捉到,以及怎樣生成上下文相關的、用戶個性化的、有主題知識的、不空洞回复,也表現出了從Single-turn 到Multi-turn 的過渡。
閱讀理解是去年一個非常強的熱點,也就是說我們的技術在上圖的金字塔中已經走到了閱讀理解這一步,利用端到端的訓練,引入背景知識來解決閱讀理解問題。
再往上,把自然語言技術延伸到其他領域,例如音樂、創作,去年我們做了一些很好的嘗試,也取得了一些進展。
Q7:如果用一個詞來形容過去的一年,你會選擇哪個詞?
我覺得是「想像」。 曾經一些我們認為不能解決的任務,比如閱讀理解,或者一些不應該我們NLP 解決的任務,比如音樂,由於有了更好的工具,更大的數據,我們才發現這些東西是能夠解決的,是 能夠和NLP 相結合的,這在之前是不能想像的事情。 這種想像是伴隨著行動產生的,同時又能引領我們走向新的道路。 沒有技術的進步,很多事情我們想都不敢去想。
Q8:未來一年,你對 NLP 相關技術和應用的發展抱有怎樣的期待?
我們還是從這四個方面說,首先神經網絡機器翻譯,未來一年,在典型的場景和領域下,比如新聞,達到人類的水平是可以期待的。 然後在對話領域,客服會有較大的進展,由於問答技術、聊天技術、閱讀理解技術的提升,客服的效率將會被大大提高,但不會完全替代人類客服。
在創作領域,很多新聞可以由機器人來完成。 還有一些過去很多不敢嘗試的,例如歌詞、音樂的創作,我認為明年會有一些好玩的新東西出來,至於說能產生多大的影響,怎樣落地,現在還不可知。 但是作為一種社會現象,我認為在創作領域,明年還是可以期待一下的。
Q9:想要提升創作水平,目前有哪些技術瓶頸?
如果是站在很工程的角度,就是數據不夠。 和機器翻譯等任務相比,寫歌詞、譜曲之類的數據要少很多,所以我們要想辦法獲得更多的數據。 第二就是靈感不高,目前神經網絡所做的創作都是源於已有數據的,所以只能是追隨者,現在機器寫出的歌會讓人有一種似曾相識的感覺,沒有靈感上的迸發。 這是大數據的特點,訓練數據中誰的歌多,就像誰多一些,然而真正有才華的藝術家是很少的,所以要想讓機器有非凡的才華,還是有很長的路要走 。
但是現在機器對創作者可以起到輔助的作用,對於藝術家來說,可以起到提示作用。 比如寫著寫著沒詞了,機器一提詞,可能就會有新的靈感冒出來。 對於普通人來說,機器其實是降低了普通人的創作門檻。
Q10:你認為,在未來,還有哪些新的技術方向有待摸索?
首先我認為多模態的融合會帶來很大的機遇。 就比如說圖像和文字的結合,現在「讀圖」這件事更多的是圖像領域的科研人員在做,NLP 領域的人很少涉足,NLP 研究人員一般是你讀出來什麼,表示成自然 語言的形式,我再進行後續的處理。 但我認為,做 NLP 的人需要了解信號是怎樣輸入進來的,這很重要。 就自然語言來講,在信息的感知層面,現在除傳統的鍵盤輸入外,還有語音輸入、圖像輸入,這和我們人類觀察世界的方式是一致的。 人類在接受外界信號時,實際上在腦海中是形成了一系列的自然語言的表述的,從這個表述出發,我們才會想去創作。 所以說,信號是如何進來的是非常重要的。
圖像和語言充分銜接後,就會產生非常大的機會。 比如跨媒介交流、基於圖文的多媒體問答對話、搜索(直接用圖片搜索或者圖文混合信息搜索)。 其實我們人是不怎麼區分圖片、文字、聲音,因為到腦海中都會變成表述。 這樣類比到神經網絡上,我們也可以對不同類型的信息源同等對待,同等建模,得到一個融合的信息,再基於這種信息進行編碼解碼,然後再生成其他媒介的東西,或者混合媒介的 東西。
這個方向有所突破的話,對機器人領域的發展會非常有幫助。 它感知對方,了解對方是什麼樣的人,說過什麼話,機器人得到對方的一個統一的印象,就可以做出自然的表情和反應。 現在機器人的多模態、人機交互是做不好的,未來可以期待一下。
Q11:對於當前的人工智能行業來說,人才是無法迴避的話題,你認為,當下行業急需怎樣的人才?
我覺得有兩類人才,一個是系統實現型人才,這些人能夠在了解現有的技術方法理論之後,快速解決問題。 我們需要特別特別多這樣的人才,現在中國這樣的人才並不多。 第二類人才是拔尖人才和領軍人才,他們知道現在技術的發展水平和狀況,並且能夠預測未來的一些領域的發展,提出一些新的理念、理論體系,還能夠親自身體力行,帶領團隊讓技術落地 。
從微軟亞洲研究院的角度,我們希望兩者兼顧,因為第一,我們是工業界的研究院,我們要做一些有用的研究來快速幫助提升微軟產品的智能水平,並釋放一些通用的技術給 社會或第三方機構。 第二,作為一個研究院,我們也有使命將最先進的方法、思想、理念釋放出來,幫助整個人類社會。
我們鼓勵跨領域的研究,將不同背景的人湊在一起來解決一個問題。 比如在微軟的對聯、寫詞、譜曲等技術的研究過程中,我們會學習到其他學科的一些方法。 有一些想法在人家學科是常識,沒什麼了不起的,我們學會了之後再反哺到我們的技術中,就很有優勢了,兩邊學科都懂,那你建的模型就比別人好,思路也開闊。 我們希望未來的創新是基於這種跨領域的、交叉學科的。
Q12:微軟亞洲研究院為產業培養了不少人才,同時也面臨著人才流失的問題,這一年情況有所好轉嗎? 對此你怎麼看?
任何公司都有人才流動的問題,有人來有人走,這其實挺正常的。 宏觀上來看,對社會是一個正面的促進,只有人才流動,新興學科才能夠發展起來。 人才都集中在一起,對新的機會視而不見,這也是不科學的。 我們微軟亞洲研究院被稱作黃埔軍校,「校」是什麼意思,有學生來,有學生畢業,這才叫學校。 學生畢業之後還在黃埔軍校,那就不是軍校,那是黃埔軍營。
所以對於我們來說,學校價值的體現就在於我們的學生強,人脈廣。 從我個人角度而言,也不是說一定要讓我的員工留下來天天做自然語言,這對他們來說不一定是最好的事情。 他們應該去做別的方面,甚至圖形圖像、大數據,都可以做。 或者到學校去當教授,培養更多的人才,讓他們盡最大的努力對社會產生貢獻。
整個微軟亞洲研究院的人對此也是有同感的,我們的使命就是把優秀的人才培養出來,讓一般的人才變優秀,優秀的人才變傑出,然後再去引領更多的人,把整個社會 帶動起來,這也是過去20 年來微軟亞洲研究院所秉承的理念。 我們看到很多人才從這裡走出去,實現了自己的人生價值,對社會產生了很大的貢獻,我們樂見此事的發生。
我們和中文信息學會以及中國計算機學會合作舉辦了很多次暑期學校,每一期能夠培養 200 到 300 名研究生和博士生,目前已經十幾年了。 我們還有實習生計劃,自然語言方向已經有 450 多名實習生從我們這裡得到過培訓,他們現在在中國的各個地方、各個公司,現在很多都是領軍人物了。 另外,我們還培養了 20 名左右的博士生和 30 名左右的博士後,這些人除了少數留在微軟,很多也都在其它公司或者學校工作,有一些人已經擔任院長和博導。
但與此同時,我們也反對惡意的人才挖角。 有些公司為了人才不擇手段,甚至連人帶技術一起挖過去,我們認為這是不道德的,一方面觸犯了法律,另一方面也是對人才的不尊重。 因為有的時候,公司挖這個人才過去,一夜之間有了一個新技術,那這個人才對他來說就沒有太多利用價值了,這樣的公司不是抱著培養人才的目的去的,更不 會說讓這個人才培養更多的人,而是一種急功近利型的、短期的行為,我們對此強烈反對。
另外我認為,如果我們的社會是一個金錢至上、薪水至上的社會,對中國赶超世界先進水平會產生很大的阻礙。 多掙一些錢,社會就是先進社會嗎? 我認為是反的,如果一個社會道德體系良好,大家和諧共同發展,就算短期沒有經濟上的顯著表現,長期也一定會勝出。
現在很多在校生,已經沒有了我們當年那種為國家奮鬥終身的意志,哪裡錢多去哪,以後的路以後再說。 我認為這樣一代一代傳下來的話,我們整個行業、整個社會未來堪憂。 微軟作為一個負責任的公司,我們對社會是有使命感的,我們需要對員工、客戶、股東負責,更需要對社會負責。
Q13:你認為,現在我國的自然語言處理技術在世界上處在怎樣的水平?
我認為現在美國第一,中國第二。 這裡有幾個指標,首先在世界上最著名的自然語言領域的學術大會ACL 上,美國無論在投稿率還是錄取率,都排名第一位,中國在過去五年一直排名第二位,後面是 一些其他國家,比如英國、德國、日本、韓國等。 但是中國的論文數量比其他幾個國家加起來都多,這說明了中美兩國遙遙領先的位置。
中美之間大概有每年 20 篇左右的論文數量差距,實際上只要有一個「漲停點」,中國就有可能跟美國並駕齊驅,甚至超越,這是指日可待的。
Q14:你認為,與其他國家相比,中國在人工智能方面的優勢與劣勢是什麼?
首先,政府有明確的綱要進行鼓勵,不論是投資還是政策都在鼓勵人工智能的發展。 然後中國有強烈的需求,我們有 7 億多網民,電子商務、搜索、辦公系統、雲服務,這些需求中國在社會上都是排名第一的。 再然後,有了這麼強的需求,就有很多的數據,也有很清晰的商業模型,就又會有越來越多的投資加入,越來越多的公司成立。 另外,大學的研究力量也在一點點增強。
中國有一個清晰的藍圖,又有很強的執行力,本身又有這麼強的需求。 在過去幾十年的發展中,包括網絡、雲、人才等基礎設施都齊備,所以我覺得我們是一個萬事俱備的狀態。 同時,也沒有人來掣肘,不像其他國家可能會有人有不同的意見,我們基本上是全國上下都在迎接人工智能時代的到來。 所以我相信,中國在人工智能領域能夠實現彎道超車,如願以償地達到世界頂級水平。
但與此同時我們也看到了一些顧慮。 比如第一,我們照比美國來講,頂尖人才的數量還是要少很多,我們通才比較多,比如編程人員、做系統的人員我們有很多,但是能夠提出先進理念思想、引領潮流、引領世界的 人才相對來講還很少。
另外我們的博士生,追隨的意願太強,很多人的目標就在於寫幾篇文章,能畢業就行。 我更希望我們的博士生引領的意願更強,可能一開始還沒有能力引領,只能追隨,但慢慢的,應該有自信心來引領這個世界。 必須有強大的信心驅使著我們,我們才能通過技術難關達到世界發展的頂點,這其中志向起到很大的作用。
雖然我們期待在學術理論上引領世界,但是回到現實,目前工業產品都是數據驅動的,也就是說誰有數據,誰就能第一時間建模,第一時間得到用戶反饋,然後快速迭代 自己的系統來滿足用戶的需求,所以說實際上,誰掌握場景、數據,誰就掌握了入門主動權。
目前各個行業都要數字化、智能化。 但咱們國家很多工業體系連數字化都沒有完全達到,在數據的採集、整理、建模方面還沒有達到很好的智能狀態,這裡有很多研究以及創業的機會。 就是說先不管理論突破,就算是能將現有的模型巧妙的用在各個領域,提升行業效率,對社會都是極大的貢獻。
比如交通、醫療、教育、司法、金融,這些行業背後有一堆數據,但這些數據要么沒有被及時存起來,要么存起來卻也找不到,要么就是沒把它建模,沒有使它的數據 潛能發揮出來。 所以這些領域只要把數據做好,加上人工智能的一些能力,就會極大的提高整個社會生產力的潛能,這個非常重要。 需要工業界的人和人工智能界的人共同努力,工業界要找到需求,人工智能界要將系統做成可實現、可無縫對接、可跟踪的東西,不要總是高高在上。
所以從這個意義上來說,場景加數據就是決勝之道,其他都是隨之可以沓來。
Q15:有說法認為,人工智能會拉大數字鴻溝,強者愈強,最終造成壟斷,你是否贊同?
我認為,先進國家、先進公司抱著盈利和實現自己社會使命感的目的,一定會將一些技術普惠到民間。 但是同時,有些大公司也會希望構建自己的技術壁壘。 但我個人認為,國家政策應該通過建立普惠制度極力消除這種鴻溝和壁壘。
現在很多技術沒有生態環境發展不起來,那麼為了要有這個生態環境,你就要把你的一些東西釋放出來,讓所有人受益,讓大家在你的基礎上發展新技術,整個生態環境才能起來 。 所以一個公司一家獨霸,什麼都做得好,不借鑒其他公司的任何東西,然後站在世界的製高點上,完全封閉,不開源,誰也不給用,直接壟斷,這種情況很難出現。
現在的形勢就是開源,你中有我,我中有你,社區互相貢獻,互相促進,共同發展。 當然,不排除有些國家經濟水平還沒有達到能夠跟上人工智能浪潮的程度,比如人員配置不足,基礎設施建設欠缺,那這些國家可能會在人工智能競爭中落在下方。
Q16:你怎樣看待人工智能與人類失業的關係?
我的看法還是很正面的。 第一,由於人工智能的進步,很多原來做不了的事情現在能夠實現了,最典型的是智慧城市。 以前你用一萬個人、一億個人也解決不了智慧城市的問題,它涉及到基礎設施、信號燈調配、車輛識別、調度與管理,沒有人工智能,這件事想都不敢去想。
智慧城市讓整個社會效率提高了,那麼人們就能有更多的時間去做更多的事情,比如以前你在車上堵一個小時才能到,現在半個小時就到了,那你就能做很多 新的事情,或者把原先的工作做得更好。 這說明了什麼,人工智能釋放了人類更多的潛力,節省了更多的時間,創造了新的機會。
第二,人工智能對現有職業有一定的衝擊,比如翻譯、新聞稿,類似這種任務人工智能能夠很好地完成。 但其實仔細想想,人工智能是將人類的需求充分的挖掘出來了。 就像翻譯,以前人們出國,很少有能帶得起翻譯的,現在有了語音翻譯這件事情,普通人也能有翻譯了。
還有寫稿,很多稿子都要求時效性,以前僱多少人也不一定能很好地滿足時效性,現在讓人工智能先很快地生成一個稿子,編輯人員檢查一下就能發稿了。 教學方面也是一樣,人工智能出題、改卷、減少了老師的工作負擔,使教育更加公平、個性化。 所以說人工智能對現有的人員沒有進行沖擊,反而提高了現有人員的工作效率和能力。
當然,有些情況下,比如客服,由於效率的提高,原來需要一百人,現在需要五十人。 但我認為,現在的客服大多數都是年輕人,他們整天回答枯燥的問題,還要笑臉相迎,承受很多壓力,人工智能能把這部分人解放出來,讓他們有自己的愛好,發展 新的職業道路,也是正面的。
所以整體來講,人工智能是會起到輔助人類,讓社會變得更美好的作用。
本文由 機器之能© 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接https://www.huxiu.com/article/233308.html