[導讀] 目前國外對助聽器研究發展的一個熱點則是集中在中國,確切地講是基於對漢語語言和語音研究,開發相關的語音識別技術和產品。 為中心的中文聽力學也不例外。 我們已經知道聽覺科學是一門發展迅速、知識更新很快的一門學科,它所研究的對像以人的聽覺為中心,現在我們將介紹和討論科學家和聽力學家更關心的是怎樣將聽覺 科學運用到中國人的聽覺和言語實際中去。
目前國外對助聽器研究發展的一個熱點則是集中在中國,確切地講是基於對漢語語言和語音研究,開發相關的語音識別技術和產品。 為中心的中文聽力學也不例外。 我們已經知道聽覺科學是一門發展迅速、知識更新很快的一門學科,它所研究的對像以人的聽覺為中心,現在我們將介紹和討論科學家和聽力學家更關心的是怎樣將聽覺 科學運用到中國人的聽覺和言語實際中去。
漢語是具有特徵化的音調性語言,與其他以拼音字母為主的語系,如斯拉夫語係等具有很明顯的語音學差別。 這種差別不僅僅在語言特徵上非常明確,在具體使用時,區別也很大。 是否不同語系的不同語音特徵會影響聽覺受損患者對言語的理解,尤其是在使用基於不同語系研究成果製作成的助聽器時,這種語音的差異是否起到重要作用,最近已成為學術和科研 的一個熱門課題。 比如國內研製的人工耳蝸的一個特點便是在設計其算法時考慮到中文語音特點。 國外助聽器廠商將在近期推出以中文語音為特徵算法的助聽器。 加拿大在中國的一語音實驗室通過多年的研究和實驗,早在 2000 年運用領先的數字信號處理 (DSP) 技術,在其數字助聽器中加入中文語音算法,並同時申請了相關專利。 目前他們率先推出的以中文語音處理技術為核心的全新數字助聽器 —Intelligia ,在臨床試驗中得到受試者的認可,初步證明這種新型助聽器對說以中文為母語的患者有益處。
目前研究的結果表明,不同的語系,如漢語和英語有各自特點,在聽覺感知過程中有很大差別。 英文和漢語在語音和口語上有重要區別, Ming-Xi Tsai el al ( 2000 )認為漢語和英文語音在結構上特徵區別很大。 漢語的詞、字、音節和聲、韻母分節含有不同層次的信息,並保持複雜的關係。 在口語中,漢語發音差異也很大,在不同會話條件下,受到這些結構中不同層次信息的影響。
對中文語音識別和中文語音音調的研究表現在人工耳蝸的算法上面。 言語處理策略是人工耳蝸幫助患者理解語言核心技術,已有大量研究。 但對於言語聲尤其是聲調、語調的研究,比如對以語調為基礎的漢語研究還是很少。 在最近的一個試驗中,他們用澳大利亞人工耳蝸來觀察對漢語語音理解的影響。 結果表明在某些言語處理策略中漢語的使用的理解度要高於其他時間策略。 如果能提高刺激率,加強對語音和音調的理解,他們也認為不同的言語處理策略對漢語說法也有理解。 研究再次證明,漢語應該有一定的語音系統處理自己的語言,尤其是對聽障人士尤為重要。
美國麻省理工學院研究者 Michael Qin 在其《在噪音背景發音和音調的辨認》的試驗中,對漢語普通話音調的辨認和噪音的關係進行了研究。 他認為不同的語言利用不同類型的聲調使我們口語富於不同的意義,在噪音環境下這些有意義的聲調會受到影響,因此他需要發現說普通話的中國人怎樣在噪音環境裡辨認不同的聲調 。 在試驗中他使用 6 個輔元音的音位,同時使用 4 個聲調:陰陽上去。 其結果表明在信噪比降低的情況下,對漢語聲調和元音的識別受到很大影響,從而影響降低言語的理解能力。 因此信噪比影響理解中文很重要的因素。 這個試驗對聽覺康復和設計有針對性的助聽器具有重要意義。
同時,最近美國成立了一個綜合性專家研究小組,開始研製適合中文語音的助聽器。 該小組成員包括世界聞名的豪斯耳研究院、香港中文大學耳鼻喉科等。 與上述研究類似。 他們認為在聆聽以聲調作為識別語音和語義的語言時,如普通話、廣東話和泰國語等,可能聽覺更重要的是依靠基頻相關的信息來理解語言,這是與別的語言不同的。 因此,在研製助聽器時,我們應該考慮到這些患者的語言特點。
當然,筆者最感興趣的是最近由威耳康研究基金(Wellcome Trust) 贊助的一項題為《中文普通話會話者在理解語言時比英文會話者用腦更多》的試驗,其目的是使用 影像技術來觀察和研究中文母語和英文母語說話者大腦出現的不同活動。 主持該項研究的心理學家索菲斯高特博士發現,當英語的受試者聽到英文時,其左顳葉變得異常活躍,研究者認為這個區是把言語聲組合在一起形成獨立 的字詞。 但是當中文受試者聽到普通話時,其左右顳葉同時活躍起來。 顯然,由於說不同語言的受試者用他們大腦的不同區域對不同語言的刺激進行解碼。 這對我們理解這些理論產生了很大的影響。 他們進一步認為中文受試者的左顳葉處理語音信號,而他們的右顳葉則處理聲調,同時產生意義。 言語聲是非常複雜的聲音,而正確理解言語傳遞的意思,在這種情況下,大腦會充分利用說話者抑揚頓挫的聲調來對其言語進行解碼,從而將口語變成有意義的信號。
大腦聽覺區域很容易受外部影響,而改變對聲音的分辯能力。 一旦聽覺受到損傷,必需進行康復,大腦需要重新連接和編碼。 大腦的可塑性是很強的。 了解大腦對不同語言的反應,可以有效地幫助聽覺患者重新恢復對語言的理解。 重要的是基於這些研究,我們可以清楚地看到研製出具有中文語音特徵的聽力康復設備。 記得在2002 年北京大學和中國殘聯成立言語聽覺中心的開幕式上,鄧樸方先生在發言中專門談到:他第一次聽說中文語音處理特徵對助聽器使用者的影響,他認為這是一個 重要課題,需做大量工作,而研製出以中文語音為特徵的聽覺康復設備將會有重要的意義。 根據國際確認的聽損發病率,中國有 10 %的人口,即一億三千萬人有不同程度聽力損失,因此,利用中文語音處理技術更有效地幫助聽殘患者俱有非常重要的作用。
一. 中文語音技術處理原理
中文語音處理策略的英文詞有 “Chinese speech processing strategy” 或 “Chinese speech recogni TI on”, ( 中文語音識別) 和“hearing aid algorithm” ( 助聽器算法) 等。其中, algorithm ,即“ 算法” 一詞使用較多,尤其涉及到數字助聽器的開發, “ 算法” 代表了某一特殊 技術的核心。 “ 算法” 可以被簡單地看作為實現某些特定信號處理功能的指令序列。中文語音特徵可以通過算法研究來形成的。數字信號處理器和算法構成了數字助聽器的DSP 線路。包含 多通道動態範圍壓縮、噪音衰減等處理,設計助聽器的算法的主要目標是利用中文語音處理技術,即使在不同的聽音環境中,須確保言語被聽見並聆聽舒適。同時,利用數字助聽器改善漢語 可懂度,使有聽力損失的中國患者能更容易地理解漢語。
漢語是聲調單字語言,聲調是漢語的重要語音特徵之一。 聲調特徵主要體現在嗓音基頻隨時間變化的模式上。 Eady 技術 (1982) 曾考察過聲調語言 — 漢語的基頻模式與重音語言 — 英語有什麼不同。 漢語的聲調在詞語中具有辯意作用,在生活實踐當中,大家也都能體會到聲調有助於我們聽懂別人的話,而“ 南腔北調” 常表示不易聽懂和不大好懂和不大好聽的 意思。
對於連續言語來說,長時間平均的正、負顫動因數,各種語言和男女發音人是差不多的。 只是負顫動總是比正顫動大,而且出現頻率也較高。 Eady 的測量結果表明,漢語的說話速度要比英語慢一些。 這可能是由於說漢語時,說話人要花更大的努力在每一個音節上來控制聲帶運動,也就是說聲調語言的音節喉運動控制有較大的語言學負荷,因而花的時間就多一些 。 結果就表現為說話慢一些。
因此,聲調信息主要存在於基頻隨時間的變化中,強度變化對聲調信息有補償作用,以及清輔音的存在與否對聲調清晰度是有一定的影響的。
1 原理(Principles)
本文介紹一種可應用於數字助聽器的提高漢語可懂度的語音處理方法,其目標是使以漢語為母語的聽殘人士能更容易地理解語言。 增強言語可懂度的思路來源於人們的實踐經驗。 回想一下,當你為使一個有聽力障礙的人更容易聽懂自己說話時所採用的方法:你不僅僅要提高音量,而且還要改變發音方式,說得更慢和更清晰。 一些研究表明清楚地讀無意義的語句,比在日常會話句子,大約能提高 17% 的單詞可懂度。 這裡所謂說得更清晰是指強調言語信號中的某些暗示,這些暗示有許多不同的形式,如特定音段的持續時間,元音的共振峰位置或者音素之間的過渡等。
不是所有人都會簡單地、方便地對聽力損失患者 “ 清楚地 ” 講話。 因此,我們要採用言語增強的方法就是在說話人和聽話人中間構造一個處理模型,該模型能強調並突出語句中的特定成分,使語句聽起來更清晰。
一切語音之所以能夠表達意義,是由於各個音之間存在區別。 這些區別產生於聲腔內部的器官和肌肉等活動決定的發音方法和發音部位的差異,同時又表現為語音的聲學特徵的差異。 本文提出的言語增強的方法正是通過對語音信號的重構來強化這些差異。 所謂重構是指對語音信號中不同性質的信號進行識別並有針對性地予以處理,強調其中對人的感知起作用的特徵,從而達到提高言語清晰度的目的。 該方法可以簡單地概括為:放大輔音、強調重音和突出聲調。
2 漢語語音信號的感知特點
2.1 聲調
聲調的調類。
聲調的感知。
主要依據基頻的變化。
聲調音高的變化對音長和音強都可能產生影響。
2.2 重音
輕重音的聲學特性。
與實際音強有密切關係,但並不相等。
還要受音色、音高和音長的製約。
感知特點:分辨輕重音時,音強往往並不是決定性因素。
1 )輔音放大 (Consonant Amplifica TI on)
言語知覺的心理實驗證實瞭如下特點:人在言語感知過程中,對語音信號載荷的關於發音方法和發音部位的分辨信息的知覺能力存在強弱差別。 總體上說,人對發音方法比對發音部位有更好的分辨能力。 而方法清晰度與輔音清晰度的關係很相近。 在漢語輔音的發音方法的知覺重要性中,存在清與濁、送氣與不送氣、摩擦與非摩擦的從強到弱的位次關係。 研究表明,相對加強輔音有助於改善語音清晰度。
Kates 描述了放大輔音的方法,圖1是其中被廣為採用的一種模型。 該系統把信號分解成幾個波段,在每個波段檢測短時譜形,根據譜形識別元音和輔音,對輔音則給予放大。 需要指出的是,杜利民等提出了漢語語音導引特徵的概念,從聲學信息計算檢測的角度為為漢語自動語音識別系統提供了一種輔助匹配結構。
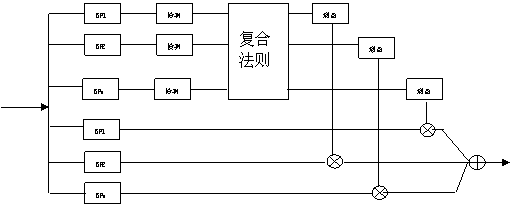
圖 1 輔音增強系統
2)重音(Stress)
組成一段語流的各音節聲音響亮程度並不完全相等。 有的音節在語流中聽起來聲音比其他音節響亮,這就是重音音節。 有的重音和語義、語法有密切關係,如漢語普通話中的詞重音。 詞重音出現在詞中,是由於詞的含義不同,重讀音節的位置也不同。 如 “ 技術 ” 和 “ 計數 ” ,重音分別在第一音節和第二音節。 這種語意的區別是通過 “ 超音段特徵 ” 來表達的。
在漢語中,重音對韻律特徵參數的影響倍受關注。 語流中 “ 韻律特徵 ” ( prosodic feature )是通過音高、音長和音強的變化,即 “ 超音段特徵 ” 表現出來。 從語圖上觀察,音域明顯擴張重音的特點。 高明明對普通話語句匯總強調重音的聲學表現進行了研究,指出:
( 1 ) “ 音高升高是普通話語句中強調重音的重要韻律特徵 ” 。
( 2 )音高和時長對於強調重音的實現具有同樣重要的作用。 它們之間的關係是對立互補的。
語音合成的經驗告訴我們,音高是調節重音最有效的手段,所以強化重音的方法主要是提高音高。
3) 聲調 (Tone and Interna TI on)
一個音節除了包括由元音和輔音按時間順序排列成系列的音質單位以外,還必須包括一定的音高、音強和音長。 在一些語言裡,音高在音節中起的作用可以說是和元音、輔音同樣重要,這種能區別音節的意義的音高就是 “ 聲調 ” 。 根據聲調的有無可以把世界上的語言分為聲調語言和非聲調語言兩大類。 漢、藏語系語言最突出的一個特點就是有聲調。
漢語普通話的聲調起著構詞辯意的作用。 對於具有相同拼音的一個音節,由於聲調不同,可以具有不同的含義。 普通話單音節的聲調變化共有四種模式,不同的聲調反映在語音參數上是基音頻率軌蹟的變化不同。 根據實驗觀察所定義的一些規則,可以認為基音頻率軌蹟的某一參數超越某一預先確定的門限時,則可判為某一聲調類型。 在此基礎上,黃澤鎮、楊行峻提出的識別模式採用基音軌跡曲線的一、二次斜率、谷點和平坦度對四種聲調有很強的區別性,實驗表明,這一算法的結果識別率可 達到99% 。
林茂燦指出聲調信息主要存在於主要元音(及其聲學過渡)上。 考慮到聲調音高的變化,對音長和音強都可能產生影響,即:去聲最短、最強,上聲最長,最弱,陰平和陽平舉重,陽平又往往比陰平略長一些。 聲調的增強不能簡單地對主要元音進行放大,而應該不同的聲調在音高和音強上有不同的處理。 實際應用中我們採取如下策略:
( 1 )對去聲增強音強。
( 2 )對上聲加大音長。
( 3 )對陰平和陽平不改變。
圖 3 展示的 4 條聲學曲線分別描述了四聲在不同時間裡的頻率特徵。

圖 3 漢語四聲的聲調聲學特徵
2. 方法 (Methodology)
數字助聽器的核心部分是增益計算,基於頻域的處理過程,它建立了各頻率段的輸入瞬時能量與增益的函數關係,如圖3所示,對每個頻段的瞬時能量進行短時能量累計 和長時間慢速平均可獲得信號識別和分類所必要的數據。 其中:
( 1 ) E j (n)= a E j (n-1) 式中: a 是時間常數 。
( 2 )使用倒譜算法提取基頻, 512 個點 FFT , 40ms 漢明窗,窗移為 10ms 。
( 3 )用一個簡單的滑動平均算法對每個音節測到的基頻進行平滑處理,剔除那些平滑段內偏離均值過大的值。
( 4 )音高和音長分別進行歸一化。
( 5 )採用一個二次曲線在最小均方誤差的意義下逼近基音軌跡。 併計算曲線的一次斜率、二次斜率、谷點和平坦度。
上述算法採用基於 TOCCATA 指令系統的彙編語言實現。 14 位 A/D ,採樣率設為 32KHz 。
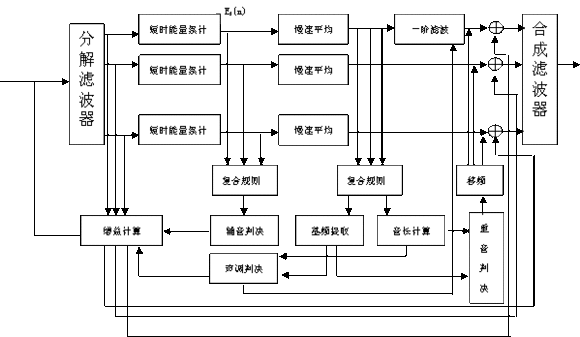
圖3 . 漢語言語增強系統處理結構圖
1). 語音的切分 (Classifica TI ons of Phonemes)
聲波由音質(即音色)、音高、音強和音長四部分組成,這四部分在語音中起著不同的作用,但在時間上又是同時並存的。
音質成分 —— 按音節劃分,如元音、輔音。
超音質成分 —— 由音高、音強和音長三部分組成,附著於一個音節或音段上。
從聲波特性上看,可以由基頻確定音高,根據振幅確定音強,根據時間確定音長。
2). 處理原理 (Algorithm Principles)
中文語音處理主要體現在:
在驗配過程的中,考慮中文語音長時間頻譜覆蓋的頻率作加權處理,抬高目標曲線中言語頻率的部分,可以達到加強語音理解的作用。
在助聽器的信號處理程序中,對壓縮控制器做特別的設置,使對高頻的信號壓縮的啟動時間和釋放時間很短, 做到使輔音清晰化的效果,增強使用者對言語的理解度 。
在降噪處理中,根據中文語音在噪音環境中的採樣分析,得出了為中文語音優化的降噪策略。 實驗證實,該策略最高可以提高信噪比 18dB 。
二. 中文語音處理技術在涉及助聽器的應用
下面是將中文語音技術應用到設計助聽器的具體實例。 這項技術採用了目前世界上最先進的 DSP 數字技術,包括低功耗的數字芯片。
1. TOCCATA數字信號處理系統
Toccata TM 系統是微型、超低功耗、高效率的數字信號處理系統。 它包括一個高保真加權疊加濾波器組( WOLA filter bank )、一個 16 位 DSP 核心、兩個 14 位 A/D 轉換器、一個 14 位 D/A 轉換器和其它外圍設備。 Toccata TM 技術提供標準的軟件可編程的 DSP 開發平台和採用 0.18 μ 工藝製造的微型超大規模集成電路。 它不但為音頻處理系統製造商也為其它基於 DSP 的微型、低功耗產品的開發提供了便利。
1.1硬件結構(Hardware Structure)
圖4 硬件系統結構圖

TOCCATA 系統由三塊芯片組成,一個 “ 模擬 ” 芯片( ALPHA ),一個 “ 數字 ” 芯片( DELTA ),和一個用於無電存儲的 E 2 PROM 芯片。
1.2 ALPHA芯片
ALPHA 芯片包括輸入和輸出放大器,二個 A/D 轉換器,一個 D/A 轉換器,以及主時鐘及供電系統。
1.3 DELTA芯片
DELTA 芯片包括了 16 位軟件可編程 DSP 核心,一個 WOLA 濾波器組協處理器,一個 DMA 控制器(輸入輸出處理器或 IOP )和存儲器( RAM 和 ROM )。 可編程核心和靈活的濾波器的組合允許通過軟件改變信號的處理方式。 因而,該結構可以執行傳統的音頻處理系統處理方案(例如雙通道壓縮),當然通過DSP 核心,也可以執行更強大的處理方案(例如16 通道乃至更多通道的壓縮,降噪,抑制反饋等 )。
1.4 DSP核心和指令系統(DSP Core)
RCORE 是一個靈活的 DSP 核心,採用帶單週期連乘累加操作和 40 位累加器的雙哈佛結構。 外圍組件通過一個由擴展寄存器、存儲器映像寄存器和共享存儲器組成的複合體提供。
1.5 信號路徑
圖5 . Toccata 系統提供的信號路徑:

2 Intelligia數字助聽器結構
Intelligia 全數字助聽器是基於上述介紹的芯片的技術特點設計的,其結構可由圖 6 表明。 儘管同模擬助聽器一樣,數字助聽器也使用麥克風和接收器作為能量轉換器,但在數字信號處理器中經 A/D 採樣後,電平信號已被轉化為數字編碼。 數字編碼能夠非常靈活地被加以利用來提供增益、改善頻響,或按患者聽力的要求作其它處理。 當 DSP 算法完成後,數字編碼又被 D/A 轉換為電平信號,並經由接收器轉換為聲音。
數字助聽器的關鍵在於具有信息處理系統,這里以一款基於現進數字信號處理系統 Toccata TM ,開發出的全數字助聽器 Intelligia ,具有獨特的中文語音處理功能。 助聽器在設計中將信號分解成16 個波段濾波處理,再將16 個波段的信號組成10 組通道,每個通道獨立使用輸入自動增益控制方法(AGCi) ,對信號進行壓縮處理,每個通道使用 快慢兩個時間偵測器,快速時間偵測器用以監視信號較快的變化,而慢速時間偵測器偵測較慢的信號變化,也就是音節的變化,並且選用與中文語音變化相匹配 的壓縮、釋放時間常數,達到更好的聽覺效果。
全數碼助聽器技術特點:
1)中文語音信號處理
深入研究中文和其他聲調語言的發聲特徵後,我們把獨創的中文語音處理的技術置入 ,使它能大大提高在中文語言環境中聽音的可懂度。
2)更快
採用專為數字助聽器設計的第 3 代數字助聽器處理系統 TOCCATA ,它強大的運算能力使能快速處理各種語音信號。
3)更省電
工作電流不足 1 毫安,並且它能在無信號輸入時自動進入省電模式,如此低的能耗免去配戴者經常更換電池之苦。
4)完全可編程
通過其可編程的優點為聽障者配置最適合的聽力補償程序和參數,從而保證配戴者可以獲得最佳的聽音效果。
5)多通道獨立壓縮
把外界的聲音按頻率細分成多個波段和通道,並對每個波段和通道的信號進行不同的處理,從而保證配戴者聽到更清晰、更逼真的聲音。
6)降噪處理
能有效地抑制環境噪音,提高辨別語言的能力,從而保證配戴者無論是在嘈雜的大街還是在喧鬧的超市都能聽到清晰的聲音。
7)方向性處理
可配置一個方向性麥克風系統和相應的軟件,能使降噪的效果更好,從而保證配戴者聽到更清晰、更自然的聲音。
8)聲反饋抑制
助聽器在使用過程中容易引起嘯叫,這種現象即聲反饋。 採用了聲反饋抑制技術,能有效地抑制聲反饋的出現,使配戴者聽到更為舒適的聲音。
9)可輕鬆升級
由於採用全開放的數字信號處理( DSP )平台TOCCATA 技術,提供了可編程的能力,具有充分的適應性以及升級能力,因此,配戴者只要採用我們的軟件,就可以立刻享受到最新的功能 。 下面是這款中文語音處理的技術指標對比 :
表 1 中文語音技術處理助聽器和其它助聽器的技術比較
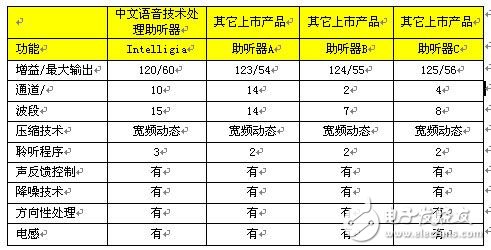
在實驗室中,具有中文言語增強方法的數字助聽器 ,初步實驗的結果表明,中文語音處理技術的運用,可幫助以漢語為母語的患者更好地理解語言,提高康復水平。 在臨床使用中,佩帶 Intelligia 助聽器的病人感覺效果很好,尤其在噪聲環境中,增強了語音清晰度。 從某種意義上講,病人感到理解語言的能力得到提高。 當然,我們必須意識到中文語音處理技術在全數碼助聽器中的運用仍處在早期研究階段。 筆者認為聽力學科學家和助聽器專家應從下列幾方面作更深入的研究:
應對以英文和漢語為基礎的語音處理技術作深入的對比研究,尤其是在噪音環境中,觀察兩種技術分別對兩種語音不同處理的效果。 最理想的實驗條件應是利用有雙語能力的受試者參加。
將中文語音處理技術和目前使用的非線性助聽器驗配法結合研究,觀察以英文為基礎制定的驗配方法,是否在中文語音處理技術支持下,更有效地幫助以漢語為母語的患者在日常 生活中提高言語理解能力。
中文語音處理技術目前是人機對話的研究熱門之一,其算法複雜多樣,我們應該更深入地研究具有中文特色的助聽器技術算法,充分發揮數碼芯片的巨大潛力。
將中文語音處理技術運用到聽力器設備中去才剛剛開始,這是一項非常複雜、涉及許多尚未解決的技術問題的課題。 但是,筆者認為只有開發出具有漢語語音特色的助聽器,才能更有效地幫助眾多的以漢語為母語的聽殘者。